HCL Accelerate 2.1 の新機能: 自動化されたルールベースのゲートを使用したパイプラインガバナンス
2020/10/1 - 読み終える時間: ~1 分
Pipeline Governance with Automated Rule Based Gates, new in HCL Accelerate 2.1 の翻訳版です。
HCL Accelerate 2.1 の新機能: 自動化されたルールベースのゲートを使用したパイプラインガバナンス
2020年9月30日
著者: Bryant Schuck / Product Manager for HCL Software DevOps

バリューストリーム管理と聞くと、メトリクス、主要業績評価指標(KPI)、可視性を思い浮かべるかもしれませんが、HCL Accelerate は2.1 のリリースでそれをさらに向上させています。
2.0 では、ユーザーが手動でバージョンを承認または拒否することができる単一の場所を提供していましたが、エクスペリエンスを向上させることができることがわかっていました。そこで私たちは、DevOps データレイクとデータの深い複雑な関係を活用して、セキュリティルールと品質ルールを導入することで、ゲートを迅速に強化しました。
多くの開発チームにとってパイプラインは、CI/CD ツールがバラバラでプロセスが複雑なワイルドウェストであり、情報が失われる可能性のある領域を生み出しています。例えば、計画されていなかった Pull Request が、実際にはリリースの最終ビルドに含まれていたという状況があるかもしれません。その場合、この小さな変更が壊滅的な脆弱性をもたらしていた可能性があります。作業項目がなかったため、誰も変更が入るとは予想していなかったので、手遅れになる前に誰も戻ってセキュリティ脆弱性の結果をチェックしなかったのです。
これらは、私たちのほとんどが夜も眠れない原因となっています。さらに悪いのは、ツールでレポートをチェックしたり、他の部署に連絡したり、回答を待ったりするためにリリースを遅らせなければならない場合です。より速く、より良い品質を実現する唯一の方法は、プロセスを自動化することです。自動化されたルールベースのゲーティングでできることに飛び込んでみましょう。
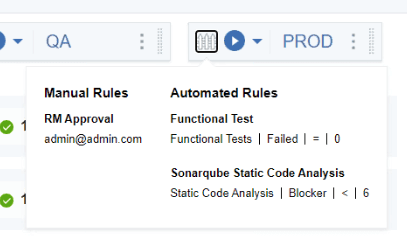
まず最初に気づくのは、新しいルールが2.0の手動ルールをベースにしていることです。多くのお客様がBETAモードでこれを使用してきました。彼らは、すべてのツールを HCL Accelerate に接続していませんでしたが、手動ルールを使用して、どのツールが必要で、いつ接続できるかという目標を設定することから始めていました。アプリケーション・セキュリティ・スキャン・ツールを探しているのであれば、AppScan を強くお勧めします。
自動化されたルールは、コードカバレッジ、機能テスト、ユニットテスト、アプリケーションの脆弱性、コンテナの脆弱性、静的コード解析など、HCL Accelerate でおなじみのあらゆる種類のメトリクスをチェックすることができます。最も良い点は、これらが設定されると、バージョンに関連付けられたデータを完全に自動分析して実行するため、基準を満たさない限り、どのバージョンもこれらのゲートを通過しないことを信頼できるということです。しかし、心配しないでください - 私たちはすべてのコードを出荷しなければならなかったので、常に「確かですか?」という回避策がありますが、それは監査報告書にキャプチャされます。この機能は、実際には、チームが完全な自律性を持って顧客にできるだけ早くリリースできるようにするためのチェックとバランスを整えることです。 「自分はブロッカーが 0 であると言ったけど、あの時、自分は本当に正しいビルドを見ていたのか」などということを、徹夜して言い出すことがなくなります。
いつものように、質問があれば私や私のチームの誰にでも連絡してください。デモをお見せして、HCL Accelerate とバリュー・ストリーム・マネジメントがどのようにしてチームがタスクに集中することをやめ、より多くの価値を提供できるかをお見せしたいと思っています。
Accelerrate: データ駆動型 DevOps パート 2: データ駆動型の文化
2020/9/30 - 読み終える時間: 2 分
data-driven-DevOps%e2%80%afpart-2-data-driven-culture の翻訳版です。
データ駆動型 DevOps パート 2: データ駆動型の文化
2020年9月29日
著者: Steve Boone / HCL Software DevOps Head of Product Management
シリーズのパート1を読むにはここをクリックしてください。
堅固な文化は、どのような DevOps 組織にとっても非常に重要です。DevOps 文化の主要な特徴は、開発チームと運用チーム間のコラボレーションを強化し、サポートするアプリケーションの健全性と健全性に対する責任感を共有することです。これは、開発、IT/オペレーション、および「ビジネス」を横断する透明性、コミュニケーション、およびコラボレーションを高めることを意味します。職場内の文化的規範は、優先順位、コラボレーションの方法、問題解決のアプローチに関して意見の相違につながることがよくあります。特に最終的な目標や価値が誰にとっても明らかでない場合は、DevOps 文化は新しい働き方を採用するのに苦労することがあります。
このような文化の移行を容易にするにはどうすればよいのでしょうか?それはデータです。データは、チーム間の知識の公平性を提供することで最大の効果を発揮します。理想的には、優れたデータがあればあるほど、より良い知識を得ることができます。この新しい知識があれば、より効果的に仕事をし、より明確にコミュニケーションを取り、最終的には組織としての働き方を改善するために行動を起こすことができるようになります。つまり、データは、人々が互いに協力し、協力し合う方法を劇的に改善することができるのです。
カルチャーを改善したい場合、どのようなデータを調べればよいのでしょうか?手をつけるべき場所には事欠かないが、HCL Software DevOps での経験から、私たちは開発者、デザイナー、アーキテクトなど、個々の貢献者にとって最も馴染みのあるデータから始める傾向がある。これは通常、ソース・コントロール管理や、課題追跡やプロジェクト管理に関連するデータ(ソースの例としては、Atlassian、JIRA、Gitなどがあります)から来るデータです。
これらのツールから得られるデータからは、多くの分野の洞察が得られます。まず、コードをコミットし、コードの変更をビジネス価値のある特定の項目に関連付ける際に、チームメンバーが使用し、最もよく知っているプロセスを示します。これにより、日々の活動をよりよく理解し、改善点を見つけることができます。また、このデータを使用して、作業中のアプリケーションを特定したり、多くの場合、作業のタイプ(例えば、欠陥と機能)を特定することもできます。このデータは、特定のチーム全体の仕事の分布についての有用な洞察を引き出すために使用することができ、 チームがどのように連携して仕事をしているかを示すことができます。
個々の貢献者から得られるデータを調べることで、以下の7つの主要な分野で文化を改善することができます。
-
誰が何に取り組んでいるか? 誰が何に取り組んでいるか? 誰がどのような作業をしているかを知ることは、優先順位に変更があった場合や要件が変更された場合に備えて、開発マネージャやチームの残りの部分を常に把握しておくのに役立ちます。
