HCL Accelerate の新しいインタラクティブ・デモ
2020/10/23 - 読み終える時間: ~1 分
New Interactive Demo of HCL Accelerate の翻訳版です。
HCL Accelerate の新しいインタラクティブ・デモ
2020年10月22日
著者: Elise Yahner / HCL

これまで私たちは、バリュー・ストリーム管理ツールである HCL Accelerate についてよく話してきました。私たちはこのツールを本当に誇りに思っており、チームのプロセスと文化を改善するのに役立つと信じています。しかし、実際に HCL Accelerate を見るまでは、それがどのように機能するかを正確に想像するのは難しいです。仕事が忙しくなり、時間に追われているときに、ソフトウェアのデモをスケジューリングすることは、誰もがやるべきことリストの一番下に落ちてしまいます。そこで、オンデマンドでインタラクティブな HCL Accelerate デモを作成しました。
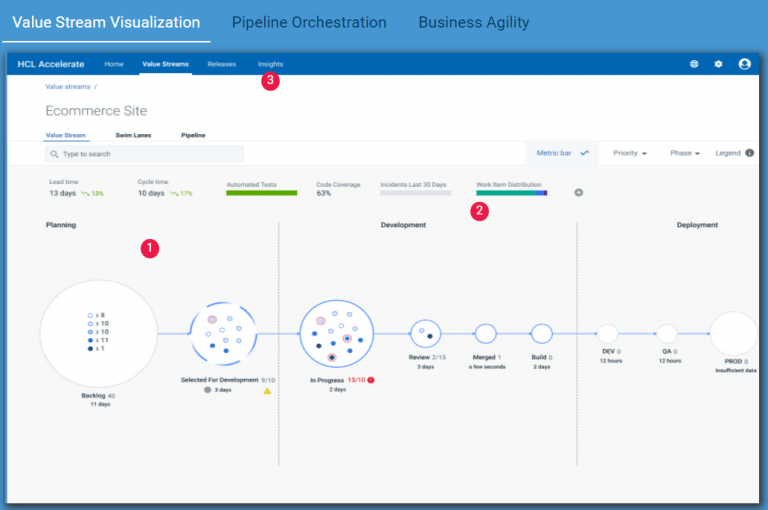
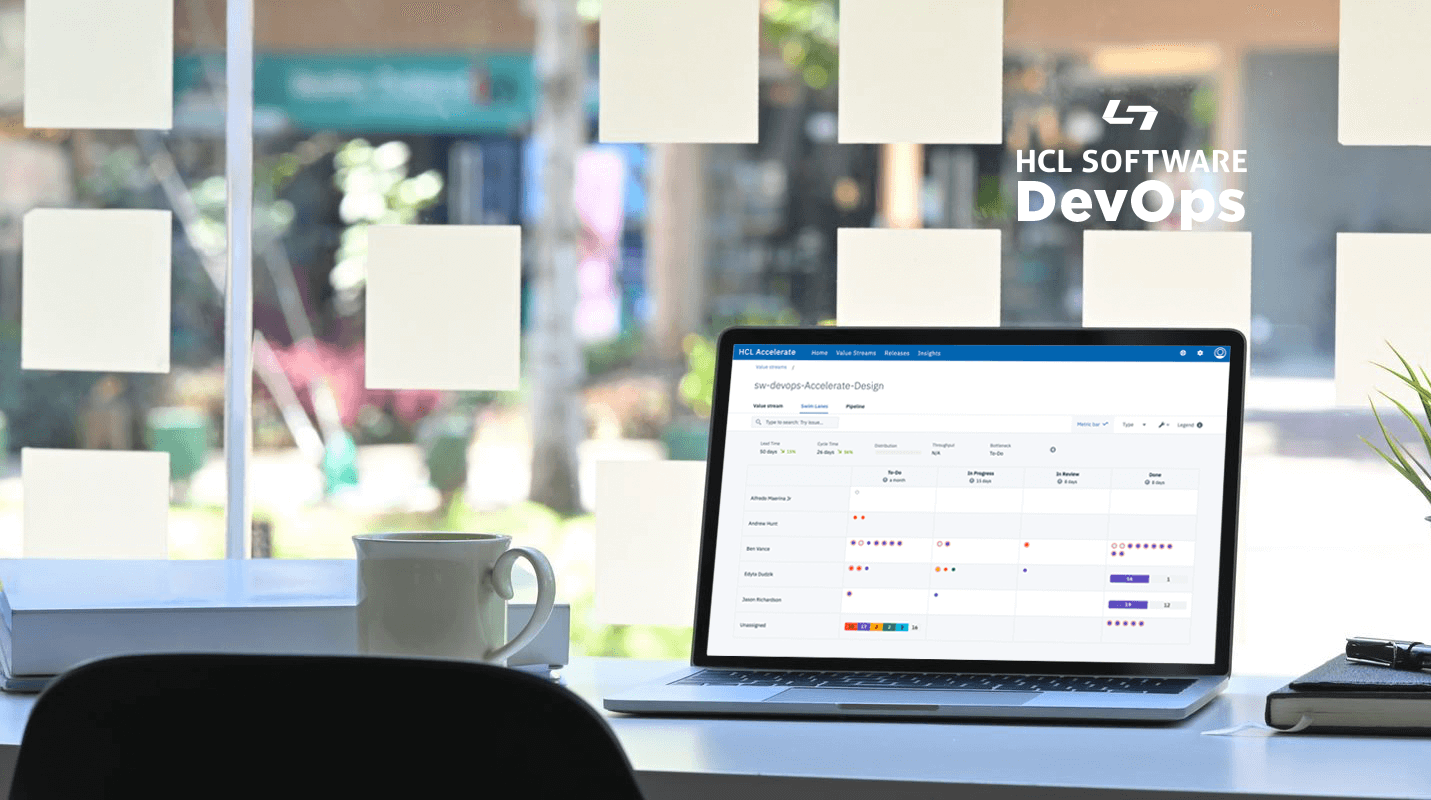
accelerate.hcltechsw.com にアクセスして、ご自身で HCL Accelerate の機能と機能を探索してみてください。タブと赤い点をクリックして、HCL Accelerate がなぜ機能するのか、この VSM (Value Stream Management) ツールの特長は何か、そして誰が恩恵を受けることができるのかをご覧ください。このインタラクティブなデモは、HCL Accelerate がチームに役立つかどうかを確認したい場合に最適です。次に、完全な1対1のデモを受ける準備ができたら、ページの一番下までスクロールして、デモをリクエストしてください。
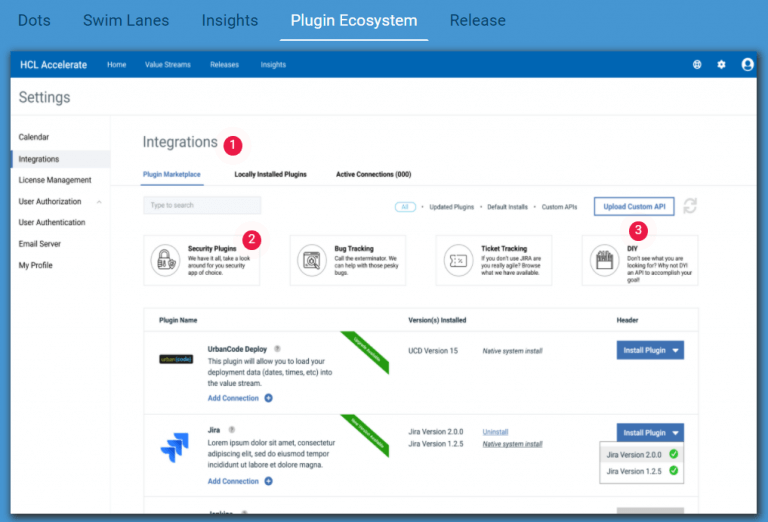
HCL Software DevOps で HCL Accelerate は何ができるかをご覧になれば、それが組織にどのような利益をもたらすかを理解していただけるかと思います。今すぐ accelerate.hcltechsw.com にアクセスして、ご自身の目でお確かめてください。
HCL Accelerate: Windows と Docker-Compose と組み合わせてクイックスタート
2020/10/22 - 読み終える時間: 5 分
HCL Accelerate Quick Start with Windows and Docker-Compose の翻訳版です。
HCL Accelerate: Windows と Docker-Compose と組み合わせてクイックスタート
2020年10月20日
著者: Daniel Trowbridge / Technical Lead
HCL Accelerate の無料版を使えば簡単に始められます。このクイックスタートは Windows 上の Docker-Compose を対象としていますが、他のオーケストレーションプラットフォームにも対応しています。もちろん、Mac や Linux 用のクイックスタートもありますが、コンテナ化されたアプリケーションなので、手順は非常に似ています。詳細については、詳細なドキュメントを参照してください。
始める前に必要なものは以下の通りです。
- Docker Composeがインストールされ、実行されていること
- HCL Accelerate User Access Key (ここで入手できます)
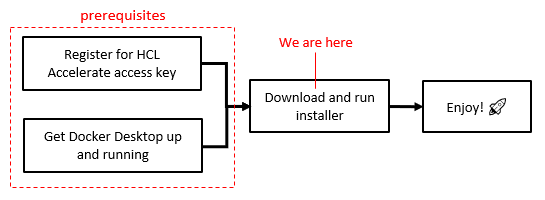
1. インストーラのダウンロード
以下のリンクをクリックして、HCL Accelerate Windowsインストーラをダウンロードしてください。
2. インストーラの実行
インストーラをダブルクリックして実行します。以下に示すように、設定値の入力を求められます。
- アクセスキー。アクセスキー: 製品版に応じたアクセスキーを入力してください。
- ライセンス。ライセンス: ライセンスの承認が必要です。ライセンス: ライセンスの受諾が必要です。ライセンスを読んだ後に再度プロンプトが表示されたくない場合は、 インストーラーに -license=accept 引数を渡してください。
- プラットフォーム: "Docker Compose"をプラットフォームとして選択してください。
- インストールディレクトリ: Installation Directory: インストールフォルダーの親ディレクトリへのパスを指定します。インストールファイルは親ディレクトリの下のバージョンフォルダーに配置されます。これにより、同じ親ディレクトリを将来のアップグレードに使用することができます。
- ホスト名: HCL Accelerate のホスト名を指定します。デフォルトは localhost です。ホスト名は、DNS 解決または hosts ファイルなどで、すでに構成されている必要があります。
- ポート: ポート番号を指定します。デフォルトは 443 です。
- Startup: インストーラから HCL Accelerate を起動するか、以下の「HCL Accelerate の起動」を参照してください。
インストーラのオプション: インストーラには多くのコマンドラインオプションがあり、完全に自動化することができます。インストーラを -help フラグで実行して、サポートされている内容を確認してください。
settings.json: アプリケーションの重要な一意のキーは、ユーザー固有のもので、[ユーザーホームディレクトリ]/.ucv/settings.json に保存されていることに注意してください。このファイルは、将来の再インストールやアップグレードで使用するために、インストーラーの入力も保存します。値は、必要に応じてバックアップおよび/または移動してください。

3. HCL Accelerate の起動
