Amazon Redshift データベースで HCL Unica Campaign を設定する
2020/10/5 - 読み終える時間: 10 分
Configuring HCL Unica Campaign with Amazon Redshift Database の翻訳版です。
Amazon Redshift データベースで HCL Unica Campaign を設定する
2020年10月1日
著者: Omkar Pathak / Technical Lead at Unica

最近のマーケターは、これまで以上にデータの活用に関与し、熟練しています。顧客情報は中央データベースから収集、保存、検索され、指数関数的に増加しています。それはマーケターがより具体的でターゲットを絞ったマーケティングコミュニケーションを行い、ユーザーにとってよりパーソナライズされた体験を創造することを容易にします。しかし、データベースの管理や処理は簡単な作業ではなく、クラウドデータベースやDaaS(Database as a Service)プラットフォームが企業に普及してきています。その中で知られているのが Amazon Redshift です。
Amazon Redshift とは?
Amazon Redshift は、大規模なデータセットの保存と分析のために設計されたフルマネージドのペタバイト規模のクラウドベースのデータウェアハウス製品です。クラウド型のデータベースサービスを利用するのが現在のトレンドであり、HCL Unica Campaign ではそのようなサービスとの連携に精通しています。本記事では、Amazon ODBC Driver を利用して、HCL Unica Campaign を Amazon Redshift をユーザーデータベースとして利用するための設定がどのように簡単にできるのかをご紹介します。

前提条件として必要なもの
Amazon Redshift データベースで Unica の設定を開始するには、以下の前提条件が必要です。
Amazon Redshif tデータベースと統合する必要がある HCL Unica Campaign アプリケーション。
- Amazon Redshift の詳細: クラスタ名、データベース名、ユーザーID、パスワード(Amazon Redshif tの契約時にこれらの詳細を取得します。
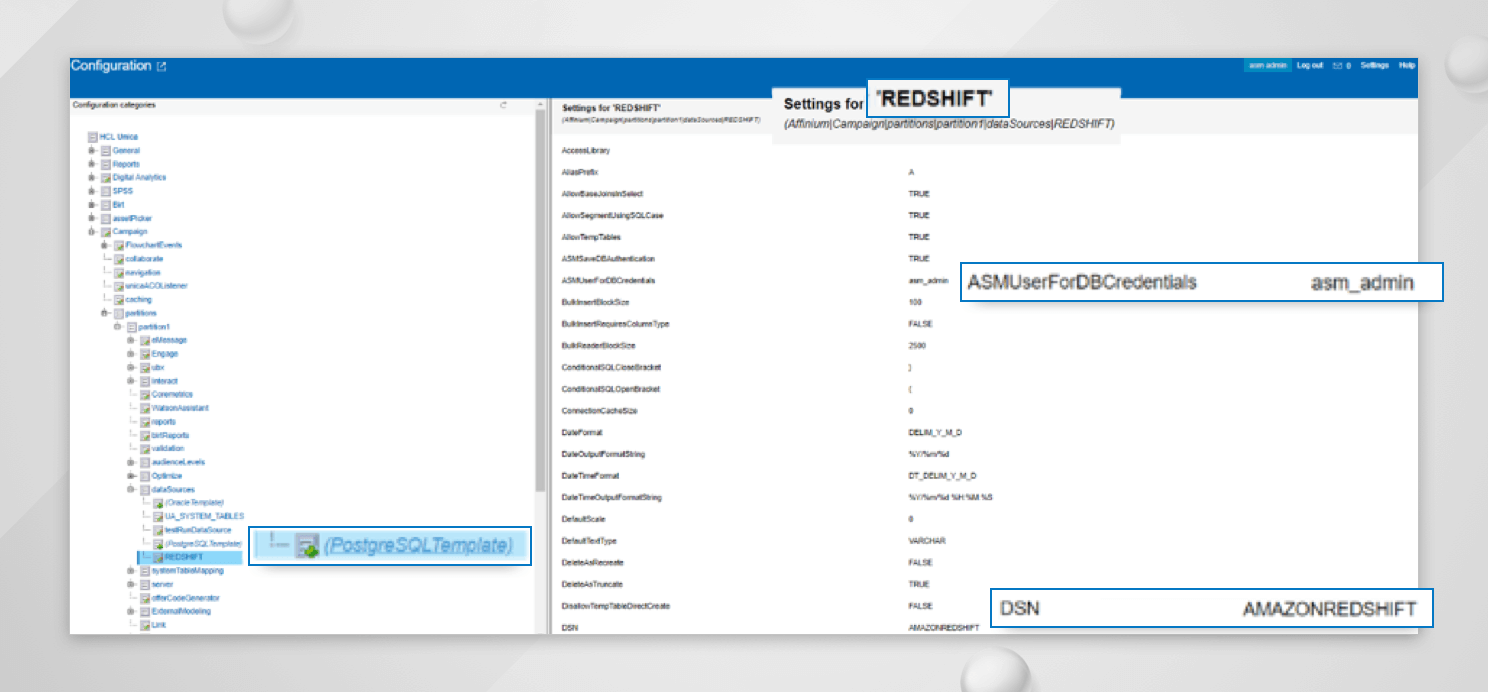
- Unica UI の Settings -> Configuration のノード「Affinium|Campaign|partitions|partition1|dataSources」で、「(PostgreSQLTemplate)」のデータソーステンプレートが既に追加されていることを確認し、このテンプレートを使用してデータソースを作成できるようにしてください。
- HCL Unicaスイート が Unix ベースの OS にインストールされている場合は、Unica Campaign リスナーがインストールされているサーバに unixODBC 2.3.x をインストールしてください。
サポートされているODBCドライバ
Unica Campaign を Amazon Redshift データベースと統合するには、PostGreSQL ODBC ドライバまたは Amazon ODBC ドライバを使用できます。より良いパフォーマンスとデータベースに関連するすべての機能を利用するには、Amazon ODBC ドライバの使用をお勧めします。理想的には Amazon から入手可能な最新の ODBC ドライバを使用する必要があります。
古い ODBC ドライバは、Amazon 自体がサポートしていません。そのため、サポートされている Amazon ODBC ドライバのバージョンを使用していることを確認する必要があります。現在、Amazon ODBC v1.4.11.1000 が提供されており、Unica Campaign との連携が可能です。これは、Unica Campaign のリスナーが動作しているサーバーにインストールして設定する必要があります。
Amazon ODBC ドライバのインストール方法
Amazon ODBC ドライバをダウンロードしてインストールするには、Amazon が公開している以下のリンクを参照してください。
https://docs.aws.amazon.com/redshift/latest/mgmt/configure-odbc-connection.html
Amazon ODBC ドライバをインストールするために使用できるコマンドの一覧です。
-
RHEL オペレーティングシステム