-
何か重要なものが取り残されていないか? 進行中の作業を特定することができれば、そのリストをビジネスゴールや成果物のリストとクロスリファレンスすることができます。これにより、「やるべきことに取り組んでいるか」という質問に、より明確に答えられるようになり、時間通りに終わらないかもしれない項目を特定したり、優先順位をつけずに行われている作業を見つけることができます。
-
誰が助けを必要としているのか? 遠隔地で働くスタッフが増えた今、手を挙げて助けを求めるのは難しい。多くの場合、最も優秀な従業員は、彼らの皿の上にあまりにも多くの仕事を抱えてしまうことになります。データを見ることで、仕事を完遂するのに苦労している貢献者を特定し、必要な助けを得ることができます。また、このデータは、時折行われる消防訓練で少し余力のある人を見つけるのにも役立ちます。
-
チームが日々の活動をどのように行うかを改善する。 どのプロセスにも改善の余地があります。より明確なデータがあれば、開発チームが使用しているシステムとどのように相互作用しているかを評価することができ、コードレビューからテストツール、バックログの項目のトリアージまで、ビジネス価値をより効率的に流すことができないボトルネックを明確にすることができます。
-
チームの速度を特定することで、計画を改善する。 進行中の作業を特定することで、どのような作業が完了したかを把握することができます。これにより、チームのベロシティを把握することができ、特定のスプリントやリリースに何をコミットできるかを容易に把握することができます。
-
スプリント/リリースのスコープがより良くなります。 リリースやスプリントに何をコミットできるかを知ることで、チーム全体がより個人的に責任を持ち、達成された仕事に「納得」するようになります。チームは、短い時間枠の中で過剰な成果を求められていると感じることが少なくなります。
-
予定外の仕事を識別する。 計画外の作業は、時間通りに納品されないビジネス価値の最大のサイレントキラーです。チームがどのような開発努力をしているかを分析することで、そのデータを見て、計画的な作業と計画外の作業のどちらが多いかを判断し、計画外の作業の影響を最小限に抑えるための是正措置を取ることができます。
これらの分野に共通しているのは、開発チーム全体のコラボレーションとコミュニケーションの改善に焦点を当てていることです。個々の貢献者が自分に何が期待されているのかを知り、目標が明確に定義されている場合、貢献者はより積極的に参加し、日々の活動に価値を見出し、成功する可能性が高くなることがわかります。
データは非常に個人レベルでも支援する能力を持っています。DevOps Institute の 2020 Upskilling: Enterprise DevOps Skills Report の調査結果によると、DevOps 人材の採用を検討している企業では、新規採用の要件として「ヒューマンスキル」が上位にランクインしています。上位に挙げられたヒューマンスキルの1位は何だったのでしょうか?コラボレーションと協調性、次いで共有と知識の伝達、そして適応性、共感性。これらのヒューマンスキルはすべて、DevOps 文化がデータを受け入れることで成長させることができます。
DevOps Institute のレポートから得られた重要な調査結果の1つは、雇用主が「E字型」のスキルセットを持つ潜在的な候補者を見つけたいと考えていることでした。I字型、T字型、E字型のスキルセットについてよく知らない方は、下の図をご覧ください。I型スキルセットはスペシャリストです。彼らの知識は、一つのテーマについて非常に深いものです。T型のプロファイルは、特定の領域の専門家でありながら、ビジネス全体に関する幅広い一般的な知識を持っています。このため、機能横断的なチームとの連携を得意とし、より広い戦略をまとめる上で優位に立つことができます。E型スキルセットは、さらに一歩進んだものです。このような人材は、プロセスやフレームワークのスキルの専門知識だけでなく、幅広いヒューマンスキルを持っており、自動化の経験、新しいアイデアを探求する能力、高いレベルで実行する能力を備えています。
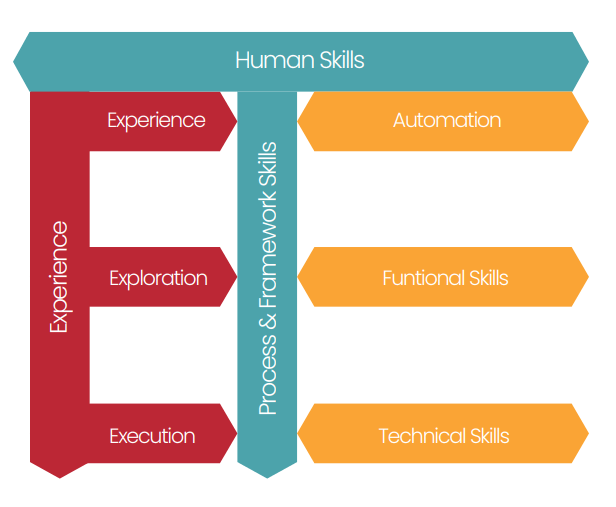
出典: DevOps インスティテュート
データは、個人が通常の役割以外の仕事に触れることで、「T字型」のスキルセットがより「E字型」の未来へと成長するのを支援する上で重要な役割を果たすことができる。このような経験は、共感を生み出し、積極的な DevOps 文化に不可欠な責任感を共有する感覚を高めるのに役立ちます。自分のコントロール外に存在する課題を他者が理解できるようにすることで、組織が真の意味で DevOps を受け入れるために必要な健全な対話を始めることができます。
データは DevOps に変革的なメリットをもたらす可能性があります。次回は、データがどのようにして組織がより効果的に作業を追跡し、計画を立てるのに役立つかについて説明します。最後までお読みいただきありがとうございました。
Accelerrate: データ駆動型 DevOps パート 1: 序章
2020/9/29 - 読み終える時間: ~1 分
Data-Driven DevOps Part 1: An Introduction の翻訳版です。
データ駆動型 DevOps パート 1: 序章
2020年9月28日
著者: Steve Boone / HCL Software DevOps Head of Product Management
ソフトウェア開発の専門家が DevOps について議論するとき、多くの場合、人、プロセス、テクノロジーを中心とした3つの主要な会話が形成されます。これら3つのコンセプトは、DevOps の核心を語るものです。
人」のトピックは、コラボレーションと責任の共有をサポートする健全な文化を構築することに焦点を当てています。プロセスについて議論する場合、会話は特定のワークフローをいかに効率的にできるかに傾く傾向があります。DevOpsのテクノロジーの側面は、ソフトウェア開発における近代化、セキュリティの脆弱性、品質保証、自動化、その他多くの要因に至るまで、常に変化し続ける会話です。私たちは、何がうまくいき、何がうまくいかないかを判断するために、このような会話をしています。私たちは、これらの会話を DevOps が生み出す貴重なフィードバックサイクルの一部として受け入れ、日々の責任を改善する方法を学べます。
すでに DevOps の旅を始めている組織にとって、このような会話は日常生活の一部となっています。振り返りから計画会議まで、1週間を通していくつかの会議が行われますが、これらはすべて、組織全体がこれまでの行動から学び、より良い計画立案の支援に焦点を当てています。これらの会議は、組織のさまざまな部分がそれぞれの意図を共有し、より効果的に協力し、高品質のソフトウェアをリリースするために必要なすべての可動部分をよりよく理解するための素晴らしい方法です。この種の会議の欠点は、主に個人的な経験に基づいていることです。会話に参加している人は皆、自分の視点、自分の主張を示すためのデータ、そして(おそらく最も重要なのは)自分の感情を持ってきます。このため、全員の意見を一致させ、同じ目標に向かう努力は非常に困難です。それはまた構成のある部分にグループの残りの部分より競争の優先順位があれば職場内の分裂を作成できます。