インストーラから直接 HCL Accelerate を起動するか、インストールされたバージョンのディレクトリに移動して docker-compose up -d を実行します。この時点で HCL Accelerate イメージがDocker Hub からプルされているはずです。Docker Hub から引き出せない場合は、圧縮されたイメージを含むオフラインインストーラも利用できます。
Docker Compose を学ぶ。Docker Compose CLI については、docker.com で詳しく説明しています。
4. 最初のログイン
ブラウザー(Chromium ベースまたは Firefox を推奨)を開き、インストーラーに提供されたホスト名とポートに従って、HCL Accelerate のアドレス(https://<ホスト名>:<ポート>)に移動します。有効な証明書を設定していない場合、デフォルトの証明書は自己署名されているため、証明書の警告が表示されます。この警告を過ぎて進むと、HCL Accelerate ログイン画面が表示されるはずです。ユーザー名とパスワードの両方に「admin」を使用して、最初にログインすることができます。
5. 次のステップ
チュートリアルとブログ: https://blog.hcltechsw.com/accelerate/
動画: https://www.youtube.com/playlist?list=PL2tETTrnR4wviGuleB2xwSR7-P7m-rzTa
ナレッジセンター
-
管理業務
-
バリューストリームマネジメント
-
その他
OneTest: 組込みソフトウェア試験の業界標準認証を取得
2020/10/19 - 読み終える時間: 2 分
Achieving Industry Standard Certification for Embedded Software Testing の翻訳版です。
組込みソフトウェア試験の業界標準認証を取得
2020年10月16日
著者: Nabeel Jaitapker / Product Marketing Lead, HCL Software

コンポーネント・テスト・ハーネス、テスト・スタブ、テスト・ドライバの作成と展開を自動化することは、HCL OneTest Embedded を使えば容易に実現できます。
どのような開発環境からでもワンクリックで、メモリとパフォーマンスをプロファイルし、コードカバレッジを分析し、プログラムの実行動作を可視化することができます。
さらに、HCL OneTest Embedded は、チームがより積極的にデバッグを行い、コードが壊れる前に修正することを支援します。
HCL OneTest Embedded 8.3.0 の新機能
Eclipse 4.7.3 と 4.12(2019.06)とCDT 9 をサポート
- Rational Test RealTimeはEclipse 4.7.3とCDT 9で提供されるようになりました。
- アップデートサイトの仕組みを利用して、Eclipse 4.12(通称:2019.06)にもインストールできます。
Eclipse IDE で OTD テストスクリプトを実行
- テスターは、PTUテストスクリプトと全く同じように、スタジオからEclipse IDEにOTDテストスクリプトをインポートして実行することができるようになりました。
- スタジオと同じ方法でレポートが生成されます。
新しいコードレビュー HTML レポート
- コードレビューのポストプロセッサは、新しいHTMLレポートを生成します。
- このレポートは、テスターが独自のロゴやタイトルを導入するために修正できるテンプレートに基づいています。
MISRA 2004 と2012 のルール改善
- コードの行数に関するルールは、コードの行数を計算するためのさまざまな方法を提案しています(空行の有無、コメントの有無)。
- 新しいルールが利用可能になりました。
- コンパイルユニット内の関数の最大数
- コンパイルユニット内のグローバル変数の最大数
- コンパイル単位の最大行数
- 関数内のパラメータの最大数
Eclipse IDEを他のテストツールに開放
- Eclipse IDE は、Python、シェルまたは Windows のコマンド命令に基づいたテストスクリプトをサポートしています。
- ランタイム解析機能を並行して使用可能
- これらのツールで生成された HTML レポートは、グローバルレポートの一部にもなります。
このオンデマンド・ウェビナーでは、HCL OneTest Embedded チームが、テストと分析のためのクロスプラットフォーム・ソリューションについて議論します。さらに、HCL OneTest Embedded は、デバッグをより積極的に行い、コードが壊れる前にコードを特定して修正する方法を示してくれます。
データ駆動型 DevOps パート 5: アライメントとガバナンス
2020/10/19 - 読み終える時間: 3 分
Data-Driven DevOps Part 5: Alignment and Governance の翻訳版です。
データ駆動型 DevOps パート 5: アライメントとガバナンス
2020年10月15日
著者: Steve Boone / HCL Software DevOps Head of Product Management
- Accelerate: データ駆動型 DevOps パート 1: 序章
- Accelerate: データ駆動型 DevOps パート 2: データ駆動型の文化
- Accelerate: データ駆動型 DevOps パート 3: データを使った追跡と計画
- Accelerate: データ駆動型 DevOps パート 4: ビジネス・アジリティ
- データ駆動型 DevOps eBookですべてを手に入れよう
多くの点で、データ駆動型のDevOpsは、ソフトウェア・ビジネスがどのように運営されているかを詳細に把握することを可能にします。この種の戦略は、製造工場の上の産業用キャットウォークのようなものだと考えてください。データは、アイデアからクライアントに至るまで、ソフトウェアのデリバリー・ライフサイクル全体を網羅することで、驚くほどの可視性を提供します。この可視性は非常に有益です。組織内で何が起こっているかを知ることができるだけでなく、再作業を減らし、コストを削減し、ビジネスにガバナンスを提供してリスクを軽減する機会を提供してくれます。