wget https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.11.1000/AmazonRedshiftODBC-64-bit-1.4.11.1000-1.x86_64.rpm yum --nogpgcheck localinstall AmazonRedshiftODBC-64-bit-1.4.11.1000-1.x86_64.rpm -
Suse Linux オペレーティングシステム
wget https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.11.1000/AmazonRedshiftODBC-64-bit-1.4.11.1000-1.x86_64.rpm zypper install AmazonRedshiftODBC-64-bit-1.4.11.1000-1.x86_64.rpm
デフォルトでは /opt/amazonの 下にインストールされます。
- Windows オペレーティングシステム
以下のリンクから .msi ファイルをダウンロードしてインストールしてください。
odbc.iniファイルの設定
Windows 以外のサーバでは、 odbc.ini という名前のファイルを作成する必要があります。以下は odbc.ini ファイルのサンプルです。
[AMAZONREDSHIFT]
Driver=/opt/amazon/redshiftodbc/lib/64/libamazonredshiftodbc64.so
Host=unica-redshift-cluster.redshift.amazonaws.com
Port=5439
Database=amazondb
Username=awsuser
Password=Password
locale=en-US
BoolsAsChar=0上記の例では、ホスト、ポート、データベース、ユーザー名、パスワードのエントリを Amazon から受け取った通りに変更する必要があることに注意してください。
Windows OS では、以下のリンクを参照して、"ODBC Datasource Administrator (64-bit)" の下にシステム DSN を追加する必要があります。
上記の例では、AMAZONREDSHIFT が DSN 名になっています。
Unica UI で必要な変更
-
テンプレートを使用して、"Affinium|Campaign|partitions|partition1|dataSources "の下にデータソースを作成します。PostgreSQLTemplate を使用します。
-
- 追加した Datasource については、フィールド DSN の値を、非 Windows OS の場合は odbc.ini ファイルで定義したものと、Windows OS の場合は「ODBC Datasource Administrator (64-bit)」で追加したシステム DSN の名前と同じにしておきます。上記の例のように odbc.ini を設定している場合、DSN の値は AMAZONREDSHIFT に設定する必要があります。
-
User ? asm_adminの下にDatasource 資格情報を追加するか、フィールド ASMUserForDBCredentials の下に定義されたユーザを追加します。
-
- Windows 以外の OS の場合は、<キャンペーンホーム>/binディレクトリで setenv.sh ファイルを編集し、LD_LIBRARY_PATH環境変数に /opt/amazon/redshiftodbc/lib/64 のパスを追加します。また、環境変数 ODBCINI が ODBC.INI ファイルの絶対パスに設定されていることを確認してください。
例
接続性をテストするには
Amazon Redshift データベースへの接続性をテストするには、
cxntest を使う
-
キャンペーンリスナーがインストールされているサーバーのコマンドプロンプトから<キャンペーンホーム>/bin ディレクトリに移動します。
-
setenv.sh/setev.bat を実行します。
-
cxntest ユーティリティを実行します。
-
libodb4dDD.so " を提供します。
-
接続ライブラリ?"プロンプトに "libodb4dDD.so "または "libodb4d.so " をん入力してください。
-
- 設定通りに Datasource Name, UserName, Password を提供します。プロンプト「>」が表示されたら、データベースに正常に接続されていることを示します。
[root@server bin]# ./cxntest
