
HCL Unica Campaign リスナーのクラスタリングとリスナーのフェイルオーバーについて - パート 2
2024/9/4 - 読み終える時間: ~1 分
Understanding Campaign Listener Clustering and Listener Failover - Part 2 の翻訳版です。
HCL Unica Campaign リスナーのクラスタリングとリスナーのフェイルオーバーについて - パート 2
クラスター化されたリスナー環境
Campaign にクラスター化されたリスナー設定が導入されたため、集中化されたエンティティからのリクエストが送信される複数の独立して動作するリスナーノードを持つ設定として考える必要があります。各リスナープロセスは、単一のリスナー環境の場合と同じように動作し (詳細については、このブログのパート 1 を参照してください)、マシンのローカルにある unica_acsvr プロセスを独立して起動およびシャットダウンし、独自の unica_aclsnr.udb ファイルを維持します。各リスナーノードは情報を共有しません。「マスターリスナー」が管理しているにもかかわらず、それらは個別の独立した単一のリスナーノードのように動作します。クラスター化された Campaign リスナー設定がどのようになるか、次の図に示します。
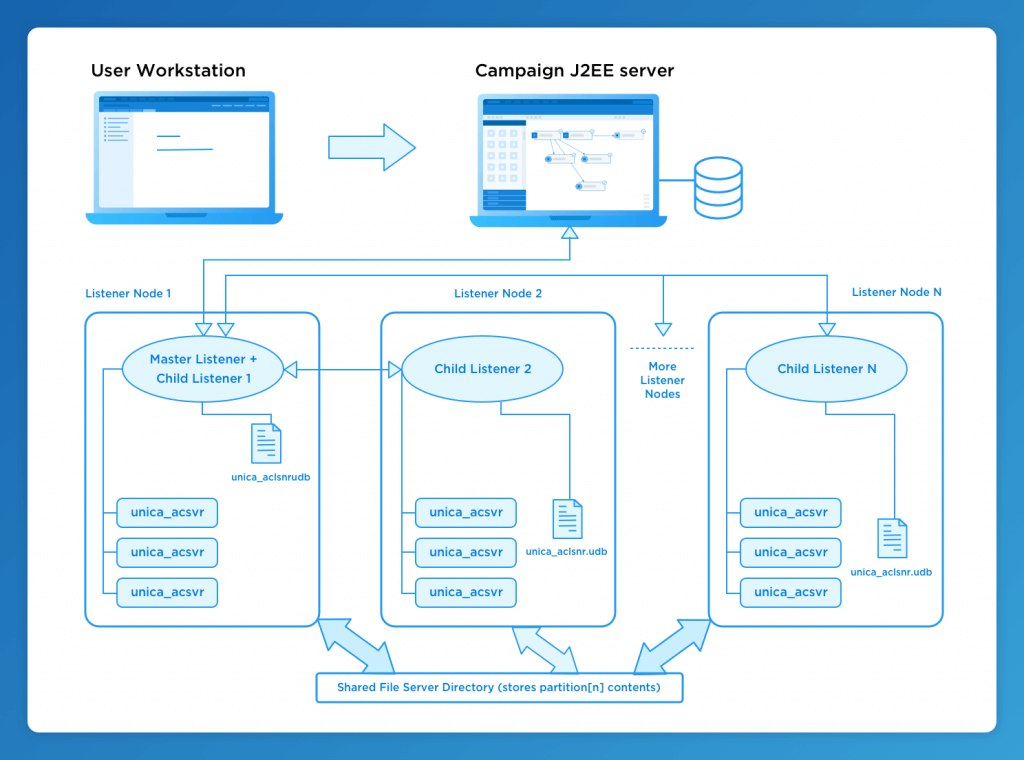
マスターリスナープロセスをロードバランサーとして考えます。 Campaign J2EE Web アプリケーションサーバーから Campaign にログインするか、フローチャートを表示/編集/実行する要求が届くと、Campaign Web アプリケーションは特定のリスナーと通信してこれを行うのではなく、クラスター化されたセットアップ内のマスターリスナーにそれらの要求を渡します。
次に、マスターリスナーは構成設定を確認して、どの子リスナーノードがこのタスクを実行するかを判断します。マスターリスナーがどの子リスナーノードが要求を受け取るかを決定すると、要求はその子リスナーノードに渡されます。
その時点で、その特定のマシン上の子リスナーノードは、非クラスター化されたセットアップで実行されている単一のリスナーノードであるかのように要求を処理します。適切な unica_acsvr プロセスが生成され、それらの unica_acsvr プロセスが要求されたアクションを実行します。次に、リスナーノードは unica_aclsnr.udb のローカル コピーを更新して、管理している unica_acsvr を認識します。
クラスター内の他の子リスナーは、他の子リスナーが何に取り組んでいるかを把握していません。すべてのアクティビティは、単一の子リスナーノードにローカライズされます。子リスナーノードは、管理している unica_aclsnr.udb ファイルから相対的なローカル unica_acsvr 情報を通信または共有することはありません。一部のユーザーリクエストが 1 つの子リスナーノードに送信され、他のユーザーリクエストが別の子リスナーノードに送信される場合があり、これらはすべて、環境の構成設定に基づいてワークロードを管理/バランスするためにマスターリスナーによってそれらの子リスナーノードに分散されます。