データ駆動型のDevOpsとバリュー・ストリーム管理は、「あったらいいな」と思う機能セットではないことを理解することが重要です。以下の問題解決に真剣に取り組みたいと考えている企業にとっては、「持っていなければならない」機能です。
ビジネスの整合性
まずは、いくつかの質問から始めてみましょう。顧客を喜ばせ、収益を向上させる機能は、積極的に取り組んでいますか?それらの機能はバックログに残っていますか?予定より早く、あるいは遅れていますか?いつになったら、クライアントに約束した価値を提供できるようになるのでしょうか?
簡単に言えば、ビジネスの整合性とは、エンジニアリングチームが行っている開発作業が、全体的なビジネス目標に可能な限り整合しているかどうかを確認することです。開発とビジネス目標が一致している企業は、より高品質なソフトウェアをより早く提供することができます。なぜでしょうか?それは、ビジネスの主な優先事項が明確だからです。個々のコントリビュータは、一日に何度も「すべきか、すべきでないか」の決断を迫られることはありません。
多くの企業は、エンジニアリングチームがどのような開発ツールやプラクティスを使用するかを強制しなくなっています。開発組織が毎日使いたいツールを選べば、より幸せで生産性の高いものになるという願いが込められています。これは必ずしも真実ではありませんが、ビジネスにとっては真の課題となります。実際にどのような作業が行われているかを可視化することは、すでに非常に困難な問題です。また、それぞれが独自のプロセスやツールを使用している何百もの開発チームのデータを集計しようとすると、さらに困難な手作業になってしまいます。
データ駆動型のDevOpsは、ビジネスの連携にこれまでにない機能を提供します。バリューストリームを流れる作業を可視化することで、開発マネージャ、プロダクトオーナー、リリースエンジニア、エグゼクティブなど、誰もがそれを見る必要がある人は誰でも、現在何に取り組んでいるのかを知ることができます。進行中の作業とまだ開発されていない作業(バックログ)の両方を検索して、実際のビジネス価値がどこにあるのかを明確にレポートすることができることを想像してみてください。
私の経験では、開発チームは正しいことをしたいと思っています。開発チームは、価値を提供してくれる機能に集中したいと考えています。多くの場合、最高の貢献者はいくつかの方向に引っ張られ、顧客を喜ばせ、真のビジネス価値を提供することに最も近い仕事から遠ざかってしまうことがあります。このような仕事は、時には無計画であるために、さらに困難を伴うこともあります。無計画な仕事は生産性を窒息させ、ビジネス価値を期限内に提供する組織の能力に大きな負担をかけることになります。
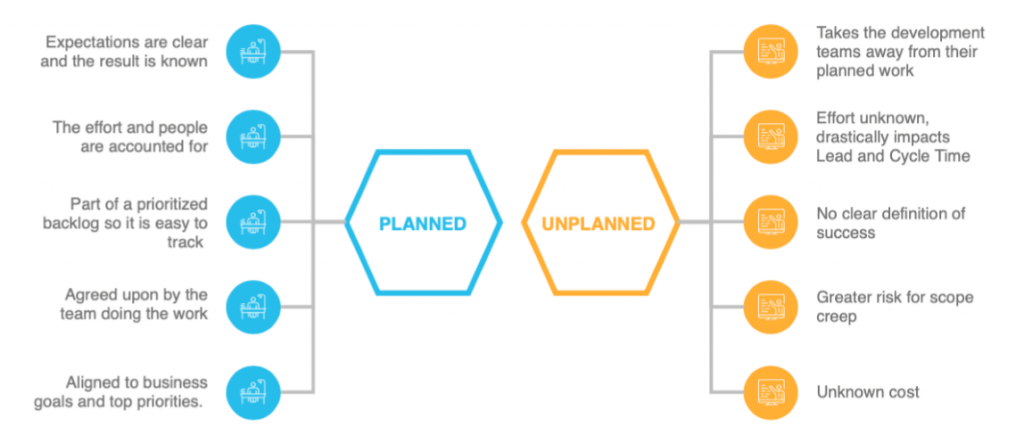
無計画な仕事
無計画な仕事を完全に払拭することはできませんが、それを管理できるかどうかは非常に重要です。計画外の仕事には多くの課題があります。
- それは計画された優先順位のある仕事から焦点を奪う
- 完成までの労力は不明
- 成功の明確な定義がないことが多い
- それは「スコープ・クリープ」の扉を開く。
企業は、計画していないことに対して、どのようにリソースと時間を配分しているのでしょうか?さらに重要なのは、どのようにして計画外の仕事を積極的に減らしていくかということです。その答えは、お察しの通り、私たちが毎日使用しているツールのデータの中にある。計画された作業を追跡するためにコードのコミットや作業項目を追跡するのと同じように、サポートツールや作業項目管理ツールからのデータを使用して、計画外の作業とそれがビジネス価値を提供する能力に与える影響を可視化することができます。
組織の最高の貢献者は、通常、予定外の作業に最も苦しんでいる人たちです。彼らは最も知識が豊富で、重要なサポート問題を支援するのに最も適していると考えられており、困難なシナリオでクライアントを支援した経験が最も豊富です。トップパフォーマーだけに頼ることの問題点は、同じ貢献者であっても、価値の高い非常に重要なビジネス上の成果物の大半を担っている可能性が高いということです。そのため、もしあなたのデフォルトの動きが、火事を消すために常に最も熟練した従業員を連れてくることであるならば、計画された仕事は苦戦を強いられることになります。
このような状況を改善するには、個々の貢献者がどの帯域幅を持っているかを可視化することで、余分なキャパシティを確保することができます。これにより、チームが一時的にフォーカスをシフトしている間に、ビジネス価値を牽引している余分な計画的な仕事を引き受けてくれる個人を特定することで、他のチームメンバーがそれぞれの役割で成長する機会を提供します。
計画外の仕事は予期せぬことであり、困難であり、主要なビジネスの専門家から労力を奪い、おそらく何よりも組織の文化を損なってしまう。計画外労働は、持続不可能な労働慣行と不健全な文化につながる可能性があります。計画外労働を根絶することはできませんが、データを利用してその影響を軽減し、組織の文化と生産価値を維持することはできます。
品質とセキュリティの取り組みを検証する
セキュリティと品質への取り組みが枯れてしまったり、早期に失敗したり、実を結ばなかったりするのを防ぐにはどうすればよいのでしょうか。個々のチームやビジネスユニットにとってはそれほど大変な作業ではないかもしれませんが、組織全体で管理することは非常に大きな作業です。
先に述べたように、多くの企業が生産性の向上を期待して、開発組織に自分たちが最も使いやすいと感じるツールを選択させています。これにはいくつかの利点がある一方で、全く新しい課題も発生します。組織は、何十ものツールセットと何十年もの技術にまたがるセキュリティと品質の取り組みをどのようにして追跡し、実施することになるのでしょうか?組織のすべてのアプリケーションとチーム全体の品質とセキュリティの結果を集約することで、企業はどの取り組みが健全で、どの取り組みにさらなる育成が必要なのかを見極めることができます。