Connection Library? libodb4dDD.so
Registered Data Sources:
Data Sources
AMAZONREDSHIFT
Data Source? AMAZONREDSHIFT
User ID? awsuser
Password? Password
>odbctest の使用
-
キャンペーンリスナーがインストールされているサーバーのコマンドプロンプトから<キャンペーンホーム>/binディレクトリに移動します。
-
setenv.sh/setev.bat を実行します。
-
- odbctest ユーティリティを実行します。
-
- サーバー名、ユーザー名、パスワードを設定通りに入力します。プロンプト「>」が表示されたら、データベースに正常に接続されていることを示しています。
[root@server bin]# ./odbctest
Registered Data Sources:
AMAZONREDSHIFT (/opt/amazon/redshiftodbc/lib/64/libamazonredshiftodbc64.so)
Server Name? AMAZONREDSHIFT
User ID? awsuser
Password? Password
Detected Data Direct compatibility
Server AMAZONREDSHIFT conforms to LEVEL 2.
Server's cursor commit behavior: PRESERVE
Transactions supported: ALL
Maximum number of concurrent statements: 1
For a list of tables, use PRINT.
>また、Windows 以外のサーバで "isql -v AMAZONREDSHIFT " コマンドを使用して接続をテストできます。"ODBC Datasource Administrator (64ビット) on Windows OS " から直接接続をテストします。
Amazon Redshift Loader を設定するには (オプションステップ)
デフォルトでは、Unicaは大量のデータをロードするためにBULK INSERTを利用しています。BULK INSERTよりも優れたパフォーマンスを利用したい場合は、"COPY "コマンドの実装を使用してamazon redshiftローダを利用できます。Amazon Redshiftデータベース側でのローダーの動作を理解するには、チュートリアルを参照してください。
AWS側でのローダーに関する設定
AWSサポートに連絡して、以下の手順を行う必要があります。
-
AWS 側に S3 バケットを作成します。
-
AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY を集めてAWS データベースに接続します。
-
Unica Campaign Listener がインストールされているサーバーに AWS Cli ユーティリティをインストールします。
-
aws configure コマンドでS3バケットに接続するために必要な設定を行う必要があります。
上記の手順が完了したら、コマンドプロンプトから直接以下のテストを行う必要があります。
データファイルをS3バケットにコピーする場合 (ここでは、
copy <TABLE> from 's3://s3bucketaws/<DATAFILE Name>' credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' csv;
テーブルへのデータの読み込みは、任意のツールからデータベースに接続し、以下のコマンドを実行します。
DATAFILE=$1
TABLE_NM=$2
export S3BUCKET=[Change me]
export AWS_ACCESS_KEY_ID=[Change me]
export AWS_SECRET_ACCESS_KEY=[Change me]
export DSNNAME="AMAZONREDSHIFT" #Change this value as per your odbc.ini
ERR_CD=1
LOG_FILE="/tmp/log.$$"
FILE_NM=`basename $1`
S3_FILE=$S3BUCKET$FILE_NM
echo "file to copy is $1"
echo aws s3 cp $1 $S3BUCKET >> $LOG_FILE 2>&1
aws s3 cp $1 $S3BUCKET >> $LOG_FILE 2>&1
RESULT=$?