バリューストリームマネジメント (VSM) は、このような継続的な議論から生じる多くの課題を解決できる DevOps のプラクティスとして位置づけられています。VSM の基本的な概念の中で、組織は、機能を市場に投入するために必要なアイデアから納品までのすべてのステップをよりよく理解できます。VSM は、組織のプロセスをマッピングするというコンセプトに基づいています。これには、貢献しているすべての主要なビジネスユニット(設計、開発、製品管理、リリースエンジニア、品質保証、セキュリティなど)と協力して、現在のビジネスがどのように運営されているかを正直に表現し、改善すべき領域を見つけることを目的としています。マッピングはプロセス全体を全体的に見るための素晴らしい方法ですが、ひとつの重要な要素が欠けています。
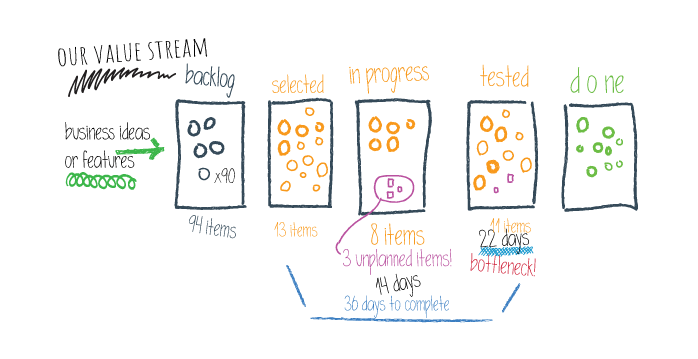
バリューストリームから生み出されるデータを収集・分析することで、あらゆるチームが直面する古くからの疑問の謎を解き明かす鍵を握っています。どこを改善できるのか?何がうまくいっているのか?何がうまくいっていないのか?データ自体は懐中電灯のような役割を果たし、組織が実際にどのように日々運営されているのか、有用な洞察を照らし出せます。これは、我々はプロアクティブに反応していることから会話をシフトすることができることを意味します。 反応的な会話は、ほとんどの場合、問題を理解し、何が問題を引き起こしたのかを理解し、最終的に問題の解決策を議論することに費やされます。プロアクティブな会話は、グループがリアルタイムで何が起こっているかを見ることができるときに行われます。リアルタイムのデータは、問題を予測し、痛みが現実になる前に解決策を実行に移すことを可能にします。データに基づいた会話をすることで、問題がどこにあるのか、より重要なのはなぜ問題なのかを関係者全員が明確にできるため、問題解決をより迅速に行うことができます。
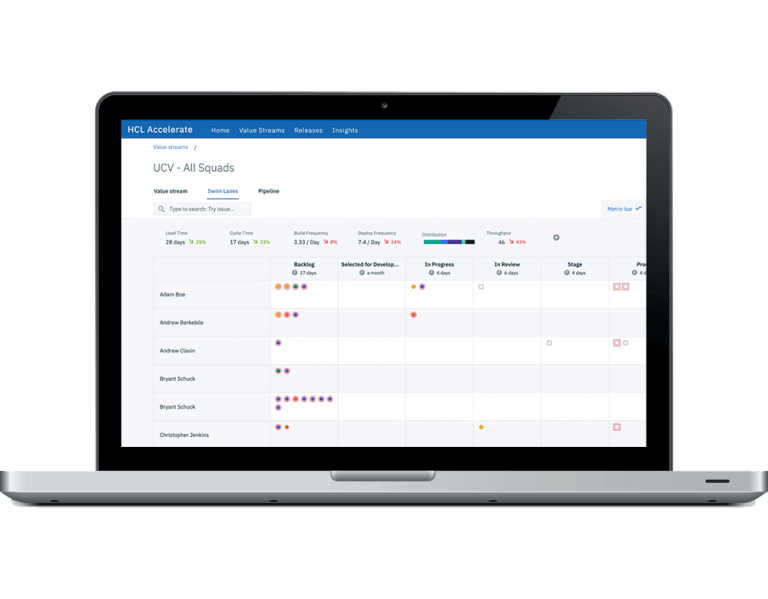
HCL Accelerate のSwim Lanes ビューでは、チームの仕事の全体像を把握できます。
このブログシリーズでは、データが組織内で果たす重要な役割について見ていきます。特にコアとなる「影響を与える領域」と、データがどのようにDevOpsの主要な会話に影響を与えることができるかに焦点を当ててみたいと思います。
- 人: データを通じたDevOpsの人間化
- プロセス: データを使ったトラッキングとプランニング
- テクノロジー: データ主導のビジネス・アジリティ
データに基づいて DevOps イニシアチブを推進することは、最終的には、個々の貢献者の努力がビジネス目標と明確に一致するような、より共感性の高い DevOps 組織を育てることにつながり、プロダクト・マネージャーは、何がデリバリーのために計画されているのか、何がリスクであり、何を残す必要があるのかを利害関係者や顧客に簡単に伝えることができるようになります。データを DevOps の目標の最前線に持ってくることで、組織全体として、リスク、コスト、収益をより良く管理することができるようになります。 データ駆動型の DevOps とバリュー・ストリーム管理が、組織におけるDevOpsの話を変え、効果的な変化を実感できるようにするために役立つ多くの方法を、今後数週間にわたってご紹介していきます。
HCL Accelerate VSM を Jenkins と組み合わせて使用する - パート 2
2020/9/16 - 読み終える時間: 7 分
第一回目の記事「HCL Accelerate: GitHub と Jira と組み合わせた HCL Accelerate Value Stream Management」の第二回目、HCL Accelerate VSM with Jenkins – Part 2 の翻訳版です。
HCL Accelerate VSM を Jenkins と組み合わせて使用する - パート 2
2020年9月16日
著者: Daniel Trowbridge / Technical Lead
このチュートリアルでは、HCL Accelerate パイプラインからパラメトリックなJenkinsジョブを設定してデプロイする方法を説明します。
前提条件
- HCL Accelerate との Jenkins 統合の完了
- HCL Accelerate VSM を Jenkins と組み合わせて使用する - パート 1 の完了
- GitHub と Jira と組み合わせた HCL Accelerate Value Stream Management の完了を推奨しますが、必須ではありません。
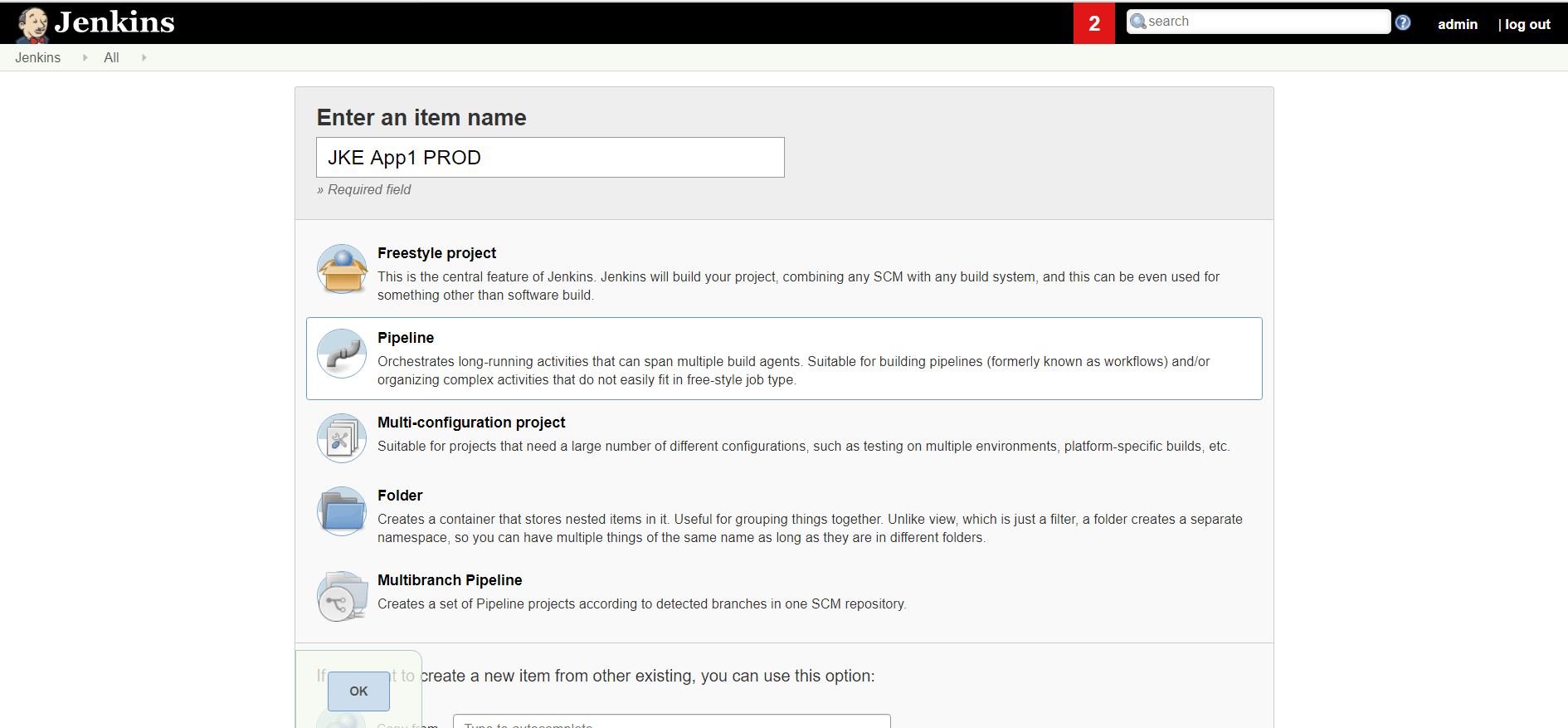
1. PRODデプロイ用のJenkinsジョブを作成する
1.1 新しいパイプラインジョブの作成
今回は架空のプロダクションまたは「PROD」環境へのデプロイ用に、2つ目のパイプラインジョブを作成します。
1.2 パイプラインスクリプトの設定
以下のスクリプトをコピーしてパイプラインスクリプトとして貼り付けます。Build、DEV、QAで使用したスクリプトに似ています - PROD スクリプトには、"Download attributes for API" json ファイルから取得しなければならない2つの変数値があります。このファイルは、HCL Accelerate バリューストリームのツールアイコンからダウンロードできます。スクリプトをコピー&ペーストし、正しい変数値を提供したら、Jenkins で「適用」と「保存」をクリックします。
| 変数名 | 内容 | 例 |
|---|---|---|
| VSM_ENV_ID_PROD | バリューストリームの PROD 環境を一意に識別するID | 7a115f90-f4e5-4181-9920-78b216bb4afc |
| VSM_APP_NAME | HCL Accelerate パイプライン・アプリケーション名(ワークブックには「JKE App1」を使用し、後でこのパイプライン・アプリケーションを作成します) | JKE App1 |
parameters([
string(name: 'buildNumber', description: 'The version of the application to deploy.')
])
node {
//Get value for VSM_ENV_ID_PROD from HCL Accelerate VSM "Download attributes from API" json file.
def VSM_ENV_ID_PROD="0e9ea7c7-ed1d-43f2-9ebf-a5ab5161d61e"
//VSM_APP_NAME must match your HCL Accelerate pipeline application name
def VSM_APP_NAME="JKE App1"
currentBuild.displayName = "${buildNumber}"
stage ("Deploy to PROD") {
step([$class: 'UploadDeployment',
//"versionExtId" can be used in place of "id" and "versionName"
id: "${currentBuild.displayName}",
versionName: "${currentBuild.displayName}",
name: "${currentBuild.displayName}",
description: 'UploadBuild Example',
tenantId: "5ade13625558f2c6688d15ce",
initiator: "admin",
