
2023 バリューストリームマネジメントの動向のまとめ
2024/3/31 - 読み終える時間: ~1 分
2023 Value Stream Management Trends: A Recap の翻訳版です。
2023 バリューストリームマネジメントの動向のまとめ
2024年3月13日
著者: Ryley Robinson / Project Marketing Manager
顧客への価値提供を成功させるためには、企業の開発、オペレーション、ビジネス意思決定チーム全体のコラボレーションと可視化が不可欠です。
2023年秋、弊社は様々な職種、業界、グローバル拠点にまたがる10,000人以上のプロフェッショナルを対象に調査を実施しました。本レポートは、この広範な調査から得られた知見に光を当て、現状を俯瞰したものである。VSMがまだ発展途上であることを考えると、数多くの組織が日々価値を失っていることに気づく。この現象をより深く理解するために、HCLSoftwareはバリューストリームマネジメントに関連するトレンドを分析する広範な調査を実施しました。
回答者からは、企業が現在直面している課題や、価値に対する責任をどのように組織化し、分担しているのかについて、多くの洞察を得ることができました。また、その回答から、企業が将来的にどのような方向へ進もうとしているのかも見えてきた。
それでは、トレンドレポートから主なハイライトをいくつか紹介しよう:
バリューストリームはどこにでもある
調査では、具体的に特定された、あるいは明確に名付けられたバリュー・ストリームに沿っているかどうかを尋ねた。回答者の半数(50%)が「はい」と答えた。これは、バリュー・ストリームが今日の組織ではかなり一般的であることを示している。
企業はバリューストリームに沿った組織化によって利益を得ている
コラボレーションの改善」が35%でトップだった。コラボレーションの向上は、ワークフローの円滑な統合、意思決定の迅速化、そして最終的には顧客への価値提供の効率化につながります。
チームは複雑な自前のダッシュボードに頼っている
自前のダッシュボードやレポーティング・ソリューションを構築しようとしたことがあるかという質問に対して、回答者の80%が「はい、ビジネス・インテリジェンス(BI)」を選択した。カスタムメイドのダッシュボードは、特定のニーズやワークフローに合わせてカスタマイズされます。ダッシュボードは、リアルタイムの洞察、分析、パフォーマンス指標をチームに提供し、データ主導の意思決定と継続的な改善を可能にします。
ユーザーはフローを改善するための実用的な洞察を必要としている
今日の組織において、ユーザーが直面する主な課題の1つは、バリューストリームマネジメントのためにアウトプットを使用する能力です。アンケートでは、回答者の40%がこのように報告しています。VSMのためのアウトプットを持たないことは、組織の効率性を低下させ、顧客のニーズを効果的に満たすことができません。
2023 VSM Trends Report の全文をご覧いただき、2023年の業界シフトと2024年までの展望に関する独占情報を入手してください。また、データについてより深く理解するために、次回のウェビナーにお申し込みください。
HCL DevOps Velocityは、データ駆動型のバリューストリーム管理プラットフォームであり、データの配信と解釈を自動化することで、ビジネスがより迅速かつ戦略的な意思決定を行い、プロセスを合理化できるようにします。すでに使用しているツールと統合することで、HCL DevOps VelocityはDevOpsパイプライン全体からデータを集約し、実用的なインサイトを提供するため、DevOps投資を最大限に活用できます。HCL DevOps VelocityはHCLSoftware DevOpsの一部であり、強力で業界実績のあるソフトウェアソリューションの包括的なDevOps製品スイートです。

HCL DevOpsCode RealTime 1.0.1 でリアルタイム開発の可能性を引き出す
2024/3/31 - 読み終える時間: ~1 分
Unlocking the Potential of Real-Time Development with HCL DevOpsCode RealTime 1.0.1 の翻訳版です。
HCL DevOps Code RealTime 1.0.1 でリアルタイム開発の可能性を引き出す
2024年3月26日
著者: Ryley Robinson / Project Marketing Manager
HCL DevOps Code RealTimeの最新バージョンのリリースを発表できることを嬉しく思います。この最近のリリースでは、コミュニティ・エディションとコマーシャル・エディションの両方で、いくつかの重要な改善が行われています。
今回のアップデートの目玉は、Target Runtime Systemの構築、デバッグ、カスタマイズに関する新しいドキュメントです。このガイドは、ランタイム環境の複雑さを簡素化し、アプリケーションを最適なリアルタイム性能に微調整するための明確なロードマップを開発者に提供します。
強化された検証機能による開発の効率化