リスクを軽減する自動化されたガバナンス
組織は、特定のリリースの「準備ができているかどうか」を計画し、検証するための会議にかなりの時間を費やしています。リリースエンジニアと変更諮問委員会 (CAB) のメンバーは、健全な量のチェックとバランスを提供していますが、これは大部分が長く、手動で行われるプロセスです。10年にわたる DevOps のベストプラクティスから何かを学んだとすれば、長くて手間のかかる手動の作業は、自動化されることを切望しているだけだということです。経験上、手動プロセスはエラーが発生しやすいことがわかっています。
品質とセキュリティのメトリクスの可視性を提供することは、最初のステップに過ぎません。次のステップは、ビジネスと顧客を保護するためにデータを使用することです。そのための最良の方法は、バリューストリームから送られてくるライブデータの定常的な流れを管理し、特定のビルド、デプロイメント、リリース、コンポーネント、機能、またはビジネスイニシアチブのセットがテストおよびスキャンされたかどうかに基づいて、インテリジェントな決定を下すことができるインテリジェントなゲーティングメカニズムを設定することです。
最高情報セキュリティ責任者 (CISO) は、組織内のすべてのバリューストリームを簡単に見ることができ、誰が会社で実施されているベストセキュリティプラクティスに従っているかを知ることができるので、コスト削減につながることを考えてみてください。また、リリースエンジニアが顧客に悪影響を及ぼす可能性のある品質リスクを簡単に特定できるようになれば、リリースエンジニアにとってのメリットを考えてみてください。
リスクを軽減し、セキュリティと品質を一貫して向上させる最善の方法は、これらを常にビジネスの優先事項とすることです。バリューストリームマネジメントは、お客様がこれらの取り組みを日々のタスクの最前線に置いておくことができるように支援します。
ベストプラクティスの特定
ベストプラクティスを見極めることは、重要なスキルです。ベストプラクティスは、問題を解決するための最も効果的な方法を伝えるのに役立ちます。組織のバリューストリーム全体のすべてのデータを見ることで、企業は単なる推測ではなく、何が本当にベストプラクティスなのかを特定し始めることができます。チームリーダーやその他の利害関係者は、パフォーマンスに関する重要な質問に答える機会を得ることができます。なぜ、あるバリューストリームの品質とセキュリティ(またはその他の技術的な側面)が他のバリューストリームよりも優れているのか?トレーニングの不足が原因なのか?適切なツールを使用していないのか?これらの質問に答えて質問することで、組織は社内で機能していることの根本原因を突き止め、それを組織全体で再現し、改善が必要なことは何かを迅速に対処することができるようになります。
データを使用してベストプラクティスを特定することのもう一つの大きな利点は、どのバリューストリームが高いパフォーマンスを発揮しているかが非常に明確になることです。高いパフォーマンスを発揮しているチームは、適切に定義されたDevOpsのベストプラクティスの結果である。組織内で高いパフォーマンスを発揮しているチームが特定されたら、そのチームの仕事を称えることは文化的にも重要です。彼らの努力は高く評価され、拍手喝采され、他のチームのベンチマークとして活用されるべきです。 データドリブンDevOps ebookデータドリブンDevOps eBookを入手する
私の新しいeBookで、データとDevOpsの関係について学び続けてください。ダウンロードはこちらから。
HCL Accelerate を Linux と Docker-Compose を使ってクイックスタートする
2020/10/15 - 読み終える時間: 5 分
HCL Accelerate Quick Start with Linux and Docker-Compose の翻訳版です。
HCL Accelerate を Linux と Docker-Compose を使ってクイックスタートする
2020年10月14日
著者: Daniel Trowbridge / Technical Lead
HCL Accelerate の無料の Community Edition を使えば簡単に始められます。このクイックスタートは Linux 上の Docker-Compose を対象としていますが、他のオーケストレーションプラットフォームにも対応しています。Mac や Windows 用のクイックスタートもありますが、コンテナ化されたアプリケーションなので手順は非常に似ています。詳細については、詳細なドキュメントを参照してください。
始める前に必要なものは以下の通りです。
- Docker Composeがインストールされ、実行されていること
- HCL Accelerate User Access Key (ここで入手できます)
1. インストーラのダウンロード
以下のリンクをクリックして、HCL Accelerate Linux インストーラをダウンロードしてください。
最新バージョン https://hcl-velocity-binaries.s3.amazonaws.com/accelerate-hcl-install-latest-linux
2. インストーラの実行
インストーラが実行に必要なパーミッションを持っていることを確認してください。
sudo chmod +x accelerate-hcl-install-latest-linux
インストーラーを実行します。
./accelerate-hcl-install-2.6.0-linux
以下の設定値を入力するように求められます。
- アクセスキー: アクセスキー:製品版に応じたアクセスキーを入力してください。
- ライセンス: ライセンス: ライセンスの承認が必要です。ライセンスを読んだ後、再度プロンプトが表示されたくない場合は、インストーラーに ?license=accept 引数を渡してください。
- プラットフォーム: プラットフォーム: "Docker Compose" をプラットフォームとして選択してください。