//Must specify one of "appId", "appExtId", or "appName"
appName: "${VSM_APP_NAME}",
environmentName: 'PROD',
environmentId: "${VSM_ENV_ID_PROD}",
result: "${currentBuild.currentResult}".toLowerCase(),
startTime: "${currentBuild.startTimeInMillis}",
endTime: "${System.currentTimeMillis()}",
type: "Jenkins",
debug: false,
fatal: false,
])
}
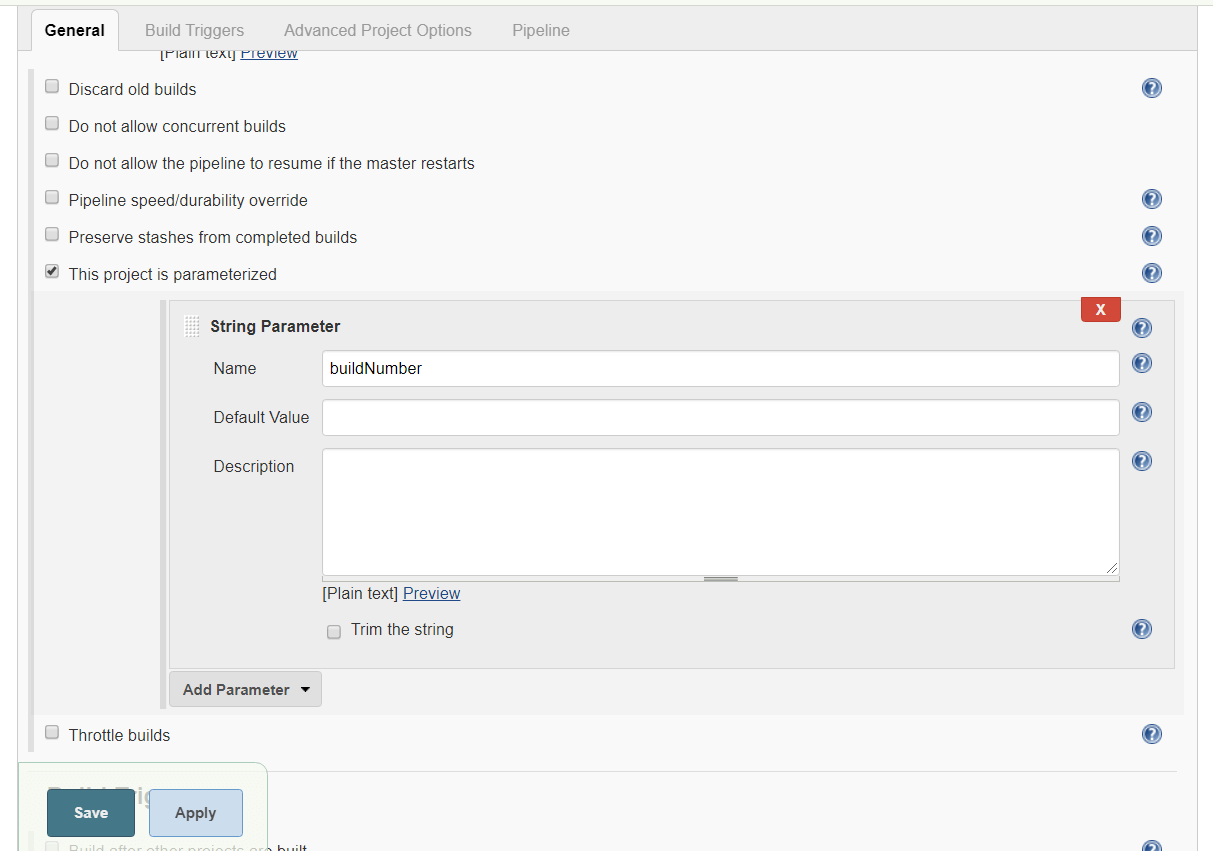
}1.3 ジョブをパラメータ化する
パイプラインジョブを「buildNumber」という文字列パラメータでパラメータ化します。Apply をクリックして Save をクリックします。
2. HCL Accelerate パイプラインのセットアップ
PROD のデプロイメントは、DEV や QA のデプロイメントを設定するのとは少し違った方法で設定します。このチュートリアルでは、パイプラインにバージョンを提供する入力ジョブ(以前のビルドまたはディプロイメント)を設定します。パイプラインには、Jenkin ジョブにビルド番号を渡すパラメータ化された PROD ディプロイメントも含まれます。パイプラインに利用可能な入力バージョンを確認し、このバージョンをPROD環境にデプロイすることができるようになります。
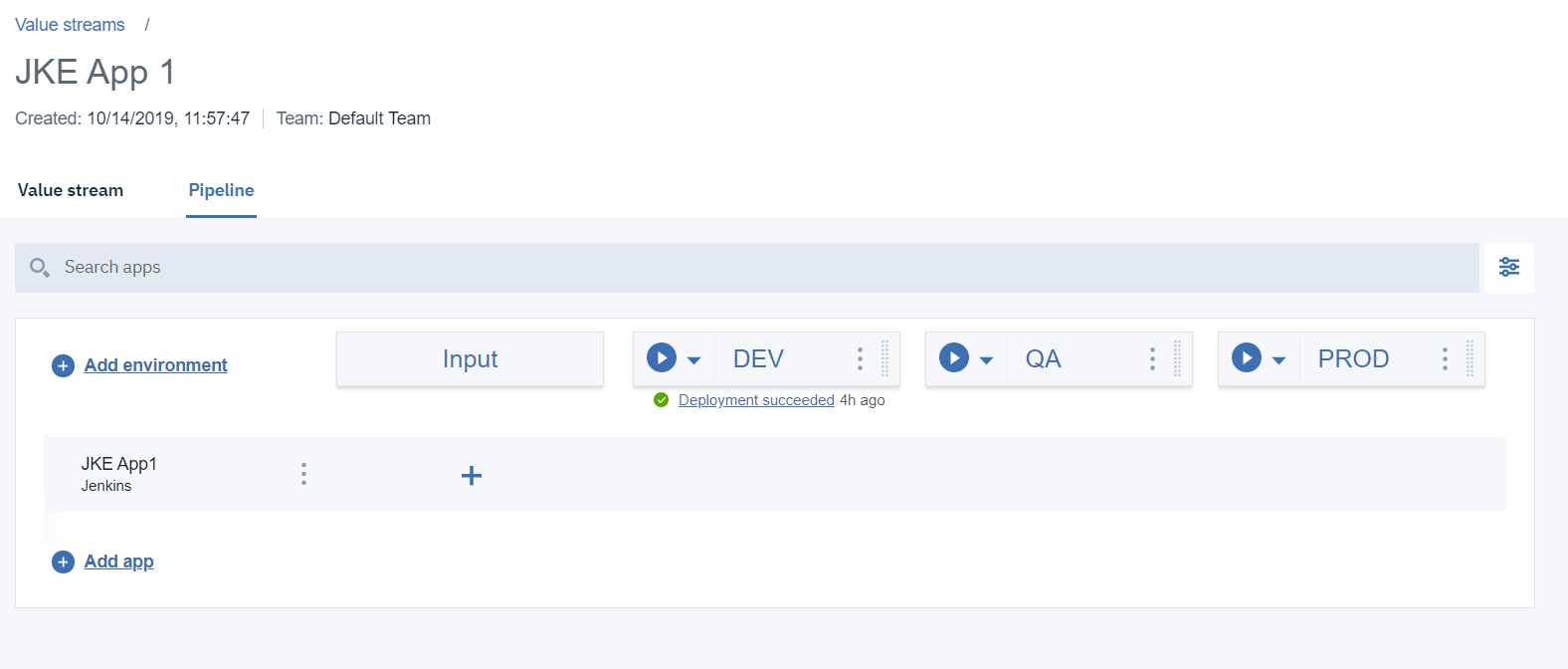
2.1 入力ジョブを構成する
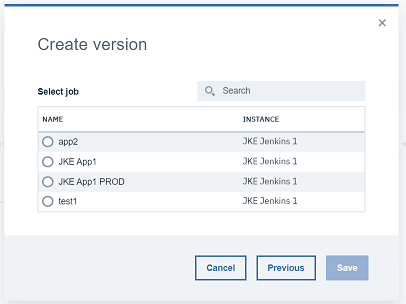
2.1.1 パイプラインから、関心のあるアプリケーション(この例では「JKE App1」)の「Input」の下の「+」をクリックします。
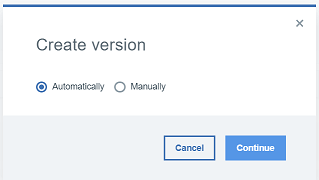
2.1.2 "Create Version "フォームで "Automatically "を選択し、ビルドを生成するJenkinsジョブを選択します。このチュートリアルでは、以前に作成した Build, DEV, QA Jenkins ジョブを使用します。
2.2 PRODの配置を設定する
PRODにデプロイするJenkinsジョブをPROD用のHCL Accelerateパイプライン環境に割り当てる(マップする)必要があります。また、ビルド番号にパイプラインパラメータを使用するように、このジョブを設定する必要があります。
2.2.1 パイプラインから、対象のアプリケーション(この例では「JKE App1」)の「PROD」の下の「+」をクリックします。
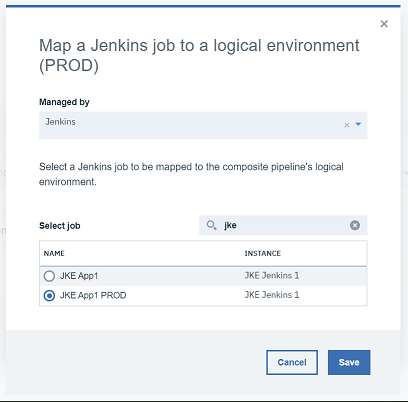
2.2.2 PRODにデプロイするために作成したジョブを選択し、「保存」をクリックします。
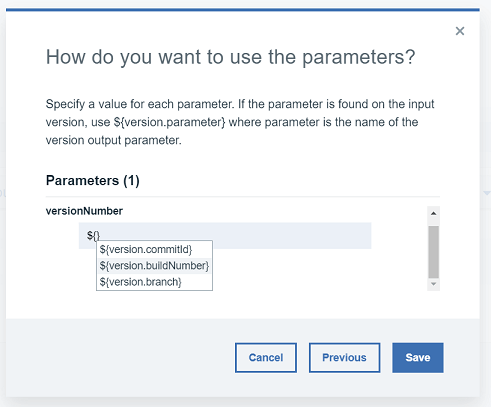
2.2.3 ビルドをデプロイメントにリンクさせるために、Jenkins ジョブのパラメータとして buildNumber を渡します。パラメータを使用してジョブを構成したので、この時点でパラメータを提供するように求められます。HCL Accelerateは、流動的なパイプラインをサポートするために、様々なバージョン/インベントリーのパラメータを用意しています。この場合、${version.buildNumber} をフォームに入力します。
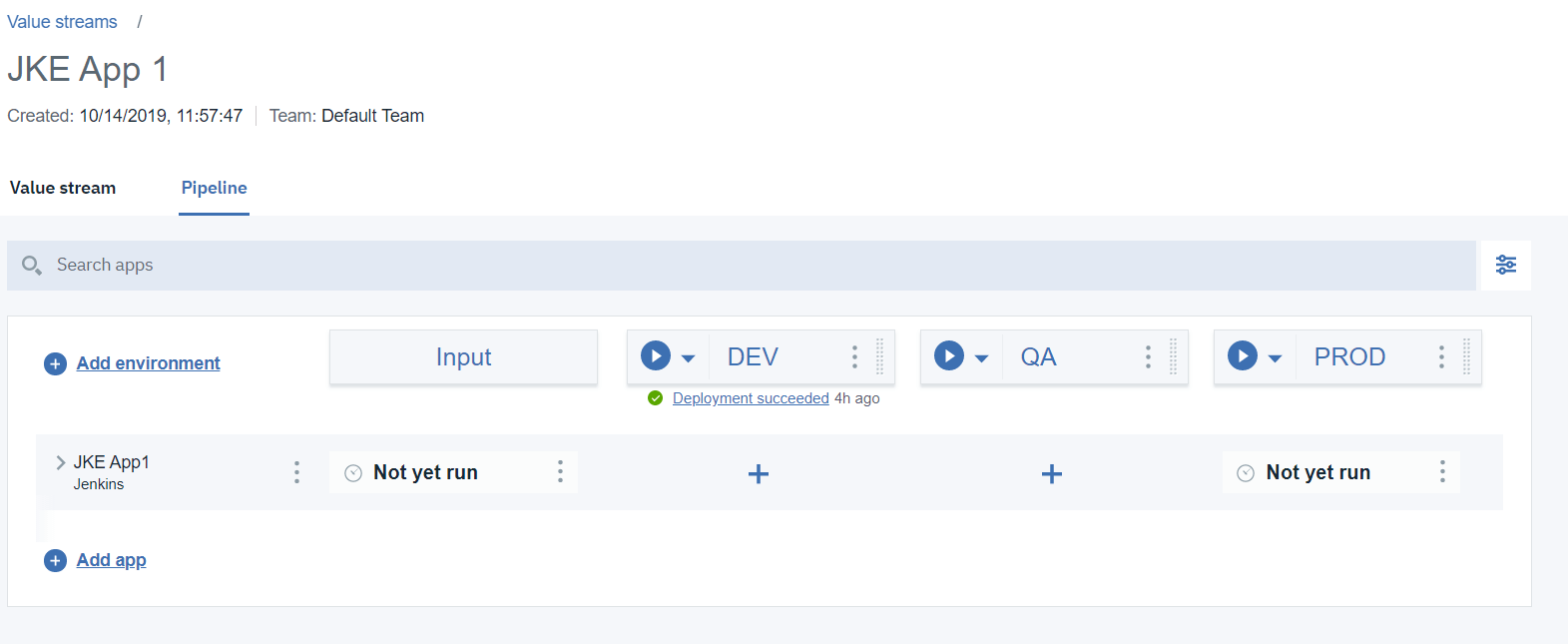
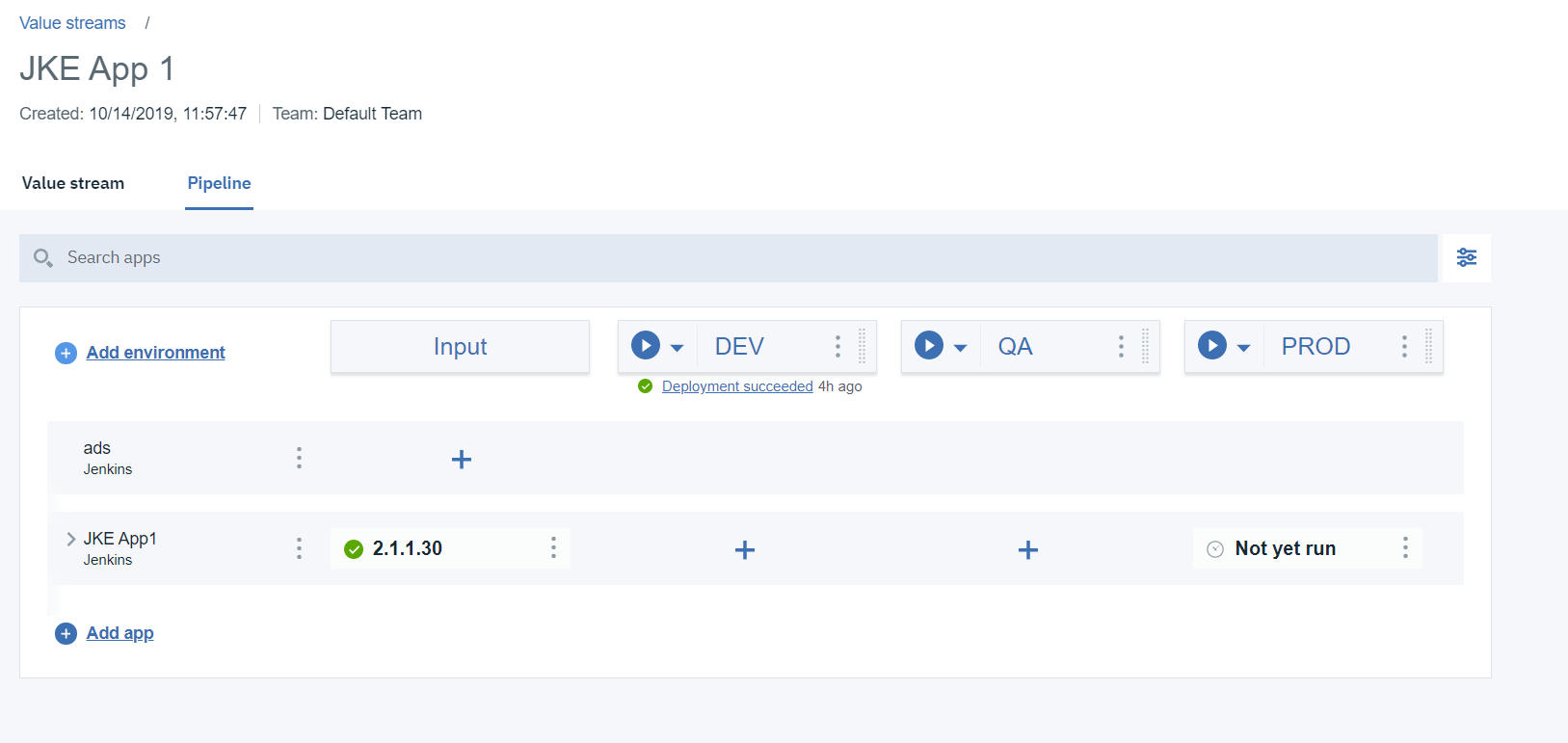
これで、「入力」と「PROD」の両方の列の下に「まだ実行していない」と表示されるはずです。先に進み、HCL Accelerate に新しいビルド情報を提供するための最初の Jenkins ジョブ (入力ジョブ) を実行します。入力ジョブを実行すると、バージョン情報が表示されるはずです。
- Jenkins ジョブを実行する前に
- Jenkins ジョブを実行した後
3. ファイナルステージから PROD への変更
3.1 PROD へのパイプライン展開
3.1.1 HCL Accelerate パイプラインから、PROD の「Play」ボタンをクリックします。
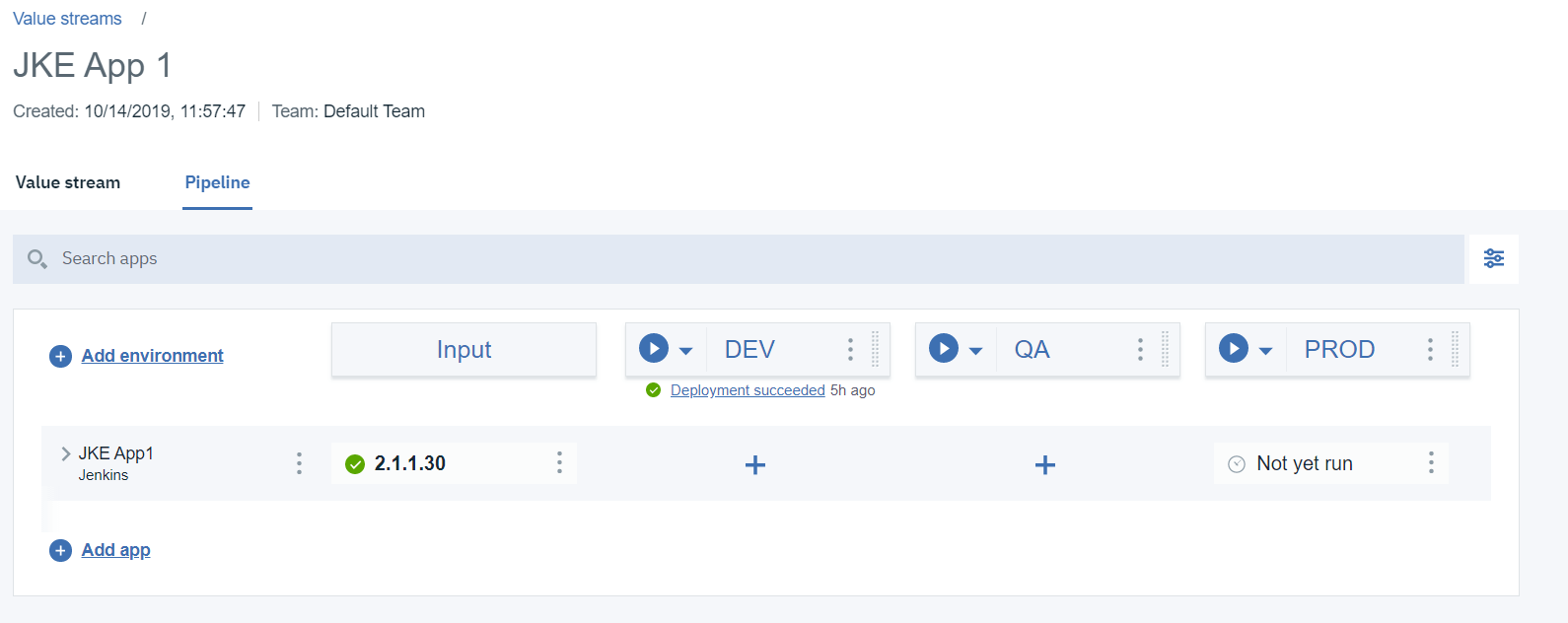
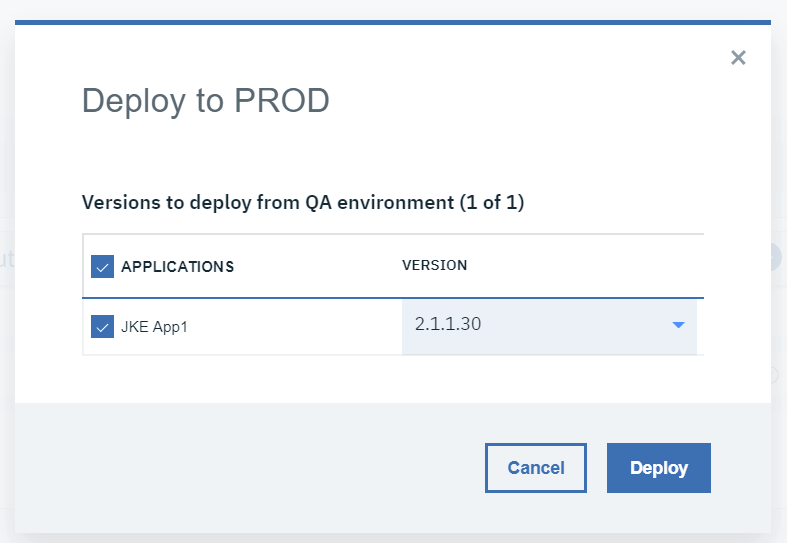
3.1.2 最新版を選択して「デプロイ」をクリックします。これで、先ほど作成したパラメータ化されたJenkinsジョブが起動します。
3.1.3 ジョブが終了すると、パイプラインはバージョン番号とともに「Deployment succeeded」と表示されます。
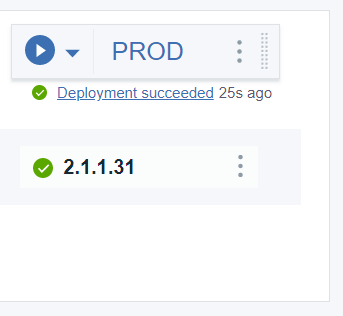
価値の流れに戻る
バリューストリームに戻ると、ドットが最終段階であるPRODに向かって移動するのを見ることができます。
結論
これで、Jira、GitHub、Jenkinsのチュートリアルシリーズを終了します。私たちは、バックログから本番までのバリューストリームの旅全体をナビゲートし、途中で4つの別々のツールを使用しました:3つの外部ツール(Jira、GitHub、Jenkins)、そしてデプロイメントツールとしてのHCL Accelerate自体です。私たちは、ステージクエリ、統合、リンクルールを持つvsm.jsonファイル、パイプラインとデプロイメントなど、HCL Accelerateの主要な概念について学びました。ここから戻って、バリュー・ストリームの実験を始めることができます。手始めに、vsm.jsonファイルのステージとクエリを見ることから始めるのが良いでしょう。そこから、独自のプロセスに合わせてバリューストリームを形成し始めることができます。
HCL Accelerate: 市場はバリュー・ストリーム・マネジメントについてどのように考えているのか
2020/9/16 - 読み終える時間: 2 分
Survey says...here's what the market really thinks of Value Stream Management
市場はバリュー・ストリーム・マネジメントについてどのように考えているのか
2020年9月15日
著者: Elise Yahner / HCL
バリューストリーム管理は、DevOps のソートリーダー、トレードショー、出版物などで話題になっていますが、ソフトウェア開発の専門家は VSM についてどのように考えているのでしょうか?これは、SD Times と提携してバリュー・ストリーム・マネジメント市場調査を行った際に、私たちが知りたかったことです。
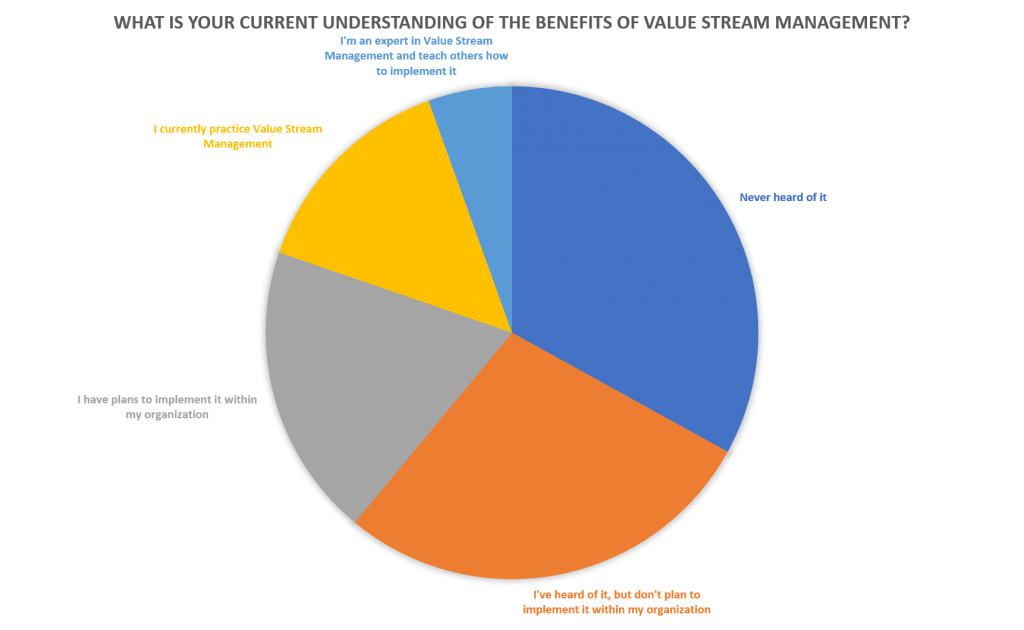
SD Times は何百人もの読者を対象に、「バリュー・ストリーム管理のメリットについての現在の理解度はどうですか?結果は、VSMの認知度と採用はゆっくりと着実に進んでいますが、VSMを使用している人はすでに恩恵を受けていることを示しています。