バージョン1.0.1では、HCL DevOps Code RealTimeは、ソフトウェア品質のレベルを引き上げるために、いくつかの検証機能強化を導入しています。新しいルールは、トランジションにおけるトリガーの欠落や予期せぬトリガーを検出し、ダイアグラムにおける検証問題の表示はより正確になりました。
洗練されたコード生成と構成編集
このリリースでは、コードジェネレータの使用と変換構成の編集が強化されています。エラーと警告のレポートの改善は特に重要で、開発者が問題をすばやく特定して対処する上で重要な役割を果たします。明確で効率的なフィードバック・メカニズムに焦点を絞ることで、開発者は問題の修正よりも技術革新に集中することができます。
バージョン1.0.1のもう1つの特徴は、QTを使用して開発されたUIと生成されたコードを統合する方法、依存性注入を実装する方法、JSONエンコーディングを適用する方法を説明する新しい例です。
結論として、HCL DevOps Code RealTimeバージョン1.0.1は、開発プロセスを最適化し、運用効率を向上させ、高品質なリアルタイム・アプリケーションを確実に提供することを目的とした一連の機能拡張を導入しています。
このリリースの詳細と全リストは、HCLSoftware のウェブサイトをご覧ください。HCL DevOps Code RealTimeは無料のコミュニティ版を提供しており、VS Code Marketplace と Open VSX Registry で入手可能です。ご質問や詳細については、code-realtime@hcl-software.com までお問い合わせください。

HCL DevOps Velocity 5.0 のご紹介
2024/3/27 - 読み終える時間: 2 分
Introducing HCL DevOps Velocity 5.0 の翻訳版です。
HCL DevOps Velocity 5.0 のご紹介
2024年3月27日
Ryley Robinson / Project Marketing Manager
HCLSoftwareは、HCL DevOps Velocityの最新リリースであるバージョン5.0を発表できることを嬉しく思います。新機能、機能強化、統合を満載したこのリリースは、かつてないほどDevOpsプロセスを合理化するように設計されています。
2023.12(5.0.0)の新機能
- ベンダー固有のプロパティの追加:バリュー・ストリームのベンダー固有のプロパティを表示することで、より深い洞察が得られます。
- プラグイン・インデックスのプロキシ:プラグインのインデックス URL に対するプロキシ設定のサポートが強化され、シームレスな統合が可能になりました。
- DevOps Research and Assessment (DORA) メトリクス:変更リードタイム、プロダクションデプロイメントカウント、サービス復旧時間(MTTR)などのDORAメトリクスでチームのパフォーマンスを評価します。
- ステータスゲート:新しいステータスゲート機能の追加により、デプロイメントをより詳細に制御できます。
- 開発サイクルタイム:新しい開発サイクルタイム機能により、ビジネス固有のメトリクスをカスタマイズできます。
- Aha! プラグイン:Aha!アプリケーションをVelocityと統合して、顧客価値に基づいて作業の優先順位を設定できます。
- 新しい検索機能:DQL検索を使用して、ビジネス価値に基づいてバリューストリームドットをフィルタリングします。
- マイルストーンリスク見積もりプラグイン:新しいマイルストーンリスク見積もりプラグインを使用して、スプリント完了リスクを評価します。
2023.12 (5.0.1)の新機能
- バリュー・ストリームの強化: 改善された可視化オプションにより、スプリントとリリースのデータを簡単に追跡および分析できます。
2023.12の新機能 (5.0.2)
- ServiceNow 自動タスクの強化:Velocityアプリケーションから、ServiceNow変更リクエストを作成および更新しながら、ServiceNow変更タスクを作成および更新できます。詳細については、このページを参照してください。
- ステータスゲートの表示:各ゲートのルールと指定承認者のカウントを表示できます。詳細については、このページを参照してください。
- イベントの表示:リリース]ページの[イベント]タブに作成されたイベントがない場合に、[イベントが見つかりません]というメッセージを追加しました。
HCL DevOps Velocity 5.0は、チームがよりスマートに、より速く、より正確に作業できるようにします。HCL DevOps Velocityには、開発者、運用管理者、DevOpsの実務担当者など、すべての人に役立つ機能が用意されています。HCL DevOps Velocityで導入された機能、機能強化、その他の変更に関する完全なリストと詳細情報を入手するには、ここをクリックしてください。
DevOpsの旅を加速させる準備はできていますか?HCLSoftwareのウェブサイトをご覧いただき、無料のコミュニティ版をお試しください!