- インストールディレクトリー: Installation Directory: インストールフォルダーの親ディレクトリーーへのパスを指定します。インストールファイルは親ディレクトリーの下のバージョンフォルダーに配置されます。これにより、同じ親ディレクトリーを将来のアップグレードに使用することができます。
- ホスト名: HCL Accelerate のホスト名を指定します。デフォルトは localhost です。ホスト名は、DNS 解決または hosts ファイルなどで、すでに構成されている必要があります。
- ポート: ポート番号を指定します。デフォルトは 443 です。
- Startup (起動): インストーラから HCL Accelerate を起動するか、以下の「HCL Accelerate の起動」を参照してください。
インストーラのオプション: インストーラには多くのコマンドラインオプションがあり、完全に自動化することができます。-help を付けてインストーラを実行して、何をサポートしているかを確認してください。
settings.json: アプリケーションの重要な一意のキーは、ユーザー固有のもので、[ユーザーホームディレクトリー] /.ucv/settings.json に保存されていることに注意してください。このファイルは、将来の再インストールやアップグレードで使用するために、インストーラーの入力も保存します。値は、必要に応じてバックアップおよび/または移動してください。

3. HCL Accelerate の起動
インストーラから直接 HCL Accelerate を起動するか、インストールされたバージョンのディレクトリーに移動して docker-compose up -d を実行します。この時点で HCL Accelerate イメージがDocker Hub からプルされているはずです。Docker Hub からプルできない場合は、圧縮されたイメージを含むオフラインインストーラも利用できます。
Docker Compose を学ぶには: Docker Compose CLI については、docker.com で詳しく説明しています。
4. 最初のログイン
ブラウザー(ChromiumベースまたはFirefoxを推奨)を開き、インストーラーに提供されたホスト名とポートに従って、HCL Accelerate のアドレス(https://<ホスト名>:<ポート>)に移動します。有効な証明書を設定していない場合、デフォルトの証明書は自己署名されているため、証明書の警告が表示されます。この警告を過ぎて進むと、HCL Accelerate ログイン画面が表示されるはずです。ユーザー名とパスワードの両方に「admin」を使用して、最初にログインすることができます。
5. 次のステップ
- チュートリアルとブログ: https://blog.hcltechsw.com/accelerate/
- 動画: https://www.youtube.com/playlist?list=PL2tETTrnR4wviGuleB2xwSR7-P7m-rzTa
ナレッジセンター
- 管理
- バリューストリームマネジメント
- その他
OneTest: インテリジェントなデータ生成を目指して
2020/10/9 - 読み終える時間: 3 分
HCL OneTest - Moving Towards Intelligent Data Generation の翻訳版です。
OneTest: インテリジェントなデータ生成を目指して
2020年10月8日
著者: Juhi Jain / Technical Architect

今日の世界では、データの複雑さが日々増加し続け、納期が短縮されていく中で、テスト担当者は望ましいレベルのテストを実現するための課題に直面しています。管理すべき膨大なデータ量と多様性がある中で、テスターは、すべての可能なテストシナリオをカバーするテストデータを作成するという課題に直面します。ほとんどの場合、テストの望ましい結果を達成するための大きな障害となるのは、テストデータの不足です。テストデータは、あらゆるアプリケーションテストの重要な部分です。短期間で品質の高いテストを成功させるためには、合成データを生成することが不可欠になります。
歴史的なアプローチ
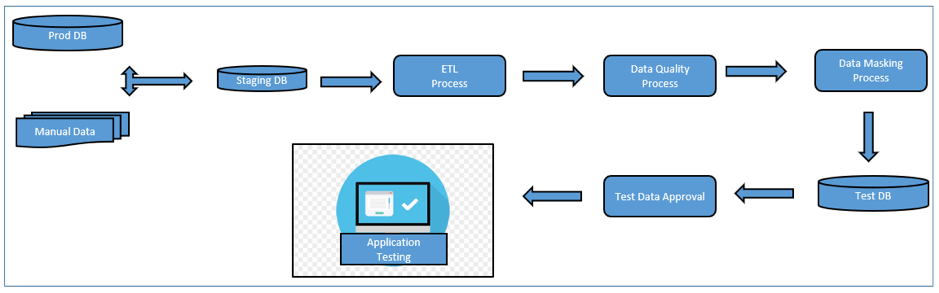
従来のアプローチでは、本番データのコピーを作成し、アプリケーションに応じてマスキングして関連性を評価した上でテストデータとして使用していました。このテストデータには、データの準備、管理、利用のためのテストデータ管理 (TDM) システムが付随していることがほとんどです。これらすべてのオーバーヘッドと手作業によるアプローチは、結果的に遅延をもたらします。 次の図は、本番データからテストデータを作成するという歴史的なアプローチを示しています。本番データは、収集、クリーニング、メンテナンスを経て、機密データを隠すためにマスクされます。各プロセスは手動で行われ、独自の入口と出口の基準を持っているため、時間がかかります。
新時代のアプローチ
この新しいアプローチは、合成テストデータの使用に向けてテスト担当者を惹きつけます。合成テストデータは、本番用データベースからの実際のデータを一切使用せず、選択したアプリケーションのデータモデルに基づいて人工的に生成されます。これらのテストデータ生成(TDG)ツールの最大の特徴は、合成テストデータをオンデマンドで生成できることです。テストケースのニーズに合わせたテストデータのシナリオに合わせてテストデータを生成します。このテストデータ生成ツールのアプローチにより、従来のTDM機能であるデータのマスキングや難読化などの規制遵守ガイドラインに対応した機能が不要になります。このアプローチにより、テストフェーズでの時間を節約することができます。
次の図は、本番データを利用する代わりに、アプリケーションスキーマを使用して、データのマスキングやクリーニングのステップを実行せずにテストデータを生成することができることを示しています。自動化されているため、時間とリソースの両方を節約することができます。

メリット