最近、SD Times の編集長である Dave Rubinstein 氏は、ポッドキャストの中で、HCL Software DevOps の製品管理責任者である Steve Boone とこの調査について語りました。Boone によると、バリューストリームマネジメントは、VSM のアーリーアダプターと VSM のことを聞いたことがない人との間で、「交差する」地点にあると考えているとのことです。データはこれと一致しています。調査回答者の 3 分の 1 は、バリュー・ストリーム・マネジメントについて聞いたことがないと答えていますが、39%は VSM を導入する予定があるか、すでに VSM を実践していると答えています。
では、どうやって業界をその溝を越えさせるのか?教育とトレーニングです。「このソリューションには明らかに価値があるので、そのキャズムを越えて、一般的に採用が増えるまで、そう長くはかからないと思います。業界としては、人々にベストプラクティスを教育し、VSM がもたらしたデータを使って何か意味のあることをする方法を教えることが鍵となります」と Boone は指摘しました。
そのデータは、しばしばバラバラな DevOps ツールに隠されていますが、VSM の成功のハイライトとなっています。「ソフトウェア開発には、サイロ化されている部分がまだあり、組織の他の部分の人間が必ずしも見たり、洞察を得たり、行動に移すことができません。調査回答者の大多数が、「ソフトウェアデリバリパイプライン全体で進行中の作業の可視性が向上したこと」が、VSM の最も価値ある側面であると答えていることは、驚くに値しません」と Rubinstein 氏は述べています。
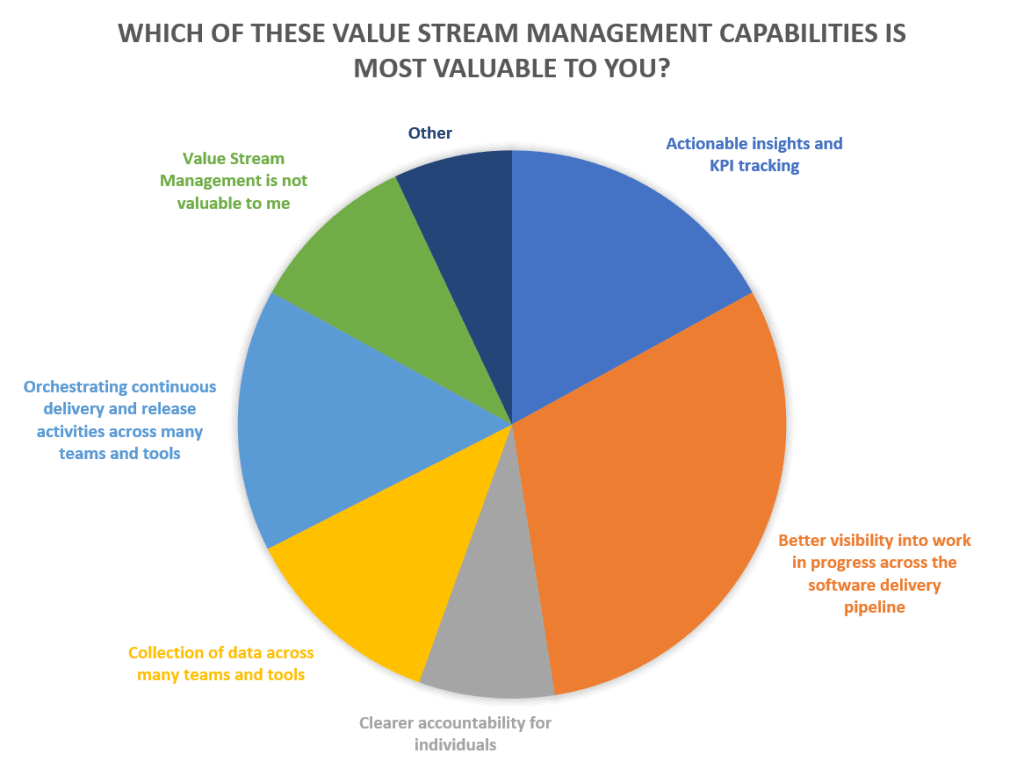
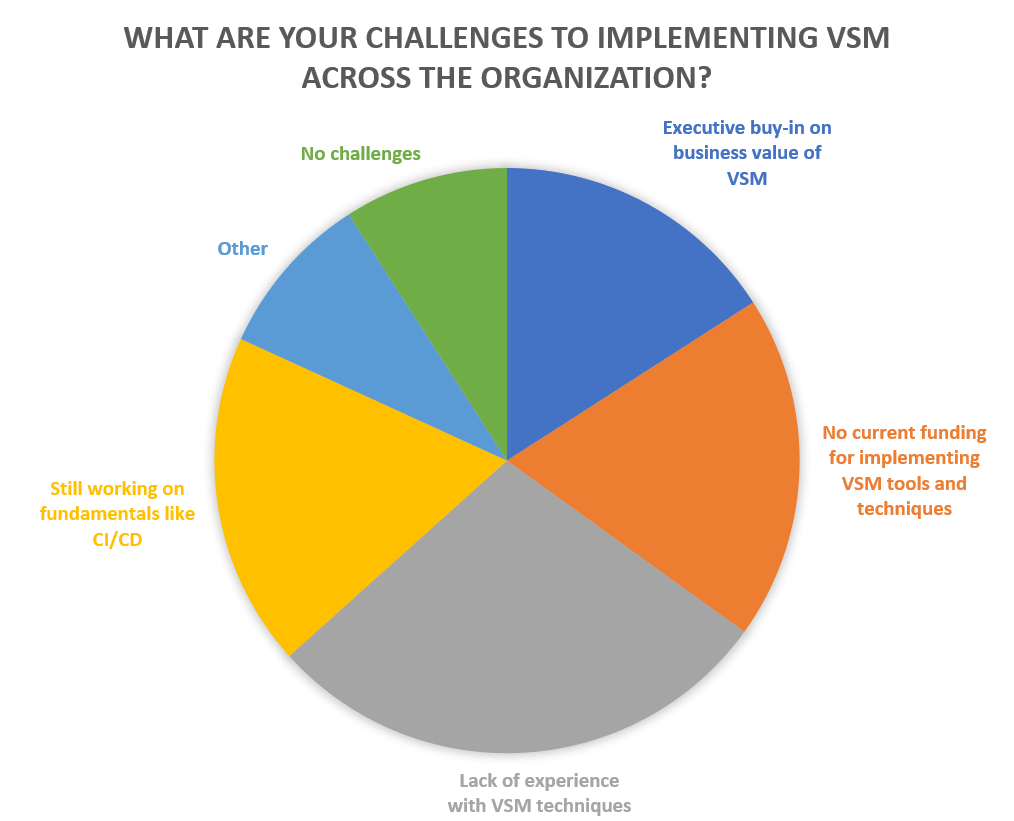
バリュー・ストリーム・マネジメントのあらゆる利点にもかかわらず、組織的、教育的な課題が VSM への参入を阻んでいます。調査回答者が挙げた課題のトップは経験の不足であり、資金調達や経営陣の協力が挙げられています。
しかし、Boone は「現在のプロセスについて、長く正直に振り返る必要があります」と述べ、VSM を始めるための最良の第一歩は、チームとの会話だとしています。「アイデアはどのようにしてバックログに入るのでしょうか?それが最終的にバックログから設計や計画の段階に移るのはいつですか?どのようにしてスプリントに入るのでしょうか?データはツールに隠されていますが、お互いの作業関係も理解しなければなりません」。
9月24日(木)午後3時(東部標準時)に開催されるパネルウェビナーでは、SD TimesのVSM調査結果について詳しくご紹介します。ウェビナーでは、SD Times の Dave Rubinstein 氏が、HCL Software DevOpsのエキスパートである Steve Boone、Chris Nowak、Bryant Schuck とバリューストリームマネジメント市場について議論します。登録はこちらをクリックしてください。
HCL Accelerate VSM を Jenkins と組み合わせて使用する - パート 1
2020/9/15 - 読み終える時間: 10 分
HCL Accelerate はバリューチェーン管理を行うソフトウェアです。ソフトウェア開発で要となる Jenkins との連携の実際を解説する記事 HCL Accelerate VSM with Jenkins – Part 1 の翻訳版です。
HCL Accelerate VSM を Jenkins と組み合わせて使用する - パート 1
2020年9月14日
著者: Daniel Trowbridge / Technical Lead
このチュートリアルでは、HCL Accelerate でビルドデータとデプロイデータをアップロードするための Jenkins パイプラインジョブを作成する方法を紹介します。これは、Jira と GitHub を使った HCL Accelerate VSM シリーズの一部ですが、単体でも一般的なリファレンスとして使用できます。
要件: Jira と GitHub を使用した HCL Accelerate VSM チュートリアルシリーズの事前完了を前提としていますが、完全に必須ではありません。
1. Jenkins インテグレーションを作成する
「HCL Accelerate を使った Jenkins インテグレーションの作成」のチュートリアルに従ってください。
2. バリューストリームに Jenkins インテグレーションを追加する
Jenkins の統合は、他の統合とは異なる方法でバリューストリームに追加されます。vms.json ファイルを編集する必要はありませんが、ビルドデータとデプロイデータのターゲットを持つために、バリューストリームのパイプライン上に「アプリ」を作成する必要があります。
2.1 「パイプライン」に移動し、「アプリの追加」をクリックします。
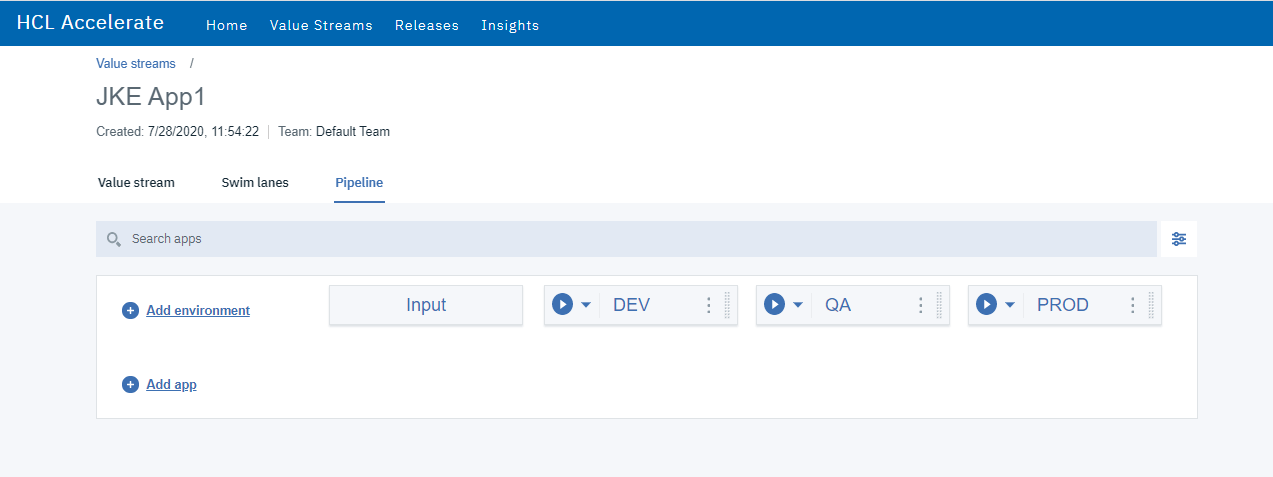
2.2 ドロップダウンから「Jenkins」を選択します。
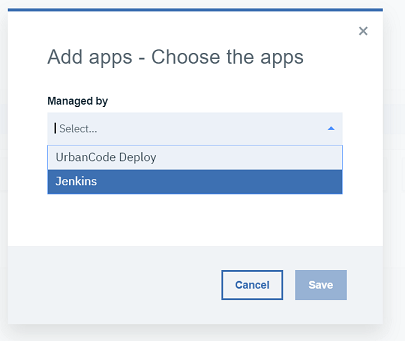
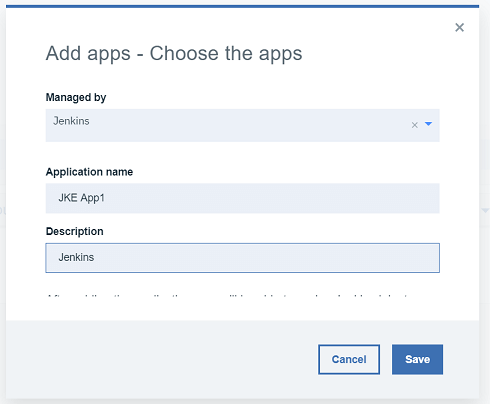
2.3 アプリケーション名を入力します。ワークブックでは「JKE App1」という名前を使用します。
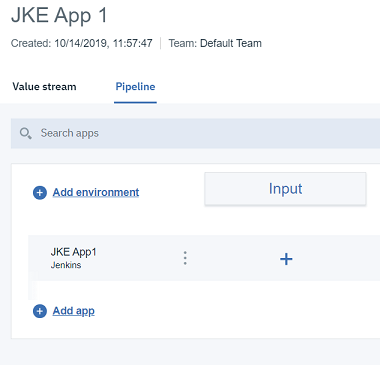
2.4 新しいアプリケーションがパイプライン内の行として表示されるはずです。今のところ必要なのはこれだけで、値のストリームに戻ることができます。
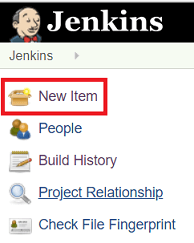
3. ビルド、DEV、QA用の Jenkins ジョブを作成する
3.1 新しい Jenkins Pipeline Jobを作成する
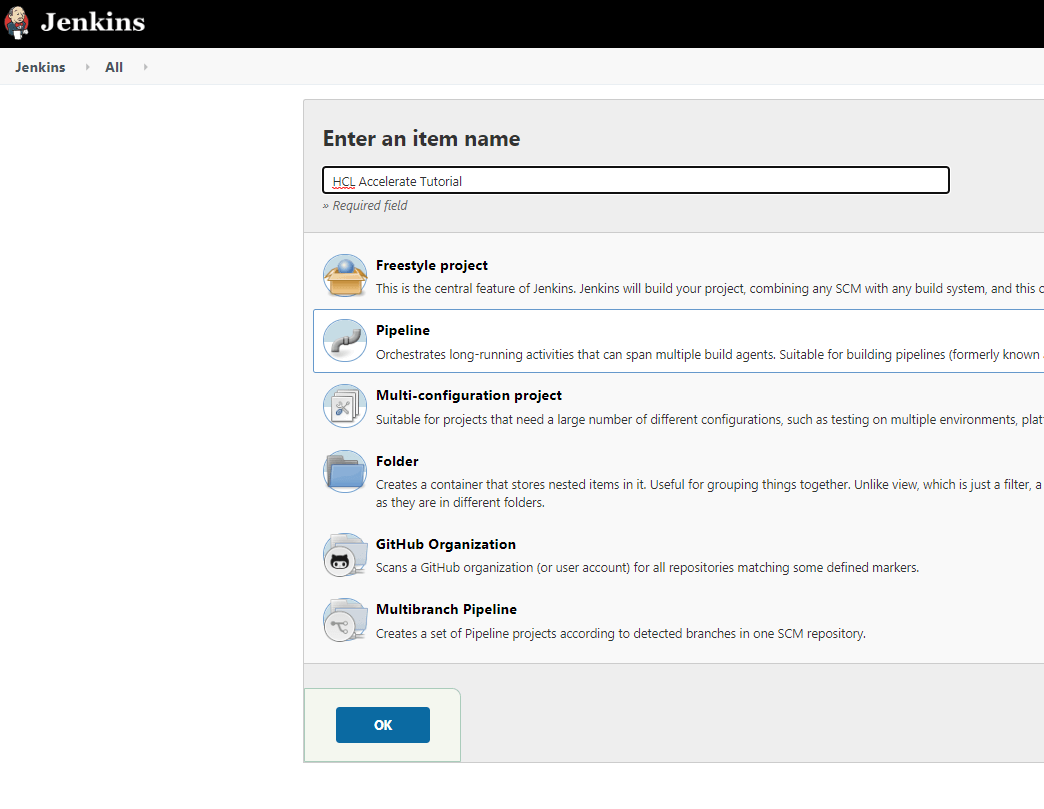
3.2 パイプラインスクリプトの設定
パイプラインを作成したら、パイプラインスクリプトのセクションに移動します。スクリプトを貼り付け、変数値を設定した後、「適用」「保存」をクリックします。
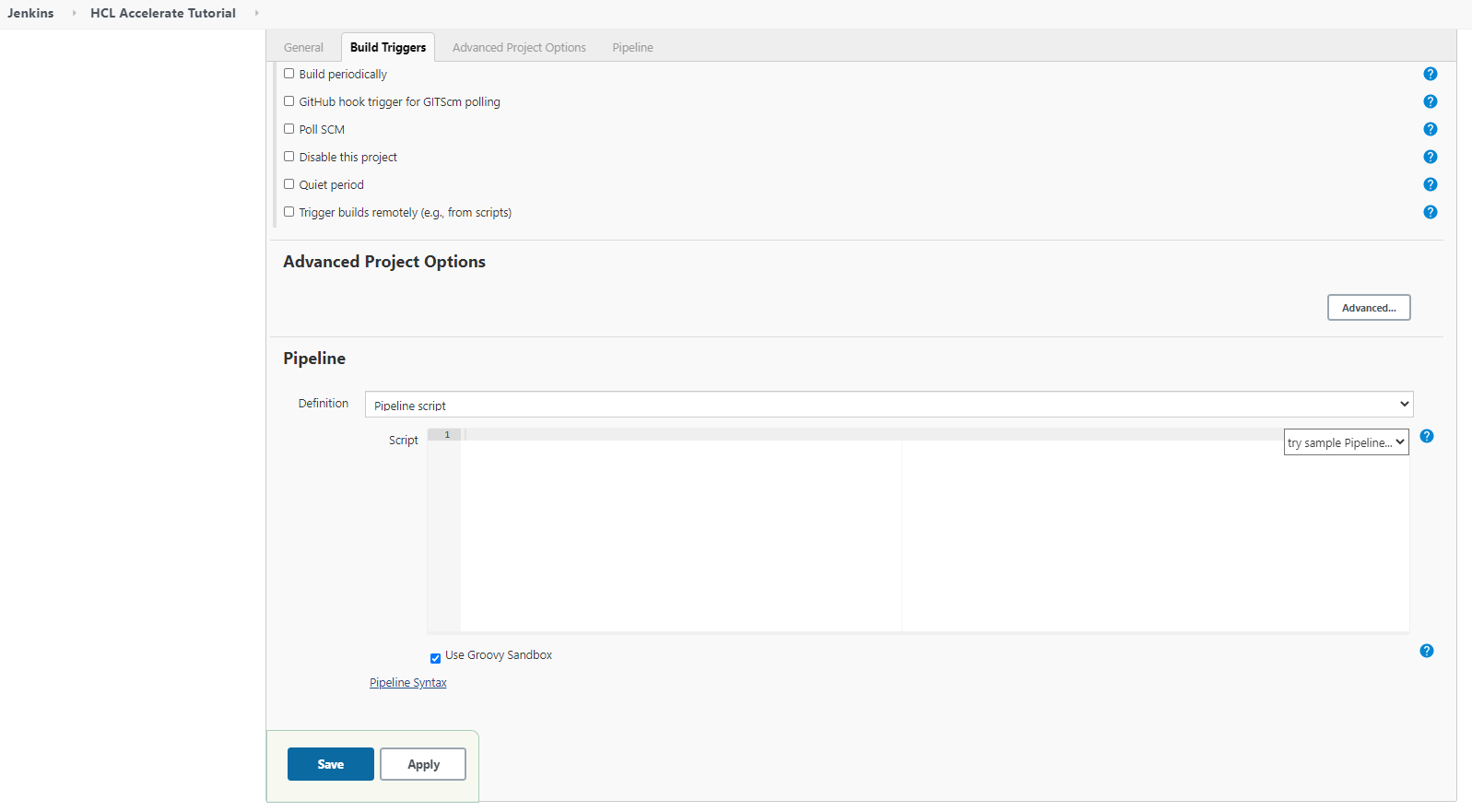
- ここにスクリプトをコピー&ペーストします。
- 変数を正しい値に設定する
- 適用」をクリックし、「保存」をクリックします。
3.2.1 スクリプトのコピーと貼り付け
node {
// URL to Github repository https://github.com/<owner>/<repo>
def GITHUB_REPO_URL="https://github.com/User1098429748/jke-app-1"
// Get ENV ID values for DEV and QA from HCL Accelerate Value Stream "Download attributes from API" json file
def VSM_ENV_ID_DEV="09bd6385-6b46-4fd1-a0b2-56cb0f4ecaf9"
def VSM_ENV_ID_QA="cf601828-3001-433c-bedd-f4574c5cc5f0"
// VSM_APP_NAME must match your HCL Accelerate pipeline application name
def VSM_APP_NAME="JKE App1"
// Time to wait before next stage (seconds)
def SLEEP_TIME=5
// Do not change below this line.