-min.jpg)
HCL DevOps Code ClearCase セミライブリフォーマット VOB (SLRV) のすべて
2024/1/22 - 読み終える時間: 17 分
All About HCL DevOps Code ClearCase Semi-Live ReformatVOB (SLRV) の翻訳版です。
HCL DevOps Code ClearCase セミライブリフォーマット VOB (SLRV) のすべて
2024年1月17日
著者: Avinash Srinivasamurthy / Senior Technical Specialist
このブログ記事では、HCL DevOps Code ClearCase 3.0.1で利用可能なセミライブリフォーマットVOB(SLRV)機能の詳細について説明します。以下のトピックを取り上げます。
- セミライブ reformatVOB(SLRV)を使用する理由
- 標準の reformatvob がどのように機能するか - 図による説明
- セミライブ再フォーマットVOB(SLRV)の動作-図解による説明
- セミライブ再フォーマットVOB(SLRV)と標準再フォーマットVOBの比較
セミライブ再フォーマットVOB(SLRV)を使用する理由
SLRVを使用してVOBを再フォーマットする主な利点は以下の通りです。
- SLRVは次のような優れたソリューションを提供します
- 新しいスキーマ・レベルへの VOB の更新
- データベースのクリーンアップ
- SLRV は、より短いロック時間で VOB を再フォーマットする能力を提供します。
- SLRVでは、再フォーマットのダンプとロードのプロセスはバックグラウンドで行われます。SLRVでは、再フォーマットのダンプとロード処理はバックグラウンドで行われます。
- SLRVは、チームがVOBをロックし、最終的なカットオーバー処理を実行する準備ができた時点で完了できます。
標準的な再フォーマット VOB の仕組み
SLRVの仕組みに入る前に、標準的なreformatvobの仕組みとその主な問題点について簡単に説明します。
次の図はVOBに対して行われる標準的なreformatvobの動作を表しています。
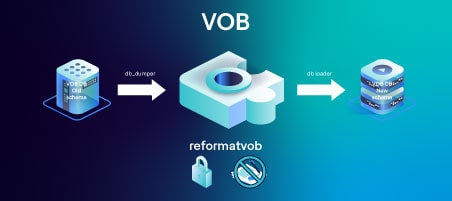
- db_dumperは現在のスキーマを読み込み、いくつかのテキストファイルにデータを出力します。
- db_loaderはこれらのテキストファイルを読み、新しいスキーマにデータを書き込みます。
- このプロセスが終了すると、ディレクトリが入れ替わり、新しいスキーマを持つ新しいデータベースが使用できるようになります。
- reformatvobプロセスは大規模なデータベースではかなりの時間を要します。
- このプロセスの間、VOBはロックされ、使用できません。
- UCM環境では、コンポーネントVOBが1つでも使用できない場合、そのUCMプロジェクトですべてのUCM操作が使用できなくなります。