アプリケーションのテスターは、本番環境から送られてくるデータの品質を制限されています。テスト担当者は、アプリケーションのテストを実行するために、本番環境のデータを使用可能な値に手動で修正しなければならないことがよくあります。一方、合成テストデータは、複雑な本番データのデータサブセットを分析し、テストデータを作成する労力を軽減します。テストデータは、アプリケーションのスキーマモデルに基づいて生成されます。スキーマモデルは、すべての可能なテストケースシナリオをカバーするためのデータ定義と組み合わせを指定します。合成テストデータを生成するこのアプローチは、複雑なスキーマのための時間の消費も削減します。 今日の市場では、複数のソリューションが利用可能ですが、HCLソフトウェアは、テストデータを生成し、継続的インテグレーション (CI) と継続的デリバリー (CD) プロセスをサポートするワンストップソリューションを提供します。CI/CDプロセスでは、自動テストは必須の技術となっています。
HCL OneTest データ
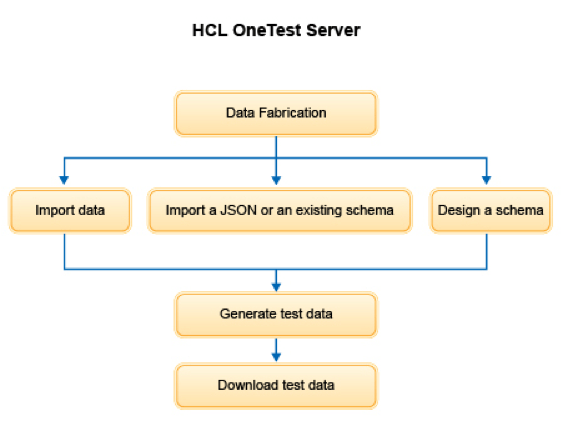
HCL OneTest Data は、コンテナ化されたシンプルで強力なデータ作成ツールです。自動化されたカスタマイズ可能なツールで、テスト環境の合成テストデータを最大限のカバレッジで生成します。HCL OneTest Data は、HCL One Test Serverのコンポーネントの一つであり、HCL OneTest Server GUIのデータファブリケーションとしてアクセスすることができます。大量のリアルタイムテストデータを生成することができ、REST APIを利用してCI/CDプロセスの様々なツールと相互運用することができます。また、KubernetesやRed Hat OpenShiftのアプリケーション開発・デプロイメントプラットフォームにも対応しています。
次の図は、HCL OneTest Data のワークフローを示しています。
機能
セルフサービスと自動化のサポート - HCL OneTest Data は、技術的な専門知識を必要としない完全なGUI駆動のソリューションです。その内部アルゴリズムを使用することで、学習、使用、テストデータの自動生成が簡単に行えます。また、生成されたデータタイプとデータを一致させるための強力なビルトインAPIを提供します。
異種ファイル形式のサポート - HCL OneTest Data は、Excelファイル、ネイティブファイル、カンマ区切り値 (CSV) 、JavaScriptオブジェクト記法 (JSON) 、拡張可能なマークアップ言語 (XML) など、様々なファイル形式でテストデータを生成します。
外部データベースのサポート - HCL OneTest Data は、JDBC、SAPアプリケーション、MongoDB、Excelファイルなどの外部データベースとの相互作用をサポートしています。この機能を使用することで、任意の外部データベースのデータモデルを使用してテストデータを生成することができます。
テスト実行サイクルの短縮 - テストデータはアプリケーションテストの中核となるコンポーネントであり、テストデータを手動で作成するのは時間がかかります。HCL OneTest Data を使用すると、アプリケーションのテストを実行するために、短時間で大量のインテリジェントなデータを生成することができます。
データリスクやセキュリティ問題はありません - 本番システムから実際の情報や潜在的に機密性の高い情報を抽出すると、データ侵害につながる可能性がありますが、HCL OneTestでは、スキーマに適用される内部アルゴリズムに基づいて合成データを生成しています。このアプローチを使用することで、データ漏洩やプライバシー問題のリスクなしに、あらゆるアプリケーションをテストすることができます。
柔軟性と最大のパフォーマンス - HCL OneTestは、テストのニーズに応じてデータをモデル化する柔軟性をサポートしています。この機能は、事前に定義された、またはリアルタイムのデータ生成の効率と精度を向上させるのに役立ちます。シングルテナンシーとマルチテナンシーの両方をサポートしています。
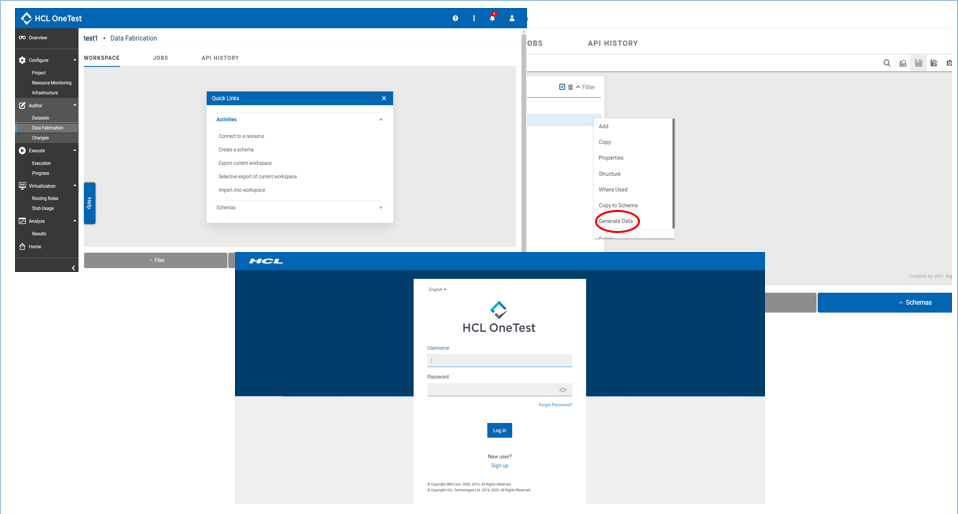
また、HCL OneTest Data は、REST APIを使用してテストデータ生成のためのデータモデリングを実行する機能も提供しています。下図は、HCL OneTest Data のサンプル画面です。
テストデータの生成は、ソフトウェアテストの一つの側面です。テストデータの作成は、テストフェーズの中でも時間のかかる作業であり、ソフトウェア開発全体の中でも主要なコスト負担の一つとなっています。テストデータ生成ツールを使用することで、テストの道における障害を克服することができます。
HCL OneTest Data の詳細については、こちらをご覧ください。
Accelerate: データ駆動型 DevOps パート4: ビジネス・アジリティ
2020/10/9 - 読み終える時間: 2 分
Data-Driven DevOps Part 4: Business Agility の翻訳版です。
データ駆動型DevOpsパート4:ビジネス・アジリティ
2020年10月9日
著者: Steve Boone / HCL Software DevOps Head of Product Management
シリーズの過去のパート
- Accelerate: データ駆動型 DevOps パート 1: 序章
- Accelerate: データ駆動型 DevOps パート 2: データ駆動型の文化
- Accelerate: データ駆動型 DevOps パート 3: データを使った追跡と計画
私がウェビナーやブログ記事、プレゼンテーションの中で、ビジネスの俊敏性についてよく話しているのを聞いたことがあると思います。それは、HCL Software DevOps のキャッチフレーズの一部でさえあります。セキュアでデータ駆動型のビジネス・アジリティ。しかし、ビジネス・アジリティとは実際には何を意味し、データ駆動型の DevOps 戦略にどのように適合するのでしょうか?