def GIT_COMMIT
stage ('cloning the repository'){
currentBuild.displayName = "2.1.1.${BUILD_NUMBER}"
majorVersion="${BUILD_NUMBER}"
def scm = git branch: 'master', url: "${GITHUB_REPO_URL}"
GIT_COMMIT = sh(returnStdout: true, script: "git rev-parse HEAD").trim()
echo "GIT_COMMIT=${GIT_COMMIT}"
}
sh 'printenv'
stage ("Build") {
echo "Building ${VSM_APP_NAME} (Build:${currentBuild.displayName}, GIT_COMMIT:${GIT_COMMIT}, comit2:${env.GIT_COMMIT}, name:${env.GIT_COMMITTER_NAME})"
step($class: 'UploadBuild',
id: "${currentBuild.displayName}",
versionName:"${currentBuild.displayName}",
name: "${currentBuild.displayName}",
tenantId: "5ade13625558f2c6688d15ce",
requestor: 'admin',
//Must specify one of "appId", "appExtId", or "appName"
appName: "${VSM_APP_NAME}",
revision: "${GIT_COMMIT}",
status: "${currentBuild.currentResult}".toLowerCase(),
startTime: "${currentBuild.startTimeInMillis}",
endTime: "${System.currentTimeMillis()}",
debug: false,
fatal: false,
)
}
stage ("Deploy to DEV") {
sleep "${SLEEP_TIME}"
step([$class: 'UploadDeployment',
//"versionExtId" can be used in place of "id" and "versionName"
id: "${currentBuild.displayName}",
versionName: "${currentBuild.displayName}",
name: "${currentBuild.displayName}",
description: 'UploadBuild Example',
tenantId: "5ade13625558f2c6688d15ce",
initiator: "admin",
//Must specify one of "appId", "appExtId", or "appName"
appName: "${VSM_APP_NAME}",
environmentName: 'PROD',
environmentId: "${VSM_ENV_ID_DEV}",
result: "${currentBuild.currentResult}".toLowerCase(),
startTime: "${currentBuild.startTimeInMillis}",
endTime: "${System.currentTimeMillis()}",
type: "Jenkins",
debug: false,
fatal: false,
])
}
stage ("Deploy to QA") {
sleep "${SLEEP_TIME}"
step([$class: 'UploadDeployment',
//"versionExtId" can be used in place of "id" and "versionName"
id: "${currentBuild.displayName}",
versionName: "${currentBuild.displayName}",
name: "${currentBuild.displayName}",
description: 'UploadBuild Example',
tenantId: "5ade13625558f2c6688d15ce",
initiator: "admin",
//Must specify one of "appId", "appExtId", or "appName"
appName: "${VSM_APP_NAME}",
environmentName: 'PROD',
environmentId: "${VSM_ENV_ID_QA}",
result: "${currentBuild.currentResult}".toLowerCase(),
startTime: "${currentBuild.startTimeInMillis}",
endTime: "${System.currentTimeMillis()}",
type: "Jenkins",
debug: false,
fatal: false,
])
}
}
3.2.2 変数値の編集
編集するスクリプト変数
| 変数名 | 説明 | 例 |
|---|---|---|
| GITHUB_REPO_URL | このワークブックで使用している GitHub リポジトリへの URL | https://github.com/UrbanCodeHCL Accelerate/JKE-App-1 |
| HCL ACCELERATE_ENV_ID_DEV | バリューストリームの DEV 環境を一意に識別する ID | cb348f56-29f3-4ade-9c9f-38daedf3b663 |
| HCL ACCELERATE_ENV_ID_QA | QA バリューストリームのQA環境を一意に識別するID | 7a115f90-f4e5-4181-9920-78b216bb4afc |
| HCL ACCELERATE_APP_NAME | HCL Accelerate パイプラインアプリケーションの名前(ワークブックでは「JKE App1」を使用し、後でこのパイプラインアプリケーションを作成します) | JKE App1 |
| SLEEP_TIME (任意) | ステージ遷移の間に待機する時間を秒単位で指定します。デフォルトは60秒で、必要に応じて編集することができます。 | 60 |
ENV IDとアプリ名の値は「APIの属性」に記載されています。
パイプライン スクリプトは、HCL Accelerate の値ストリームからいくつかの値を必要とします。これらの値を取得するには、値ストリームのツールアイコンのドロップダウンから「Download attributes for API」をクリックします。このファイルから環境IDとアプリケーション名をコピーして、スクリプト内の変数に貼り付けます。
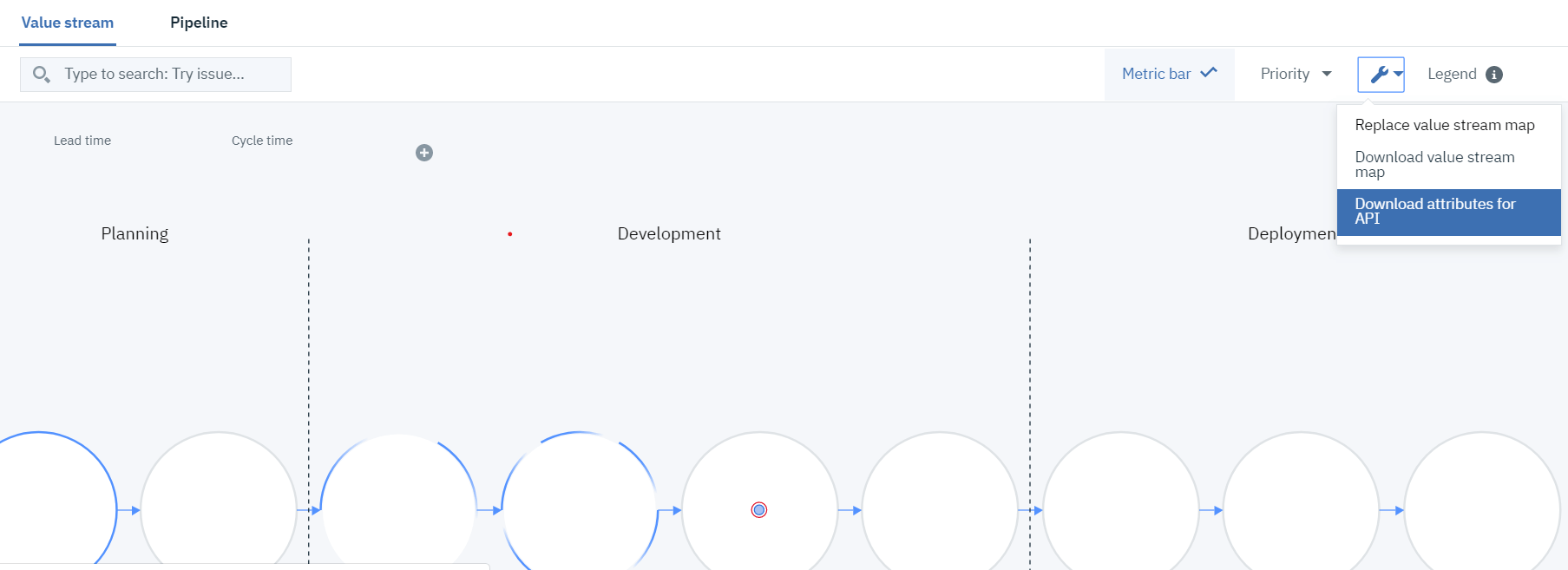
3.3 「適用」と「保存」をクリックします。
4. ビルド、開発、QAのための Jenkins ジョブを実行する
これで、Jenkins ジョブを実行して、HCL Accelerate 値ストリームのステージの変化を観察する準備が整いました。この時点で、バリューストリームに戻ると、「マージされた」ステージにはまだドットがあるはずです。ビルド、DEVデプロイメント、QAデプロイメントの3つのステップを含む、作成した Jenkins パイプラインジョブを実行します。つまり、ジョブを実行すると、ドットが3つの遷移をするのがわかるはずです。つまり、ジョブを実行すると、ドットが3つの遷移をするのがわかるはずです。
4.1 マージド -> ビルド
4.2 ビルド -> DEV
DEV -> QA
三角形が見えますか?
HCL Accelerate はこのビルドからすべてのコミットデータを取得するので、私たちが作成した PR 以外のコミットが表示されることがあります。これらは三角形で表示されます。これは驚くべきことかもしれませんが、私たちが気づかなかったコミットがビルドに含まれているかもしれないということは、完全に理にかなっています。HCL Accelerate は、私たちのバリューストリームの真の状態を表示しています。

説明
スクリプトをコピー&ペーストして、ジョブを実行して、効果を観察しただけなら、「OK、結果は見たけど、これはどうやって動いているんだろう?」ということになるかもしれません。もちろん、それに答えるためには Jenkins のパイプラインスクリプトを勉強しなければなりません。スクリプトの2つの最も重要な部分は、以下に説明する'UploadBuild'と'UploadDeployment'のステップです。