セミライブ再フォーマットVOB(SLRV)の仕組み
セミライブ再フォーマットVOBプロセスは、2つのステージで動作します。
- ステージ1:セミライブreformatVOBプロセスの開始
- ステージ2:セミライブリフォーマットVOBプロセスの完了
ステージ 1:セミ・ライブ再フォーマットVOBプロセスの開始
この最初のステージでは、SLRVはコマンドを発行することにより、指定されたVOBに対して開始される: cleartool reformatvob -semilive <vob_stg_path
下図は、この段階で実行されるタスクを表しています。
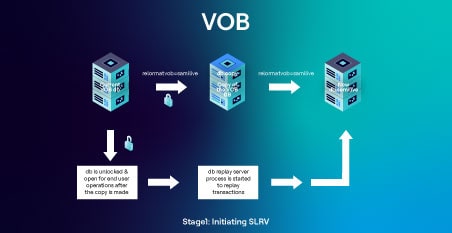
- reformatvob -semilive操作は、そのデータベースをスキーマ・レベル55(元のdbがスキーマ54の場合)またはスキーマ・レベル81(元のdbがスキーマ80の場合)に静かにアップグレードします。
- その後、VOBはロックされます。
- 既存のデータベース(VOBのdbディレクトリだけ)がdb.copyにコピーされます。
- その後、VOBはロック解除されます。
- コピーされたデータベースはダンプされ、db.semiliveにロードされる。
- db_replay_serverプロセスが開始され、現在のVOB dbからデータベースのdb.semiliveコピーにトランザクションを再生する。
- 現在の VOB db はコピーが作成されるとロックが解除されるため、エンドユーザーは VOB 上で作業を続けることができます(ポイント 4)。その結果、エンドユーザーの操作に影響はありません。
- db_replay_serverプロセスは、VOB dbに加えられた新しい変更を、バックグラウンドで新しいdb.semiliveに再生し続けます。
ステージ 2:セミライブreformatVOBプロセスの完了
VOB上で進行中のSLRVを完了させるために、管理者は以下のSLRV completeコマンドを実行します: cleartool reformatvob -semilive -complete <vob_stg_path
下図はSLRV completeコマンド発行後、この段階で実行されるタスクを表しています。
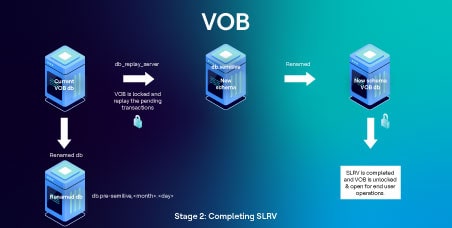
- complete "コマンドが発行されると、エンドユーザーによるそれ以上の変更を防ぐため、VOBは再びロックされます。
- complete "メッセージがdb_replay_serverに送信されます。
- db_replay_serverは、現在のVOB dbから「db.semilive」dbコピーに未処理のトランザクションをすべて再生し、終了する。
- 現在のVOB dbディレクトリは、将来のバックアップと参照用に "db.pre-semilive... "にリネームされる。