では、リスナーが使用できなくなり、フェイルオーバーが必要になった場合、これはどのように機能するのでしょうか。マスターリスナーが 2 つ以上の子リスナーノードを管理している場合、ビジネスユーザーから UI 経由で送信されるリクエストは、それらの子リスナーノード間で負荷分散されます。これらのリスナーノードの 1 つが手動介入またはその他のイベントによってダウンした場合、流入する新しいリクエストは、マスターリスナーによって、機能しているシステム内の残りの子ノードに転送されます。これらは別のマシンで動作しますが、同じシステムテーブルデータベース情報とファイル サーバー コンテンツ (共有ディレクトリ内) に引き続きアクセスできます。フロントエンドのビジネスユーザーにとって、ビジネスは通常どおりに進行し、ダウンタイムは発生しません。これは、他のリスナーノードがダウンしている場合でも、リクエストを受信できる稼働中のリスナーノードが少なくとも 1 つ残っているためです。IT チームは、フロントエンドのビジネスユーザーを混乱させることなく、舞台裏でダウンした子リスナーノードを調べることができます。マスターリスナーは、Campaign J2EE Web アプリケーションサーバーからのリクエストをリダイレクトする際に、スイッチを切り替えて、常に残りの稼働中のリスナーノードを指すようにします。ダウンしたリスナーノードが復旧すると、マスターリスナーは以前と同様に、そのノード (および他のノード) にリクエストを送信し始めます。
ここで、リスナーの 1 つがダウンし、そのリスナーでフローチャートとログインセッション unica_acsvr がすでに実行されているとします。その場合、何が起きるでしょうか。子リスナーノードの 1 つがダウンすると、マスターリスナーは新しいリクエストを他の子リスナーノードに転送しますが、リスナーノードがダウンしたマシンで以前から実行されていた unica_acsvr は、単一のリスナーセットアップのように動作します。フローチャートロジックはある程度まで実行し続けるかもしれませんが、そのマシンのリスナーがなくなるため、UI の更新やそれ以降の UI クリックは実行されない可能性があります。リスナーがダウンしても、unica_acsvr プロセスはリスナーノード間で転送されません。つまり、ノード A のリスナーがダウンすると、ダウン時に存在していた管理対象の unica_acsvr プロセスは他のリスナーノードで開始できなくなります。代わりに、フローチャートにアクセスするための新しい UI 要求を通じて、他のリスナーノードで再起動を手動で行う必要があります。
マスターリスナーノードが存在するマシンが使用できなくなった場合、Campaign は中断を回避するために、残りの子リスナーノードの 1 つを新しいマスターリスナーノードとして使用するように自動的に切り替えます。
要するに、クラスター化されたリスナー設定では、フェイルオーバーとは、リスナーノードがダウンまたはダウンしているときに、unica_acsvr プロセスの起動時に新しい要求が来た場合、常に実行中の子リスナーノードに転送されることを意味します。ダウンしたリスナーノードで実行されていた unica_acsvr プロセスは回復できません。ユーザーは、UI (フリーズしている可能性があります) からログアウトして、稼働中の子リスナーノードの 1 つで新しい Campaign ログインセッションを確立する必要があります。
ブログの最初の部分は、こちらで読むことができます - HCL Unica Campaign リスナーのクラスタリングとリスナーのフェイルオーバーについて - パート 1
クラスター リスナー設定の構成プロパティの詳細については、Unica ブログを購読して最新情報を入手してください。