ビジネス・アジリティとは、ビジネスまたはその構成要素が、安定性を維持するために適応することで変化に迅速に対応する能力のことを指します。この概念は決して新しいものではありません。実際、アジャイル開発のコアとなるアイデアはここから得られます。変化に適応する能力は、アジャイルプロジェクト管理の要であり、アジャイル開発手法の主な利点の一つです。開発チームが時間を有効に使えば、ステークホルダーが求めているものをタイムリーに届けることができる。また、ステークホルダーのニーズが変われば、それに合わせてチームの行動もすぐに変化させることができます。
2020年、企業はコロナウイルスのパンデミックにより、かつてない状況に直面しています。これらの状況は、企業が日々の活動に慣れている方法、特に顧客とのやりとりに大きな混乱をもたらしています。このような荒れた時代を生き抜くためには、データ駆動型のビジネス・アジリティが必要であることは間違いありません。
データ駆動型の DevOps 組織は、何が破壊されているのかを迅速に特定し、コース修正のための迅速で積極的な会話ができるようにすることで、競合他社に対して優位に立っています。多くの個人やビジネス・ユニットが問題の解決策を考え出し、すべての新しいアイデアが優れたものになるわけではなく、また、これらのアイデアの多くが新たな課題を提示することになります。どのようにしてそのすべてを吟味するのか? 問題を修正しすぎたり、修正しきれなかったりした場合、どのようにして認識するのでしょうか?
データがなければ、このプロセスは推測ゲームであり、新しいプロセスのテストに多くの無駄な時間を費やし、失敗する可能性があります。適切なデータがあれば、より早く失敗することができるので、より早く成功にたどり着くことができます。成功している組織は、偉大になるためには失敗しなければならないという考えを受け入れる文化を持って、早く失敗するという考えを受け入れています。失敗を早くして、その失敗を認識すればするほど、失敗はすぐに学習の機会となります。ヘンリー・フォードは、「失敗とは単に、もう一度やり直す機会であり、今回だけはもっと知的に」と言いました。これこそが、まさにデータ駆動型 DevOps の目標なのです。
このシリーズのパート 2 では、ソースコード管理やワークアイテム管理技術に由来する、個々の貢献者によって生成されたデータが、組織全体の文化や、利害関係者への成果物を正確に予測する能力の向上にどのように役立つかについて議論しました。ビジネスの俊敏性については、継続的インテグレーションやデプロイメントソリューションからテストの自動化やセキュリティスキャンの結果に至るまで、さまざまな DevOps テクノロジーから得られるデータに焦点を当てていきます。これらのデータをキャプチャし、可視化し、処理することができる組織は、以下のことが可能であることに気づくことでしょう。
- アイデアから顧客まで、現在のエンドツーエンドのソフトウェア・デリバリー・プロセスをベンチマークする
- 既存または新たに作成されたボトルネックの特定
- 新しいプロセスの変更やアイデアの影響を理解し、迅速に失敗して混乱を回避できるようにします。
究極のフィードバックループと継続的改善
ソフトウェア・デリバリ・パイプラインから送られてくるデータを可視化して分析することで、組織は貴重な「高速フィードバック」ループを実装するという DevOps のアプローチを取ることができます。多くの企業にとって、日々の業務をオーバーホールする機会は、年に一度か二度しかありません。これは単に十分なスピードではありません。文化的にも、私たちは日々向上していくことを受け入れなければなりません。そのためには、まず、現在の業務のベースライン、つまり現在のパフォーマンスのベンチマークを確立する必要があります。そのベンチマークが決まれば、データのライブ表示がリアルタイムのバリュー・ストリームとなり、組織は改善の余地があるところに焦点を当てることができます。
リアルタイム・バリュー・ストリームには、多くの優れた利点があります。最も明白な利点の1つは、特定の作業単位を追跡し、それをスプリント、リリース、チーム、および個々の貢献者に関連付けることができることです。この作業をバリューストリームの特定のステージに結びつけることができるので、作業が行き詰っている場所を簡単に発見することができます。
このような隠れたボトルネックのお気に入りの例の一つは、HCL Software の自社開発チームの一つにありました。このチームは、コードレビューに悩んでいました。彼らは、コードをマージする前に行わなければならないコードレビューのバックログを常に大量に抱えているようでした。バリュー・ストリームのデータを可視化することで、作業が行き詰った段階を正確に見ることができ、納品プロセスにボトルネックを作っていました。彼らはコードレビューを行うことに長けていましたが、システム内のコードレビューを承認する権限を与えられた人が十分にいなかっただけでした。それは取るに足らない利益のように見えるかもしれませんが、私たちのソフトウェア開発プロセス全体に散らばっている無駄のポケットが何十もあります。それらを取り除くことができればできるほど、馬からユニコーンへの移行のための道が開ける可能性が高くなります。
プロセスの変更と混乱
チームが現在の価値の流れを評価し始めると、現在のプロセスを合理化するための多くの創造的な 方法を思いつくでしょう。その中には良いものもあれば悪いものもあるかもしれませんが、重要なのは、チームとビジネスの両方が新しいプロセスの変更の結果を追跡して、スループットの増加があったかどうかを判断することができるということです。これにより、新しいプロセスを導入したことで、実際に高品質のソフトウェアをより早く、より早く提供できるかどうかを知ることができます。
このように大量のデータがあれば、すべてが意見である必要はありません。データは、会話から「私はそう思う」を取り除き、「私たちは知っている」に変えます。個人が「2週間のスプリントから1週間のスプリントに移行してから、私たちの方がうまくいっていると思います」と言うのではなく、データを調べて確かなことを知ることができます。これは、私たちが話していた文化についての対話に戻ってきます。チームが自分たちのプロセスを定義することを信頼しているのであれば、チームが自分たちのミスから学ぶのを助けるツールを提供する必要があります。これは、エンジニアリングチームがスピードを上げすぎて品質が低下することを防ぐと同時に、エンドツーエンドのプロセスが可能な限り堅牢で効率的であることを確認するためのものです。
データ駆動型 DevOps の旅にご参加いただき、ありがとうございました。これまで、データ改善の文化をどのように改善するか、ソフトウェア配信の追跡と計画をより効率的にし、組織にビジネスの俊敏性をもたらし、潜在的な混乱に迅速に対応できるようにするかについて見てきました。次回の記事では、すべてのデータを一堂に集めて、ビジネスの整合性についてこれまでにない可視性を提供することについてお話ししますので、ご期待ください。また、データがどのようにしてリスクを軽減し、組織をガバナンスの自動化への道へと導くのかについてもお話しします。