- UploadBuild ステップ UploadBuild クラスは、ビルドデータを HCL Accelerate にアップロードするために使用されます。revisionパラメータは、GitHub データ(この場合はGIT_COMMIT)を介してビルドを作業項目にリンクするために重要です。versionName は、デプロイメントへのフォワードをリンクするために重要です。appNameは、HCL Accelerate パイプラインのアプリケーション名に対応します。
step($class: 'UploadBuild',
id: "${currentBuild.displayName}",
versionName:"${currentBuild.displayName}",
name: "${currentBuild.displayName}",
tenantId: "5ade13625558f2c6688d15ce",
requestor: 'admin',
//Must specify one of "appId", "appExtId", or "appName"
appName: "${VSM_APP_NAME}",
revision: "${GIT_COMMIT}",
status: "${currentBuild.currentResult}".toLowerCase(),
startTime: "${currentBuild.startTimeInMillis}",
endTime: "${System.currentTimeMillis()}",
debug: false,
fatal: false,
)- UploadDeployment ステップ UploadDeployment クラスは、配置データを HCL Accelerate にアップロードするために使用されます。versionName パラメータは、ビルドデータにリンクするために重要です。appName は HCL Accelerate パイプラインのアプリケーション名に対応し、environmentName と environmentId は配置環境を識別するために使用されます。
step([$class: 'UploadDeployment',
//"versionExtId" can be used in place of "id" and "versionName"
id: "${currentBuild.displayName}",
versionName: "${currentBuild.displayName}",
name: "${currentBuild.displayName}",
description: 'UploadBuild Example',
tenantId: "5ade13625558f2c6688d15ce",
initiator: "admin",
//Must specify one of "appId", "appExtId", or "appName"
appName: "${VSM_APP_NAME}",
environmentName: 'PROD',
environmentId: "${VSM_ENV_ID_DEV}",
result: "${currentBuild.currentResult}".toLowerCase(),
startTime: "${currentBuild.startTimeInMillis}",
endTime: "${System.currentTimeMillis()}",
type: "Jenkins",
debug: false,
fatal: false,
])HCL AppScan on Cloud (ASoC) とHCL Accelerate の統合
2020/9/14 - 読み終える時間: 5 分
作業とボトルネックの可視化を実現する HCL Accelerate は、AppScan と組み合わせることもでき、DevOps の可視化と効率化を実現できます。そのことについての解説記事 Integrating HCL AppScan on Cloud (ASoC) with HCL Accelerate の翻訳版です。
HCL AppScan on Cloud (ASoC) とHCL Accelerate の統合
2020年9月12日
著者: Daniel Trowbridge / Technical Lead
ポーカーをプレイしたことがある人なら、カードの組み合わせが重要なことを知っているはずです。ソフトウェアに関しては、適切な製品を組み合わせることで、勝利を手にすることができます。この記事では、HCL Accelerate チームは、HCL AppScan および AppScan on Cloud (ASoC) との統合に注目してみていきたいと思います。
HCL Accelerate は、複数のチームやワークフローにまたがる可視性とガバナンスを提供する、柔軟で強力なリリースおよびバリューストリーム管理ツールです。HCL Accelerate は、1日2回の監督者から現場の DevOps に欠かせないツールです。HCL AppScan は、HCL Accelerate と驚くほど相性が良いのですが、どちらも次世代のソフトウェア開発体験という HCL のビジョンによって推進されています。AppScanは、静的および動的なセキュリティ・スキャンを提供し、オンプレミスとクラウドで提供しています。これらのスキャンは、品質、セキュリティ、およびコンプライアンスにとって非常に重要です。HCL Accelerate は、チーム、製品、ツールチェーン全体で AppScan のデータをインジェストし、可視性とガバナンスを確保することで、作業を継続し、管理を安心して行えるようにします。
さあ、始めましょう。
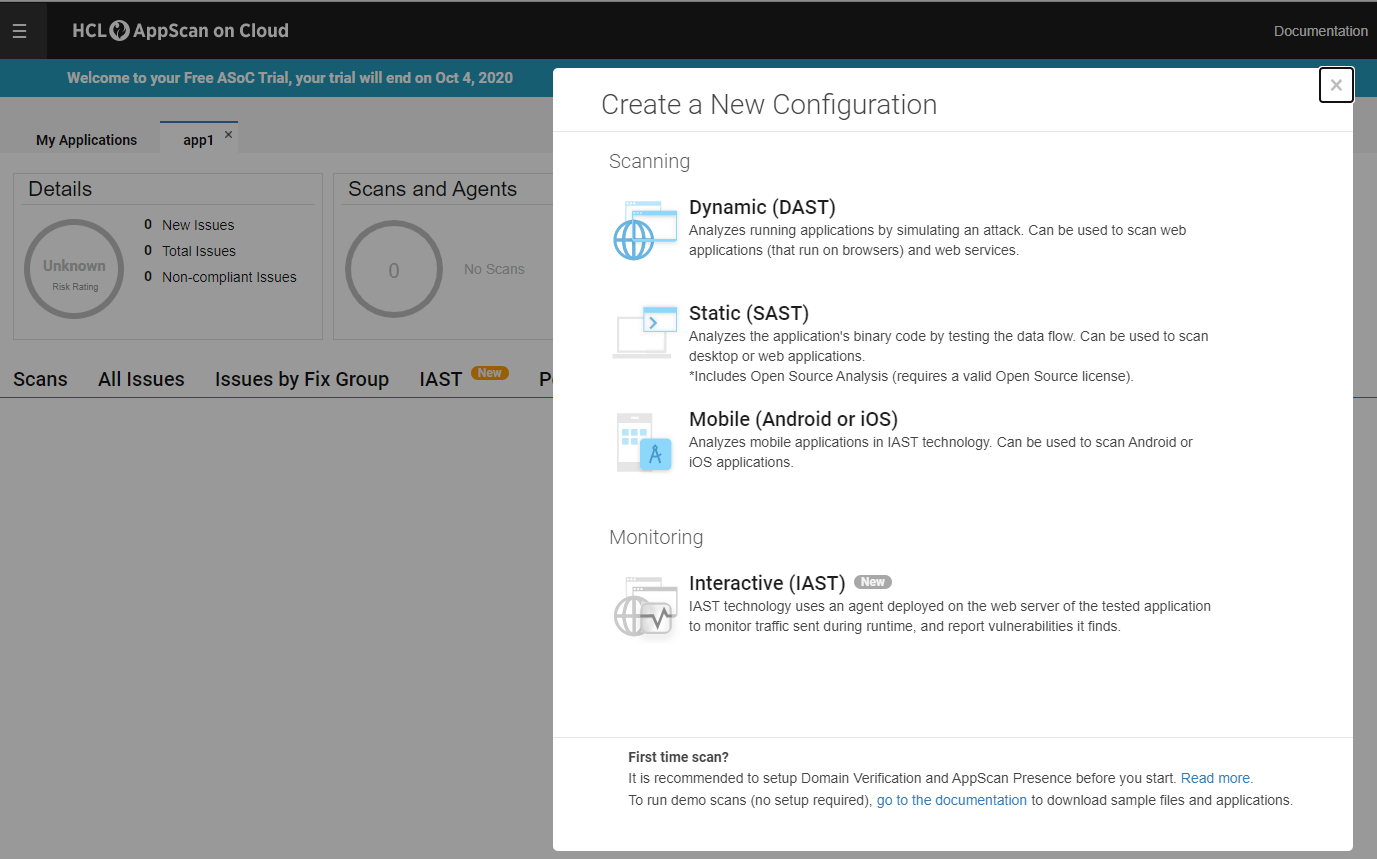
このチュートリアルでは、AppScanのクラウド提供(AppScan on CloudまたはASoC)を使用します。ASoC アカウントとプロジェクトをまだお持ちでない場合は、無料トライアルを利用して今すぐ設定することができます。また、HCL Accelerate をまだお持ちでない場合は、こちらから Community Edition をダウンロードできます。プロジェクトとスキャンの例を以下に示します。
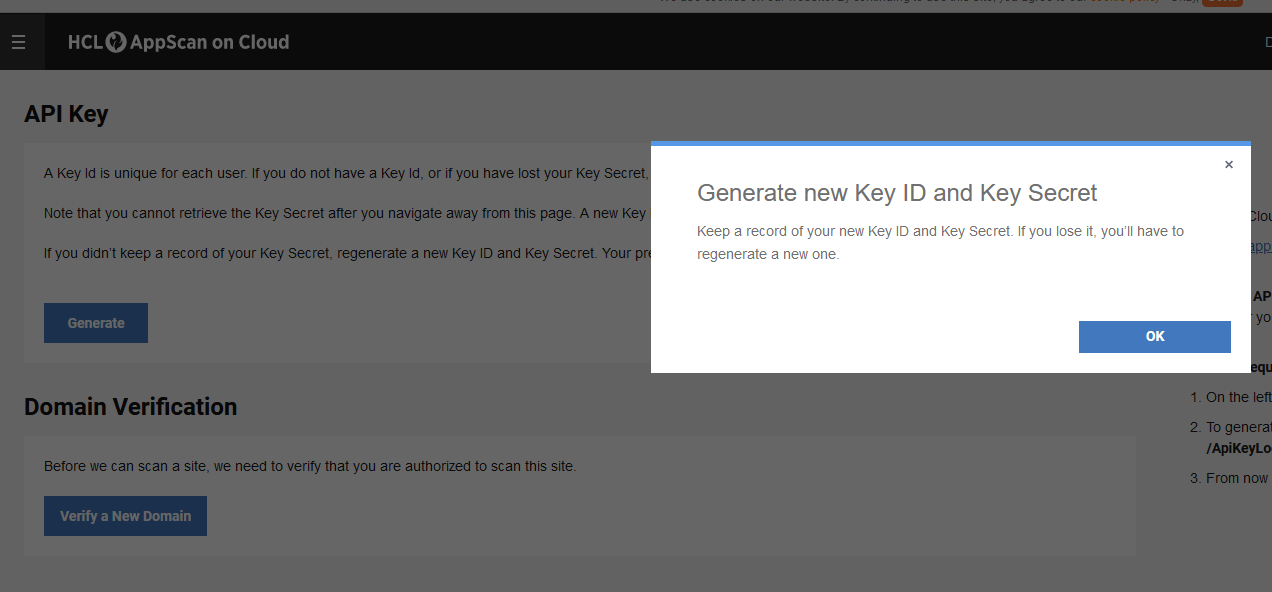
また、ASoCキーIDとキーシークレットを生成する必要があります。
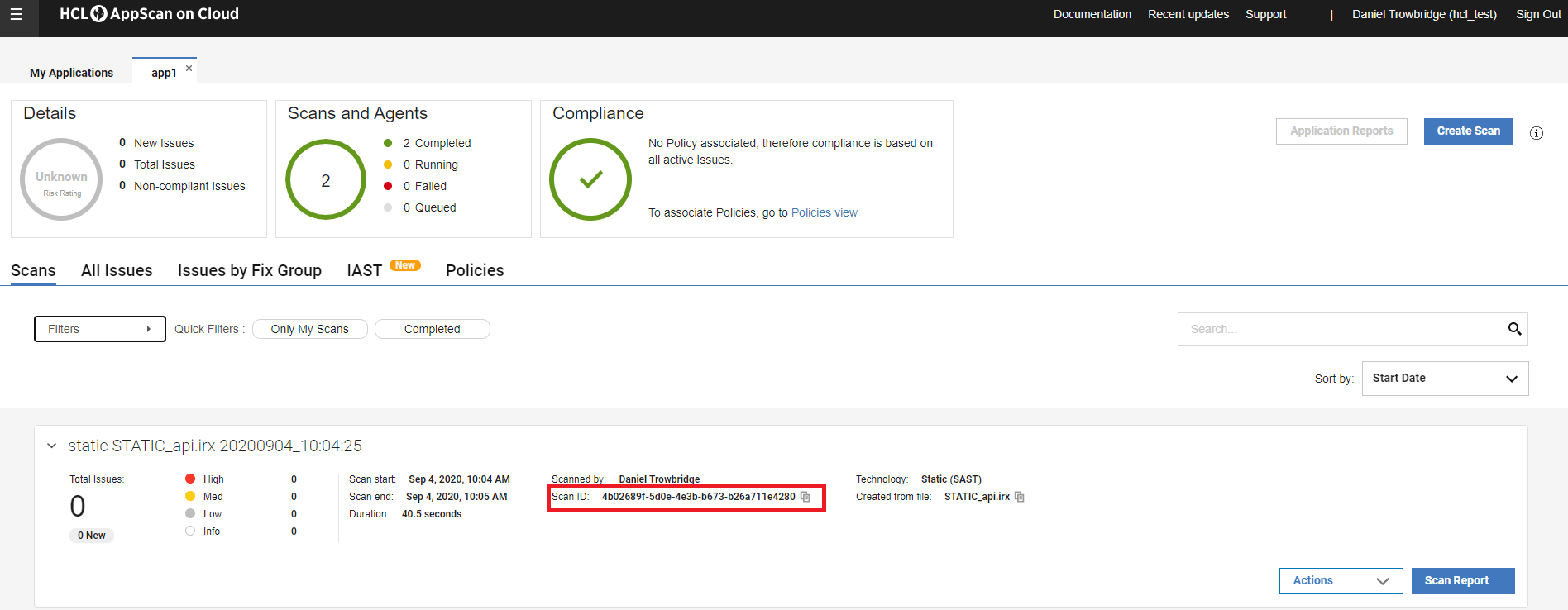
スキャン結果を生成する準備ができたら、スキャナを実行し、scanIDをコピーして貼り付けます。これは、以下のHCL Accelerateセクションに示されているcurlコマンドに後で必要になります。
1. HCL AccelerateでASoCインテグレーションを作成します。
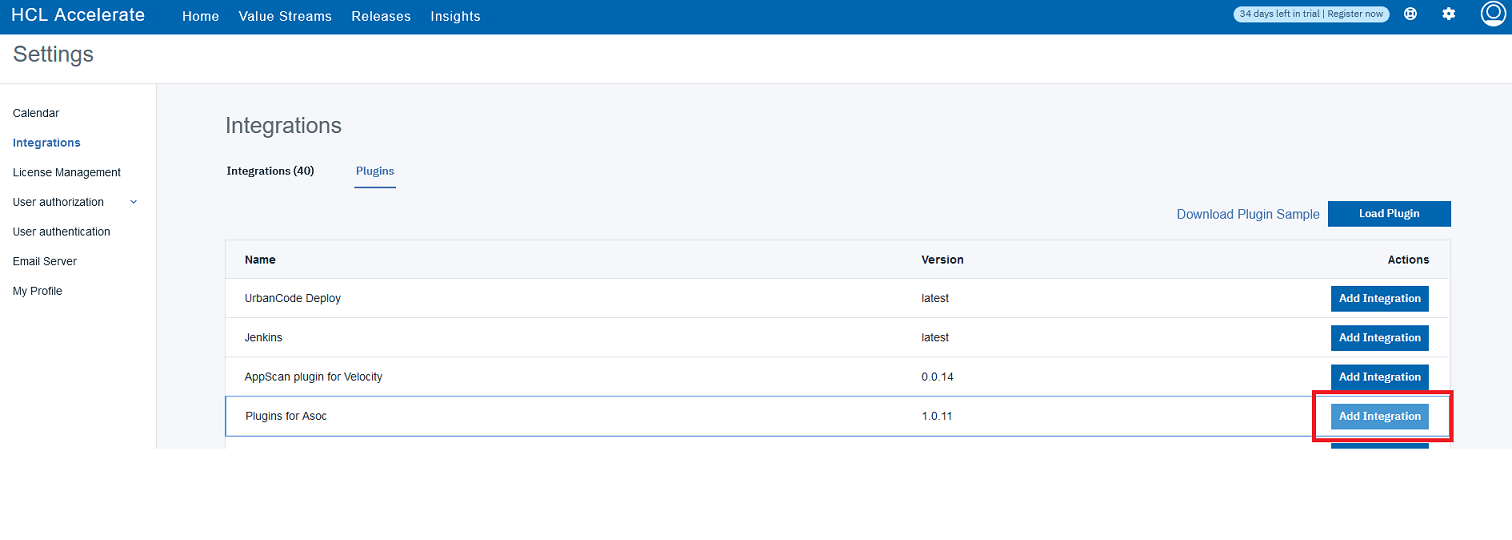
1.1 プラグインを探す
HCL Accelerate で、Settings(設定)>Integrations(統合)>Plugins(プラグイン)に移動し、"Plugin for ASoC"で"Add Integration(統合の追加)"をクリックします。
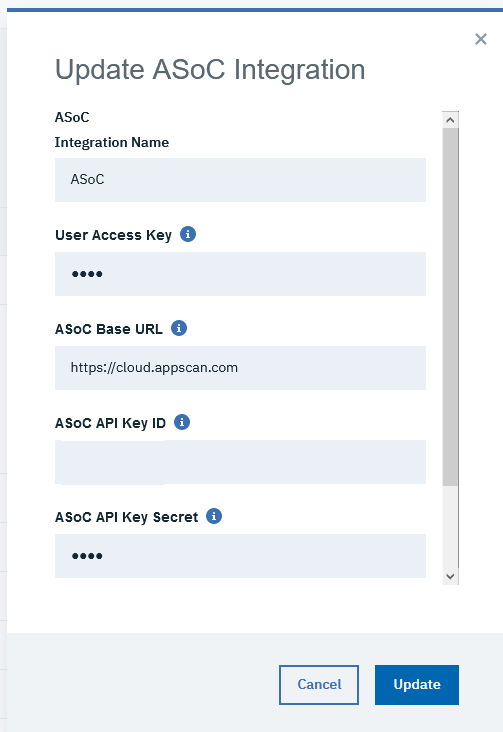
1.2 統合を構成する
統合の追加」フォームに必要事項を入力します。HCl Accelerate と ASoC への認証を設定します。
- 統合名:ASoC_Example_Name_1
- ユーザー・アクセス・キー。HCL Accelerateのユーザー・アクセス・キーをコピーして貼り付けます。(“Settings” > “My profile” で ASoC_Example_Name_1という名前を付けることができます)
- ASoC ベース URL: https://cloud.appscan.com
- ASoC API Key ID。クラウドAPIの認証に使用するIDです。
- ASoC API Key Secret: クラウドAPIの認証に使用される実際のキー。
1.3 統合の検査
統合が作成されたことを確認します。ドロップダウンの詳細を展開して、エンドポイントのURLを表示します。統合エンドポイントのURLにPOSTコマンドでASoCデータをHCL Accelerateに送信します。

2. ASoCスキャン結果をHCL Accelerateに送信する
ASoCスキャン結果をHCL Accelerateに送信するには、スキャンIDを含むJSONオブジェクトをターゲットのHCL Accelerate統合のpluginEndpoint URLにPOSTするだけです。
データ構造の例
{
"scanId": "<ASoC scan ID>",
}Curl コマンドの例