if [ ${RESULT} -ne 0 ]; then
echo "ERROR in aws s3 cp" >> $LOG_FILE
exit $ERR_CD
fi
COMMAND="COPY $TABLE_NM FROM '$S3_FILE' CREDENTIALS 'aws_access_key_id=$AWS_ACCESS_KEY_ID;aws_secret_access_key=$AWS_SECRET_ACCESS_KEY' csv"
echo $COMMAND > /tmp/sql.$$
isql $DSNNAME < /tmp/sql.$$
RESULT=$?
echo "RESULT is $RESULT"
if [ ${RESULT} -ne 0 ]; then
echo "ERROR in COPY" >> $LOG_FILE
exit $ERR_CD
fi
# remove file from s3?
aws s3 rm $S3_FILE
echo "LOG_FILE is $LOG_FILE"
exit 0上記のコマンドをコマンドプロンプトから直接 (Unicaからではなく) テストに成功したら、Unica 側で必要な設定を行っていきます。万が一、上記の手順のテストで問題が発生した場合は、AWS のサポートに連絡して、上記のテストが成功しているかどうかを確認してください。
さて、2つの引数を受け入れるシェルスクリプトを作成する必要があります。DATAFILE PATH と TABLENAME です。このスクリプトが正常に実行され、コマンドプロンプトから直接実行されたときにテーブルにデータをロードできることを確認してください。以下にサンプルローダースクリプトの例を示します。
HCL Unica側での構成
ローダースクリプトを
loaderCommand = /opt/Unica/campaign/partitions/partition1/scripts/amazonload.sh <DATAFILE> <TABLENAME>
loaderCommandForAppend = /opt/Unica/campaign/partitions/partition1/scripts/amazonload.sh <DATAFILE> <TABLENAME>
loaderDelimiter = ,
loaderDelimiterForAppend = ,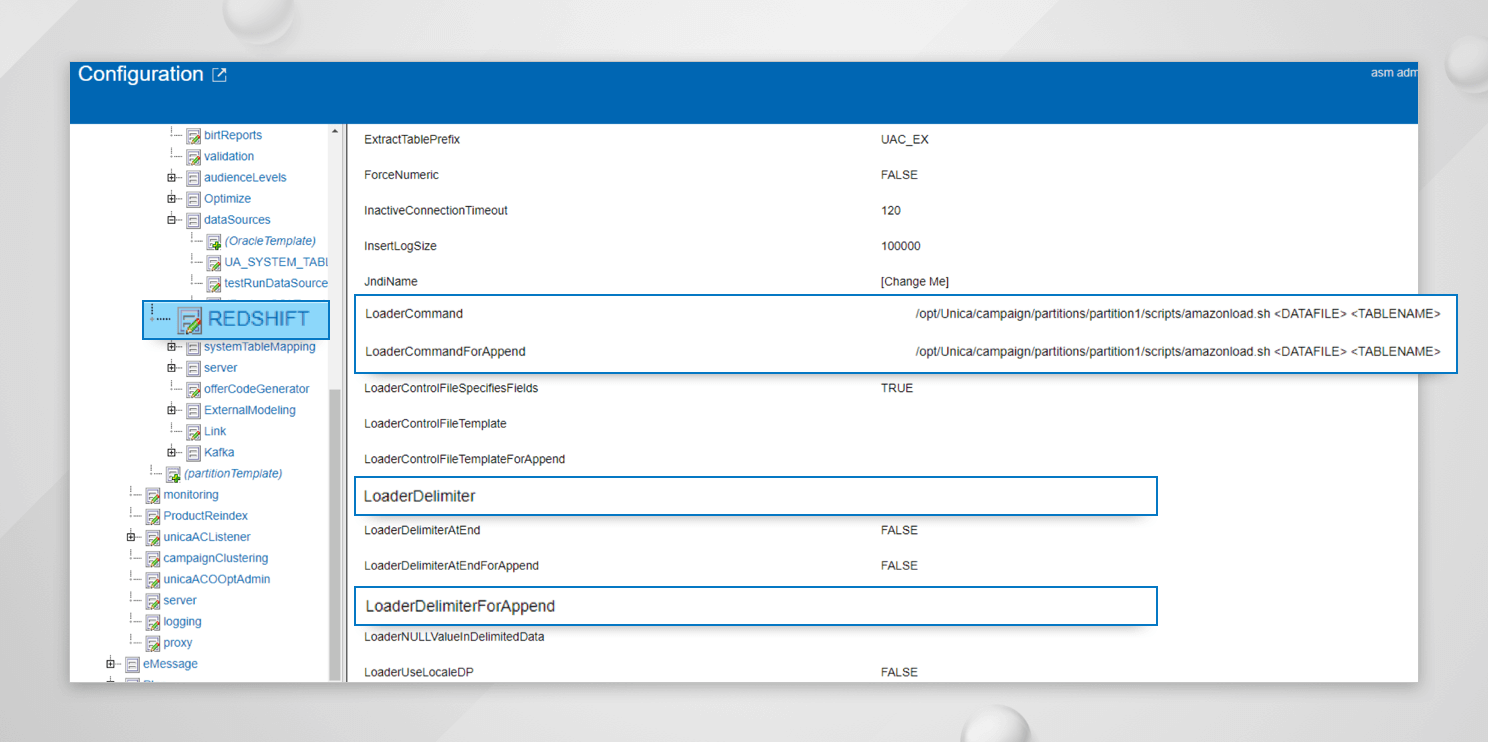
ODBC トレースを有効にするには
何らかの問題をトラブルシューティングしたい場合、ODBC トレースレベルのロギングを有効にする必要がある場合があります。トレースレベルのロギングを有効にするには、以下のように /opt/amazon/redshiftodbc/lib/64 の下にある "amazon.redshiftodbc.ini "というファイルを更新する必要があります。
[root@server 64]# cat amazon.redshiftodbc.ini