Accelerrate: データ駆動型 DevOps パート 3: データを使った追跡と計画
2020/10/9 - 読み終える時間: 2 分
Data-Driven DevOps Part 3: Track and Plan with Data の翻訳版です。
データ駆動型 DevOps パート 3: データを使った追跡と計画
2020年10月7日
著者: Steve Boone / HCL Software DevOps Head of Product Management
シリーズの過去のパート
応答性の高い、高度にアジャイルな開発組織を持つことに伴う課題は、ビジネス、顧客、自社のチームからの多数の要求を常にこなすことです。これにより、与えられたスプリント内で現実的に達成できる以上の作業を議論し、優先順位をつけなければならなくなります。スクラム、カンバン、エクストリームプログラミングからアダプティブ、ダイナミック、リーンソフトウェア開発に至るまで、チームは何年にもわたって多くの方法論を使ってトラッキングと計画を改善しようとしてきました。それぞれのアプローチは、予測可能でありながらも柔軟性があるという同じ課題に異なるひねりを加えています。
データは、開発チームの追跡と計画の能力において重要な役割を果たすことができます。前回の記事では、データが開発チーム全体のコラボレーションとコミュニケーションをどのように向上させることができるかについて説明しました。具体的には、チームがスプリントごとに作成したデータを分析することで、何がうまくいっていて何がうまくいっていないのかを特定するためのプロセス改善に関する会話が促進されることがわかります。文化を超えて、データ分析には、組織の追跡と計画の能力にいくつかの利点があります。
チームの速度を特定することで計画を改善する
スクラムチームにとって、ベロシティとは、チームが1回のスプリントでどれだけの作業に取り組めるかを示す指標であり、スプリントで配信されたストーリーポイントの数を合計して計算されます。チームのベロシティを知ることは、特定のスプリントやリリースの計画を立てるのに役立つだけでなく、組織全体や顧客とのコミュニケーションを改善するのにも役立ちます。
チームのベロシティを理解することは、意味のある期待値を設定するのに役立ちます。計画されたリリースの数週間前に、納品が予定されていたアイテムのうち、一握りのアイテムが届かないことに気付いたことは何度ありますか?それはいつもガッカリです。透明性を高め、混乱を減らすためには、利害関係者や顧客との間で意味のある現実的な期待値の設定が必要です。そして、この同じ透明性は、個々の貢献者が設定された目標の達成に成功する可能性を高めることになります。
リードタイム、サイクルタイム、スループットなど
組織の正確な予測能力を大幅に向上させることができる指標は、ベロシティだけではありません。リードタイムとサイクルタイムは、開発チーム、プロダクトマネージャ、およびリリースエンジニアが、組織を通じてソフトウェアを提供するのにかかる時間を理解するために追跡する最も一般的な統計量です。この 2 つの指標の違いは微妙です。
-
リードタイムとは、新しいタスクがバックログに表示されてから最終的に「完了」となるまでの期間のことです。多くのチームはリードタイムを定義する別の方法を使用するでしょう。そうでなければ、新しいタスクが優先順位を付けられる前に数ヶ月間バックログに残っている可能性があり、それがリードタイムを膨らませる可能性があります。
-
サイクルタイムとは、誰かがリクエストやタスクの作業を開始した瞬間から始まり、作業が完了するまでの期間を指します。
これらの測定基準はどちらも強力なものです。キャパシティをよりよく理解するのに役立つだけでなく、チームの現在の作業プロセスや、現在のワークフローのボトルネックを示す貴重な情報を提供してくれます。
しかし、リードタイムとサイクルタイムだけでは十分ではありません。これらを単独で解釈した場合、チームが特定のスプリントやリリースでどのような作業を完了できるかについて多くの疑問が残ります。これらの質問に対する答えをよりよく理解するために、スループット、分布、コントリビューターなどのデータ内で見られるさまざまな指標に注目しています。
-
スループットとは、与えられた期間に完了したタスクや作業項目の数のことです。これは、ストーリーポイントを考慮するベロシティとは異なります。
-
ディストリビューションとは、タスク、欠陥、機能など、スプリントのために完了した作業の種類の詳細な内訳です。
-
コントリビューターとは、与えられたスプリントに参加している開発者の数です。10人の開発者で構成されたチームが、常に10人の開発者が貢献しているとは限りません。休暇や病気、そして多くの種類の予定外の作業があるため、この数はかなり一貫性のないものになる可能性があります。
正確に成果物を予測しようとするときには、これらすべての指標を考慮することが重要です。 開発チームのリードタイム、サイクルタイム、ベロシティ、スループット、貢献者の平均数、および典型的な分布を知ることで、作業がいつ完了すべきか、そして最も可能性の高い作業の種類をより正確に把握できます。
リスクの特定
もちろん、どのチームでも時折、何らかの配送の遅延が発生することがあります。このようなシナリオでは、何をリリースの範囲から外すべきか、外すべきではないかについて、組織が計算された情報に基づいた意思決定を行うことが重要です。開発チームのデータを分析することの主な利点の1つは、特定のタスクをビジネス価値に結びつけることができるようになることです。開発用語で言うと、これはエピックス(ビジネス価値)と作業項目(タスク)をリンクさせることを意味します。
このリンクを作成することで、あるビジネス価値のうち、何%が完成しているかを把握し始めることができます。この情報は、リスクを特定し、ステークホルダーや顧客に伝え、意味のある期待値を設定する上で非常に貴重なものです。納品物が抜け落ちたときはいつでも、「なぜこの作業を完了できなかったのか」、「チームはこの納品物の他に何に集中していたのか」など、いくつかの質問が出てくることでしょう。これらの質問に対する答えは、データの中に見つけることができます。進行中の作業が多すぎたのかもしれないし、サポートの問題でチームが脇道にそれてしまい、予定していた作業から遠ざかってしまったのかもしれません。答えが何であれ、データを分析することで、開発チームはより意味のある回顧を行い、プロセスを調整して、同じ間違いが将来発生しないようにすることができます。
データ駆動型の DevOps は非常に強力です。これまでに、コミュニケーションとコラボレーションを改善することで文化を向上させる方法について説明してきましたが、データを活用することで、ビジネス価値の追跡と計画をより効果的に行うための能力を磨くことができる重要な方法をいくつか紹介してきました。次回は、データが組織のビジネス・アジリティ(安定性を維持するために適応することで変化に迅速に対応するビジネスの能力)をどのように向上させることができるかについてお話しします。