curl -H “Content-Type: application/json” -k -X POST https://<accelerate server>/reporting-consumer/pluginEndpoint/<integration ID>/asocScan -d “{\”scanId\”:\”<scan ID>\”}”
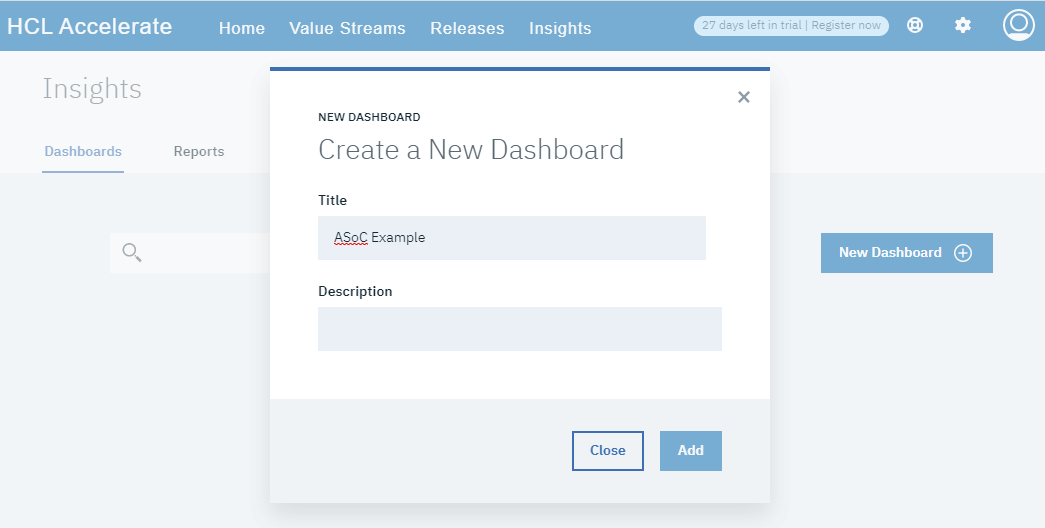
3. データを見る
HCL Accelerateでダッシュボードを設定することで、データを見ることができます。インサイト」に移動し、「ダッシュボードの作成」をクリックします。
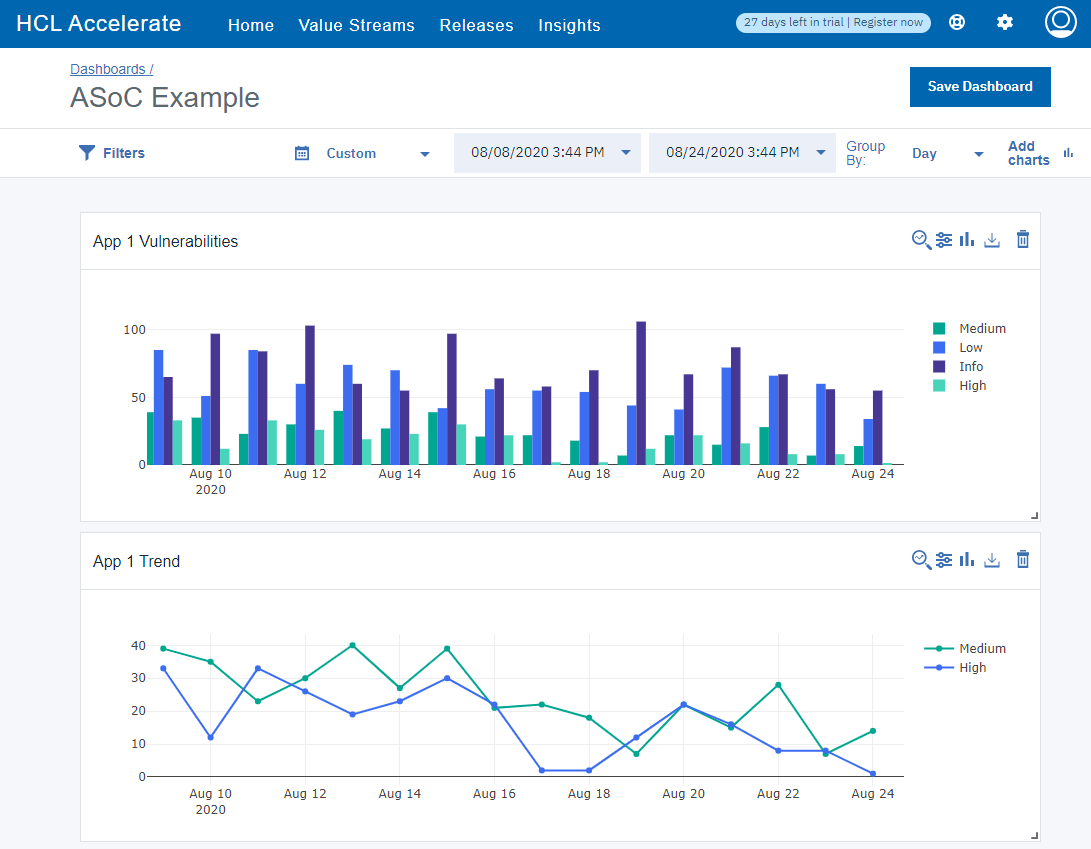
チャートの追加」をクリックし、適切なメトリクスを選択してチャートを作成します。ASoCデータのデフォルトのメトリックは、「Risk」の下の「Application Vulnerabilities」です(ASoCプラグインのバージョン1.0.16以前の場合、デフォルトのメトリックは「Quality」の下の「ASoC Tests」です)。
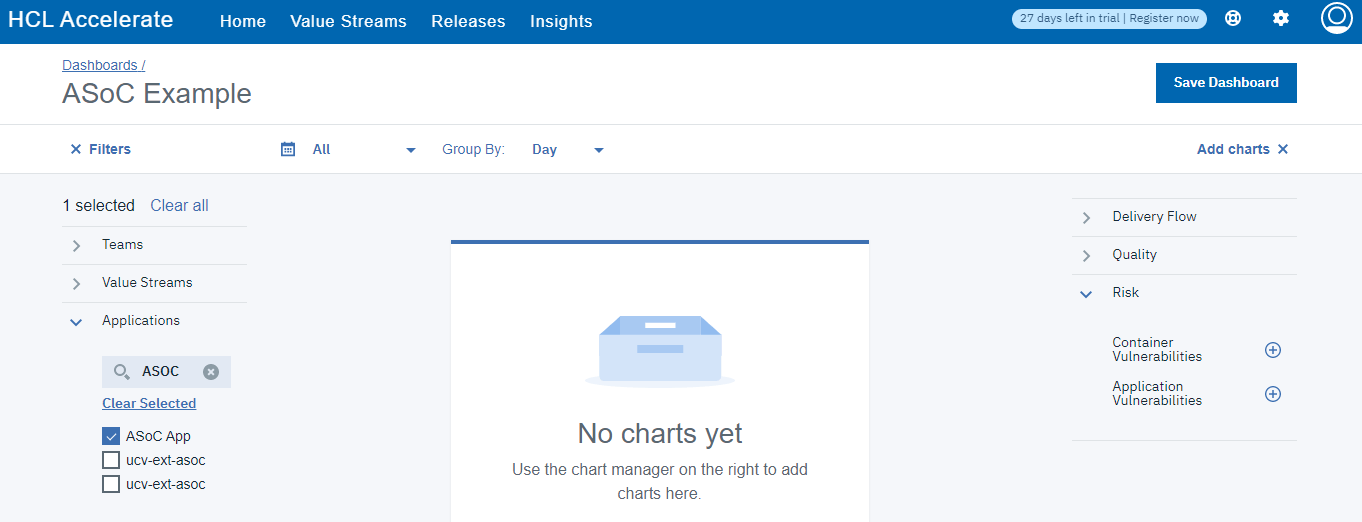
フィルタリング・オプション
複数のフィルターや時間の選択など、データの異なる選択で複数のチャートタイプを作成することができます。
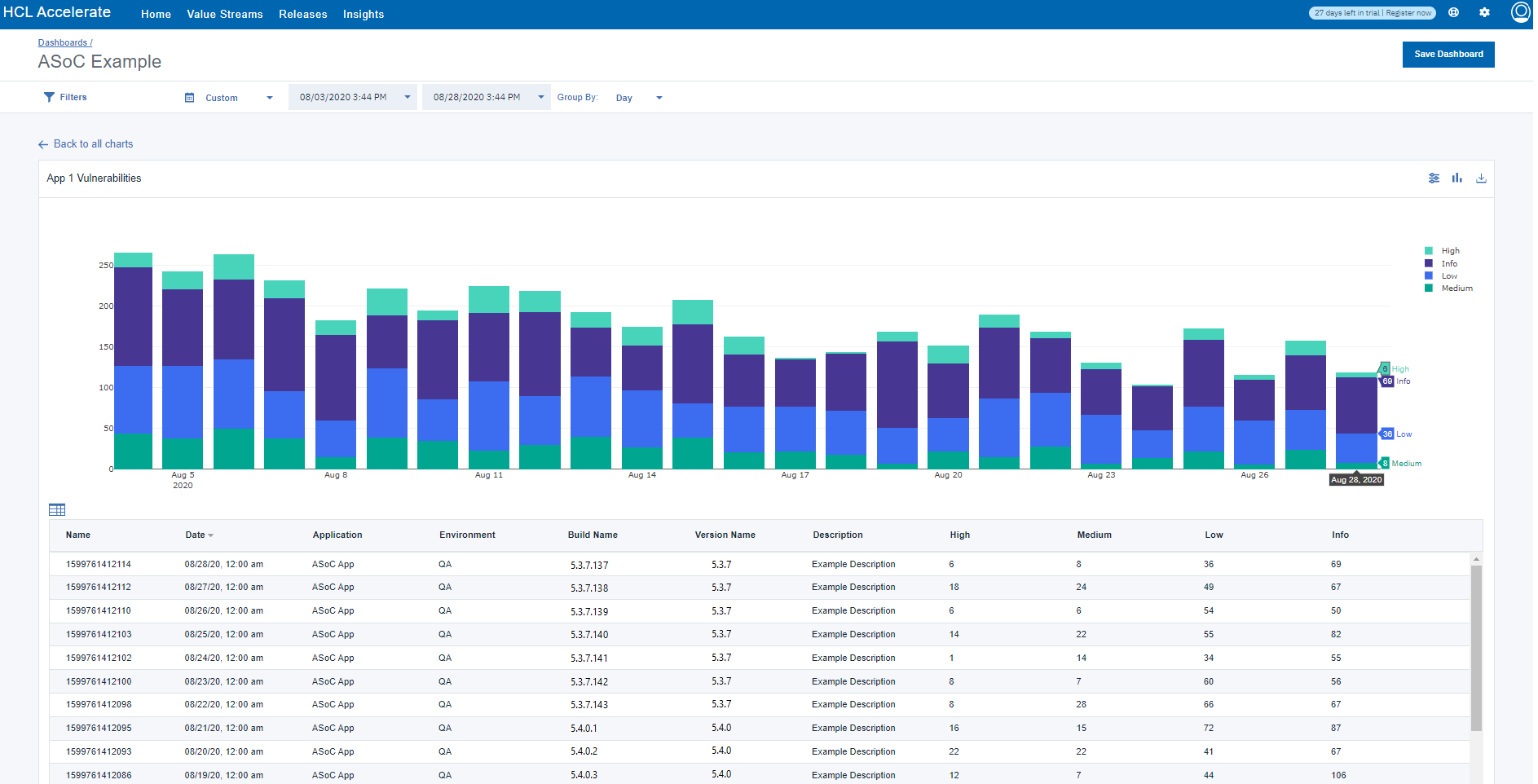
各チャートは、以下のように詳細表を表示することもできます。
Day 2: DevOps: ソフトウェア・デリバリー・パイプラインをもっと使いこなす
2020/9/5 - 読み終える時間: ~1 分
Day 2 DevOps : Getting more out of your software delivery pipeline の翻訳版です。
Day 2: DevOps: ソフトウェア・デリバリー・パイプラインをもっと使いこなす
2020年9月4日
著者: Nick Mathison / Value Stream Manager
多くのチームの DevOps の起源は、2つの方法のいずれかで始まった。最初のシナリオでは、製品のリードやマネージャーがカンファレンスから戻ってきて、突然「 DevOps が必要だ!」と主張し、「すべてを自動化する」というマントラを唱える。もう1つのシナリオでは、不正な開発者が手動インストールの繰り返しに飽きてしまい、自分の悩みを自動化することにした場合です。どのようなアプローチであっても、数ヶ月後には、これらの開発チームは、複数のツール、チーム、依存関係にまたがる行き当たりばったりの自動化の上で日々運用されています。さらに、ログイン認証情報、アプリケーション、実行中のプロセス、成功したか失敗したかのログを解釈する能力が必要なので、デプロイメントタスクを実行する方法を理解しているのは、チームの一部の人だけです。
これらのツールを毎日使用していない限り、単純な質問にすぐに答えることは不可能です。"本番ではどのバージョンが使われているのか?今日のCI/CDの世界では、開発者はパイプラインに目を向けて、一貫性のない自動化された世界に構造を提供し、これらの単純な質問に答えるのを助けようとしています。しかし、パイプラインを深く掘り下げていくと、その答えは全体像のほんの一部に過ぎません。
最も単純な形では、パイプラインはアプリケーション・ディストリビューションと、意図されたホストである環境の交差点です。提示されたインベントリは、新しいバージョンがビルドされ、デプロイされると、左から右へ、パイプラインを通って、環境から環境へと移動します。しかし、毎日の複数の CI ビルドのおかげで、何時間も離れて行われるビルドの違いを見分けることができなくなりました。自動デプロイに暗号化されたバージョンを乗算すると、今では無意味なバージョンがあちこちに存在しています。したがって、以下のようなより深い質問に答えるのに役立つ、より高度なパイプラインが必要になります。"本番環境ではどのような変更が行われているのか」、「変更されたバージョンはどのように本番環境にデプロイされたのか」など、より深い質問に答えるのに役立つ、より高度なパイプラインが必要です。このような知識があれば、問題のある変更が発生したときに素早くピンポイントで特定し、問題のあるバージョンをデプロイ前に停止させることができます。幸いなことに、HCL Accelerate は、パイプライン全体にわたってより深い可視性と厳格なガバナンスを提供するように構築されています。その方法をお見せしましょう
パイプラインの構築
始めるために、コードから一歩引いて、候補となるアプリケーションとその関係者を特定します。CI サーバーから始まり、最終的に顧客の手に渡るまで、ビルドされた成果物の移動を支援する個人を含めたいと考えています。これらの利害関係者には、開発、運用、テスト、パフォーマンスエンジニア、リリースマネージャ、テクニカルサポートなどが含まれます。これらのリソースを特定したら、以下の2つのパートのアジェンダで約2時間のセッションを行うために、これらのリソースを集めてください。
まず、以下の 3 つのリストを作成し、既知のすべてのパイプラインコンポーネントを特定します。
- 開発、テスト、本番、リリースの観点から、アプリケーションのデプロイをサポートするために、どのような環境がアップグレードされ、保守されているか?(注: これらの環境は、必ずしもアプリケーションをホストしているとは限りません。パフォーマンスや統合のためなど、適切なテストを行うために、セカンダリインスタンスが必要になることがよくあります。)
- これらの環境を更新するために、どのような手動または自動化されたプロセスを使用していますか?
- リリース前に、どのようなリリース要件、マイルストーン、サインオフをすべてのバージョンで取得しなければならないか?
次に、この情報を手にして、典型的なバリュー・ストリーム・マッピングの手法を使用して、アプリケーションのパイプラインのフローチャートを構築してください。ホワイトボードを使うのが最も一般的ですが、オンラインのエンティティ関係図ツールでも問題ありません。このモデルでは、環境(#1)、プロセス(#2)、および要件(#3)は、それぞれバブル、入力、および出力で表されます。すべての利害関係者が各コンポーネントの配置に満足したら、HCL Accelerateのパイプラインにきれいにトランスポーズするための明確なアクションプランを持って会議から退散することができます。
余談ですが、様々なエンティティのパターンやグループ化は、パイプラインマッピングプロセスの副作用として認識されていた可能性が高いです。例えば、順次デプロイするのではなく、複数の環境を同時にデプロイすることができます。あるいは、環境ごとに1つの自動化スクリプトを使用するのではなく、1つのスクリプトを複数の環境で再利用することができます。あるいは、リリース要件を左にシフトして、無駄なテストを防ぐことはできませんか?これらのアイデアは、CI/CDパイプラインを最適化し、技術的な負債を減らすために重要ですが、それぞれのリストが変わるたびにパイプラインは進化し続けます。いずれにしても、シンプルなパイプラインを採用することは、開発のエンパワーメントを向上させるための大きな一歩であり、パイプラインには柔軟性を期待すべきです。
提供されるパイプライン戦略は、実装を容易にするために焦点が絞られています。完了すると、チームは「すべてを自動化する」という DevOps のマントラをようやくコントロールできるようになったとマネージャーに警告することができ、自信を持って「どのバージョンが本番であるか」という質問に答えることができるようになる。しかし、それはより大きな DevOps の旅の1日目に過ぎない。どのチーム・メンバーでもパイプラインの中のより深い問題を正確かつ迅速に特定できるようになる2日目の課題を解決するために、パイプラインはどのように役立つのでしょうか?
幸いなことに、HCL Accelerate は、先に述べた挑戦的な Day 2 の質問に答える準備ができています。これまでCI/CDツールについてのみ説明してきましたが、チームは、無料のソースコントロールと課題追跡プラグインを利用することで、バージョン、計画された作業、および計画されていない作業の間で点を結びつけることができます。この関係性により、チームは「本番ではどのような変更があるのか」という質問に明確に答えることができます。さらに、当社のパイプラインのデプロイ計画は、監査とトレーサビリティを通じて、「変更バージョンはどのように本番環境にデプロイされたのか」を説明することができます。そして、より厳しい、あるいはより緩い制御が必要な場合には、当社の堅牢なゲーティングシステムを利用して、パイプラインを流れるバージョンを管理します。Day 2の課題は、HCL Accelerat eの無料の Community Edition で反復的に解決することができます。今すぐダウンロードするにはここをクリックしてください