- スキーマ81データベースのdb.semiliveは "db "にリネームされ、VOBの新しいアップグレードされたdbとして機能します。
- VOBのロックが解除され、エンドユーザーが使用できるようになり、SLRV操作が完了しました。
- VOBは新しいスキーマにアップグレードされました。
セミ・ライブ再フォーマットVOB(SLRV)と標準再フォーマットVOBの比較
次の表は、セミ・ライブ再フォーマットVOB(SLRV)と標準再フォーマットVOBの方法の比較です。
|
|
比較表 |
|
|
Semi-live reformatVOB (SLRV) |
Standard reformatvob |
|
|
Efficiency |
現在のVOB dbがdb.copyとしてコピーされると同時に、本番VOBのロックは解除されます。 |
VOBはreformatvob操作の間中ロックされたままです。 |
|
db_dumperとdb_loaderはdb.copyに対して動作し、現在のVOB dbに対しては動作しません。 |
db_dumperとdb_loaderは実際のVOB db自体に作用します。このため、VOBはreformatvobが完了するまでロックされたままとなり、エンドユーザーはVOBを利用できないままとなります。 |
|
|
エンドユーザーはコピーが作成されるとすぐにVOBの使用を再開できるため、エンドユーザーの操作への影響は最小限に抑えられます。 |
再フォーマットボブの操作中、VOBはロックされたままなので、エンドユーザーへの影響はより大きくなります。 |
|
|
UCMプロジェクトに対するダウンタイムの影響は最小限です。 |
もしUCMコンポーネントが1つでも標準的なreformatvob(完了までに時間がかかる巨大なVOBを含む)を受けている場合、reformatvobが完了するまでUCMプロジェクト全体がエンドユーザーによって使用できなくなります。 until the reformatvob is complete |
|
|
Flexibility |
管理者は SLRVプロセスをコントロールし、ダウンタイムとエンドユーザーへの影響を考慮して、いつ完了させるかを決定する柔軟性を持っています。 |
一旦reformatvobコマンドが発行されると、管理者とエンドユーザーはreformatvobコマンドとプロセスが完了するまで待たなければなりません。 |
|
管理者とエンドユーザーはreformatvobコマンドとプロセスが完了するまで待たなければなりません。 |
一度標準のreformatvobが開始されると、ダウンタイムやエンドユーザーへの影響を考慮し、後で停止したり完了したりすることはできません。 |
|
|
Operation |
db_replay_serverプロセスは、SLRVが現在のVOBのdbの変更をdb.semiliveコピーに同期させるために作成されます。 |