[Driver]
## - DriverManagerEncoding is detected automatically.
## Add DriverManagerEncoding entry if there is a need to specify.
ErrorMessagesPath=/opt/Campaign/redshift_odbc_logs
LogLevel=6
LogPath=/opt/Campaign/redshift_odbc_logs
SwapFilePath=/tmpLogLevel=6 は、トレースレベルのロギングが有効であることを示しています。LogPath と ErrorMessagesPath には、任意のフォルダの場所を指定できます。トレース・レベル・ロギングを無効にするには、LogLevel を 0 に更新する必要があります。 トレース・レベル・ロギングを有効にするには、"ODBC Datasource Administrator (64-bit) on Windows OS "から行うことができます。
いくつかの既知の問題があります。
-
Amazon ODBC Driver v1.4.3.1000 は Amazon Redshiftデータベースでの BULK INSERT をサポートしていません。これは、このバージョンのドライバの制限です。
-
Amazon ODBC Driver v1.4.4.11.1000 では、Snapshot や Extract などのアウトバウンドプロセスボックスで Flowchartname や Cellcode などのキャンペーン生成フィールドをエクスポートしている場合、そのようなフィールドのデータ型は BOOL とみなされ、フローチャートの実行に失敗します。この問題を解決するには、 odbc.ini ファイルに "BoolsAsChar=0" を追加する必要があります。
-
PostGreSQL v9.6.5 を使用して Amazon Redshift データベースに接続している場合、プロセスボックスに表示されている挿入/更新されたレコードの数が、実際に影響を受けた数と一致しないことがあります。これは PostGreSQL v9.6.5 の既知の問題です。誤ったカウント表示の問題を回避するために、Unica で v9.03.0100 の使用をお勧めします。
-
PostGreSQL ドライバ(すべてのバージョン)は、Amazon Redshift データベースでの BULK INSERT をサポートしていません。これはこのドライバの制限です。
Amazon Redshift では、スケーリングが容易で、何千もの同時クエリが実行されている場合でも、Unica Campaign との相性が良く、一貫して高速なパフォーマンスを提供します。Amazon Redshift と Unica Campaign の統合についての詳細は、弊社までお問い合わせください。