db_replay_serverプロセスは標準のreformatvobプロセスでは作成されません。 |
|
VOBのdescribe出力に、semilive reformatvob in progress: trueという行があります。semilive reformatvob in progress: true: VOB が SLRV プロセスを実行中であるかいなかの手がかりになります。 |
VOBが標準的なreformatvob処理中かどうかを判断するオプションはありません。 |
|
|
cleartool reformatvob -semilive -status |
標準のreformatvobにはこのようなオプションはありません。代わりに、管理者はreformatvobコマンドの出力に表示されるダンプとロードのメッセージに頼らなければなりません。 |
|
|
SLRVがオリジナルのVOBを完成させると、dbは将来のバックアップや参照用に |
標準のreformatvobは将来のバックアップや参照用に古いデータベースの名前をdb.dateに変更します。 |
|
-min.png)
DevOps Deploy と Argo CD を使った GitOps
2023/12/27 - 読み終える時間: 8 分
GitOps with DevOps Deploy and Argo CD の翻訳版です。
DevOps Deploy と Argo CD を使った GitOps
2023年12月14日
Thomas Neal / Lead Software Engineer I - HCL Continuous Delivery
前提条件
DevOps DeployでArgo CDのデプロイを始める前に、以下の項目を設定する必要があります。
GitHub リポジトリ
デプロイする予定のKubernetesリソース定義ファイルを含むGitHubリポジトリが必要です。
Argo CDサーバ
Argo CDサーバーにアクセスする必要があります。Argo CDのインストール方法については、https://argo-cd.readthedocs.io/en/stable/getting_started/ を参照してください。GitHub リポジトリを参照する Argo CD アプリケーションが Argo CD サーバーに存在する必要があります。
Argo CD CLI
Argo CD CLI を DevOps Deploy エージェント マシンにインストールする必要があります。CLI のインストールについては https://argo-cd.readthedocs.io/en/stable/cli_installation/for の説明を参照してください。
Kubernetes/OpenShift クラスタで動作するコンテナ化された DevOps Deploy エージェントに Argo CD CLI をインストールする場合は、必ず persisted conf ディレクトリにインストールしてください。それ以外の場所にインストールすると、ポッドが再起動されたときに失われてしまいます。また、CLIの実行ファイルに実行権限が設定されていることを確認してください。
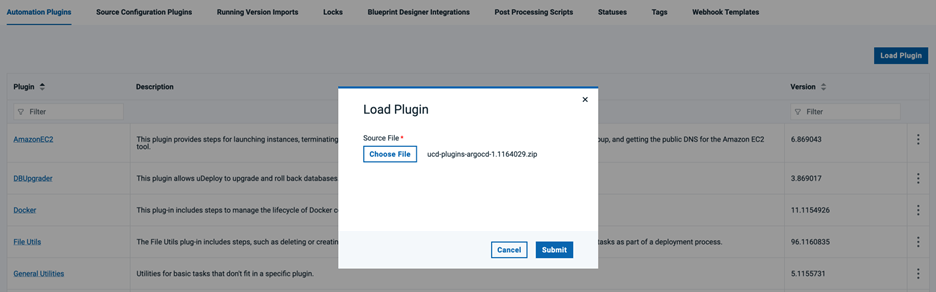
DevOps Deploy Dockerソースと自動化プラグイン
DevOps Deploy Dockerソースと自動化プラグインをDevOps Deployサーバにロードする必要があります。Docker自動化プラグインはソースプラグインに依存しているため、最初にDockerソースプラグインをロードする必要があります。
Dockerソースプラグインはhttps://urbancode.github.io/IBM-UCx-PLUGIN-DOCS/UCD/#docker-registry からダウンロードできます。
Docker自動化プラグインは、https://urbancode.github.io/IBM-UCx-PLUGIN-DOCS/UCD/#docker からダウンロードできる。
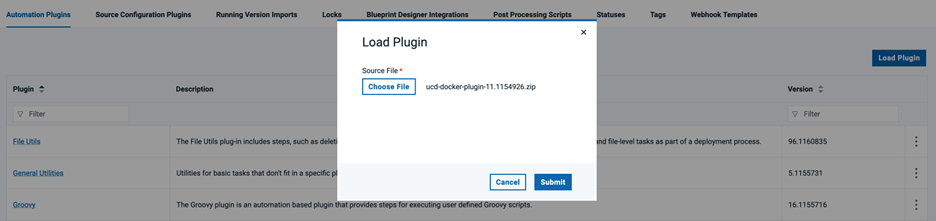
DevOps Deploy Argo CD オートメーションプラグイン
DevOps Deploy Argo CD自動化プラグインをDevOps Deployサーバにロードする必要があります。Argo CD プラグインは https://urbancode.github.io/IBM-UCx-PLUGIN-DOCS/UCD/#argocd からダウンロードできます。
Argo CD アプリケーションの作成
Argo CDサーバにログインし、ソースのGitHubリポジトリとKubernetesリソースをデプロイしたいデスティネーションのKubernetes/OpenShiftクラスタを参照する新しいアプリケーションを作成します。アプリケーションの同期ポリシーを手動に設定します。Argo CDアプリケーションが既に存在する場合は、このステップをスキップできます。
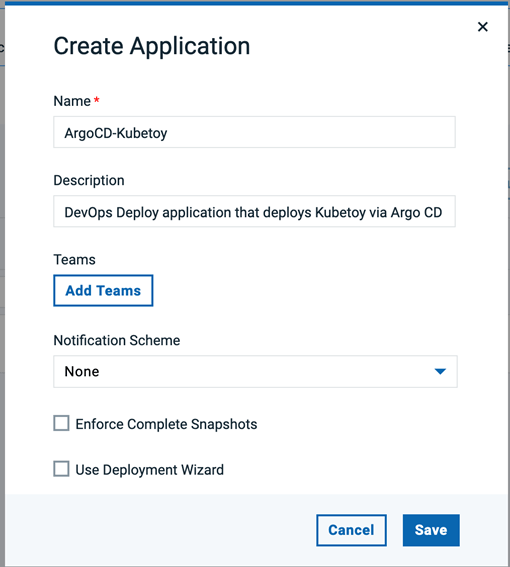
DevOps Deploy アプリケーションと関連リソースの作成
DevOps Deployサーバにログインし、新しいアプリケーションを作成します。このアプリケーションは、Argo CDアプリケーション経由でKubernetesリソースをデプロイするために使用されます。
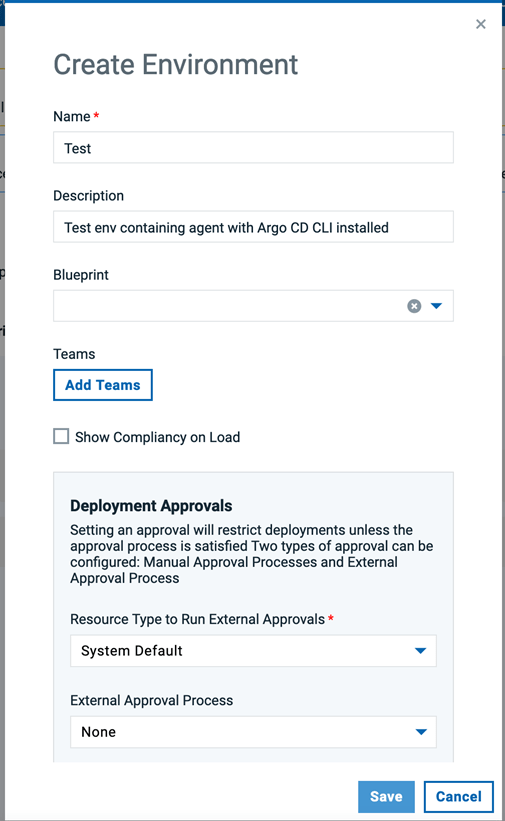
新しいDevOps Deployアプリケーションで環境を作成します。以前にArgo CD CLIをインストールしたDevOps Deployエージェントを、この新しいDevOps Deploy環境のリソースツリーに追加します。
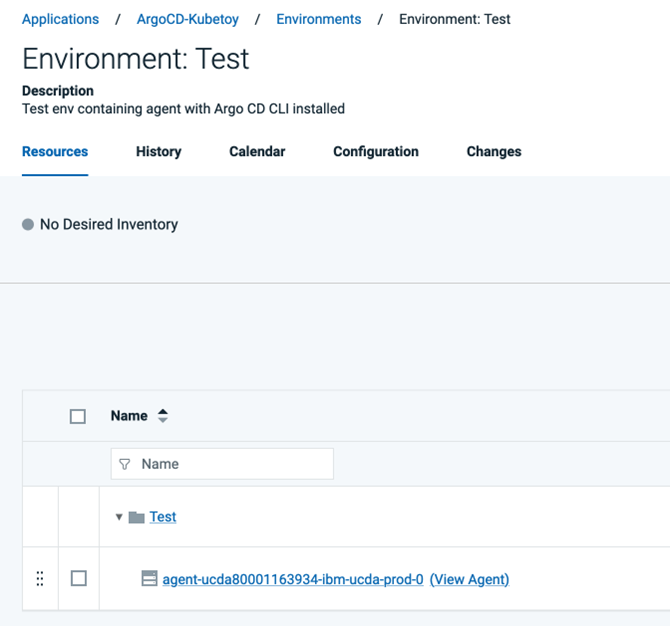
DevOps Deploy コンポーネントの作成
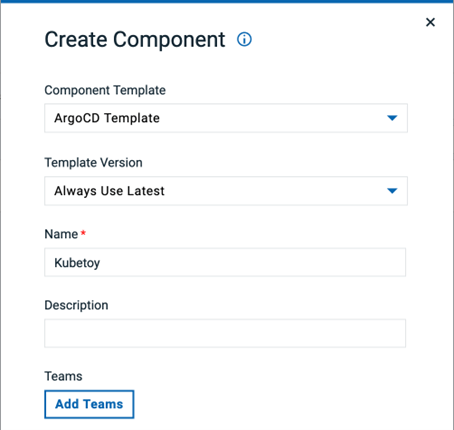
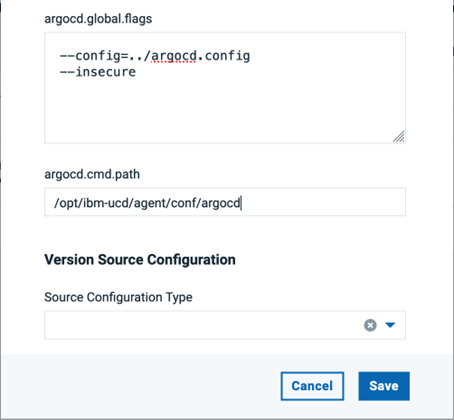
ArgoCD コンポーネント テンプレートを使用して、新しい DevOps Deploy コンポーネントを作成します。argocd.server、argocd.user、argocd.password、argocd.application.name など、必要なコンポーネントのプロパティを入力します。argocd.global.flags フィールドに、-config=../argocd.config --insecure などの必要な Argo CD CLI グローバルフラグを指定します。各グローバルフラグを必ず 1 行で指定してください。Argo CD CLI がエージェントの PATH に含まれるディレクトリにインストールされていない場合は、argocd.cmd.path にその場所を指定します。
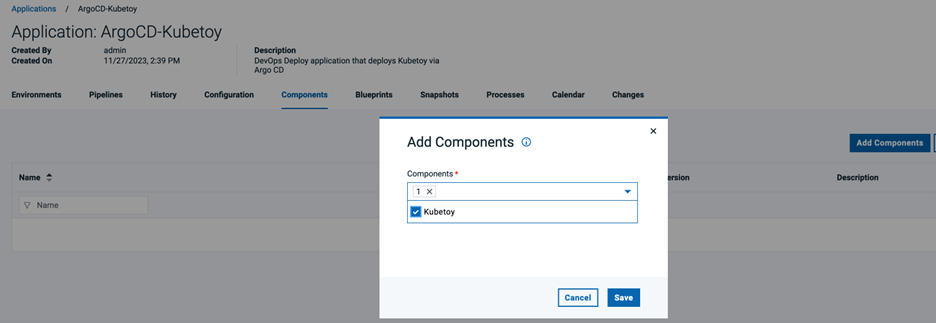
新しいDevOps Deployコンポーネントが作成されたら、それを新しいDevOps Deployアプリケーションに追加する。また、DevOps Deployアプリケーション環境リソースツリーのDevOps Deployエージェントの下に新しいコンポーネントへの参照を追加します。
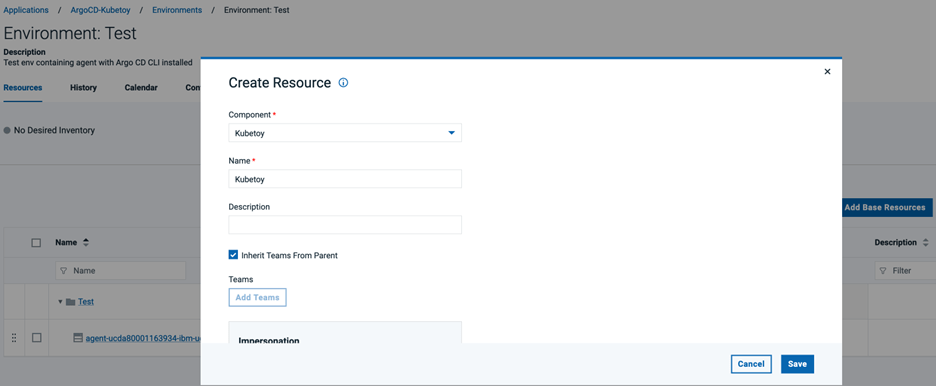
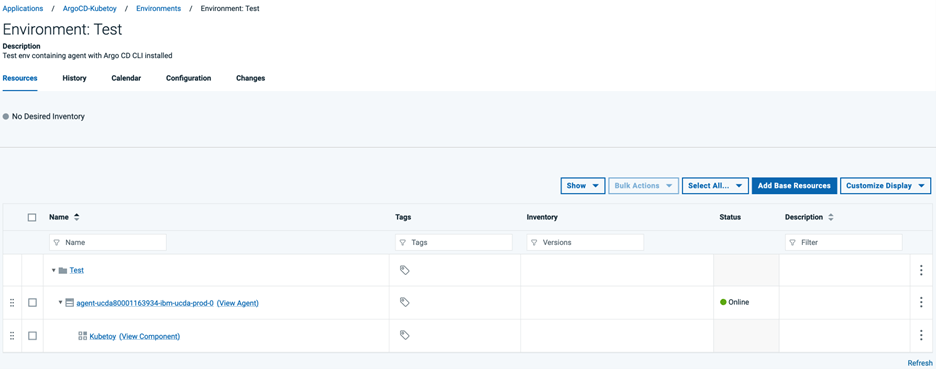
DevOps Deployアプリケーション・プロセスの作成
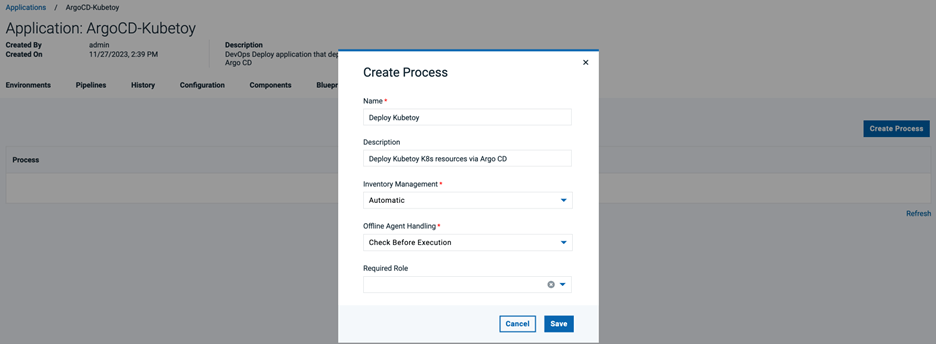
Argo CD サーバにアプリケーション同期要求を送信する新しい DevOps Deploy アプリケーション プロセスを作成します。新しい DevOps Deploy アプリケーションの[Processes]タブに移動し、[Create Process]ボタンをクリックします。Name] フィールドと [Description] フィールドに値を指定し、[Save] をクリックします。
Process Design ペインで、Run Operational Process for Multiple Components ステップをパレットにドラッグします。ステップを編集します。Name] フィールドに Sync And Run Tests を指定します。Component Tag フィールドに ArgoCD を選択します。Component Process フィールドに Sync And Run Tests を指定します。OK ボタンをクリックして、ステップの変更を保存します。Save をクリックして、新しいアプリケーション プロセスのデザインを保存します。
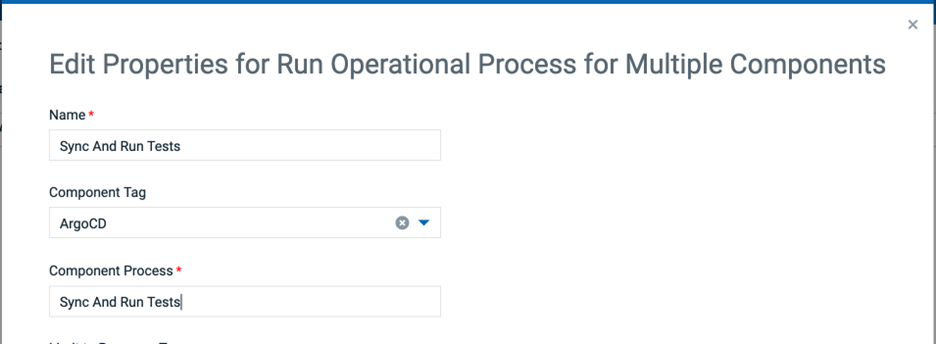
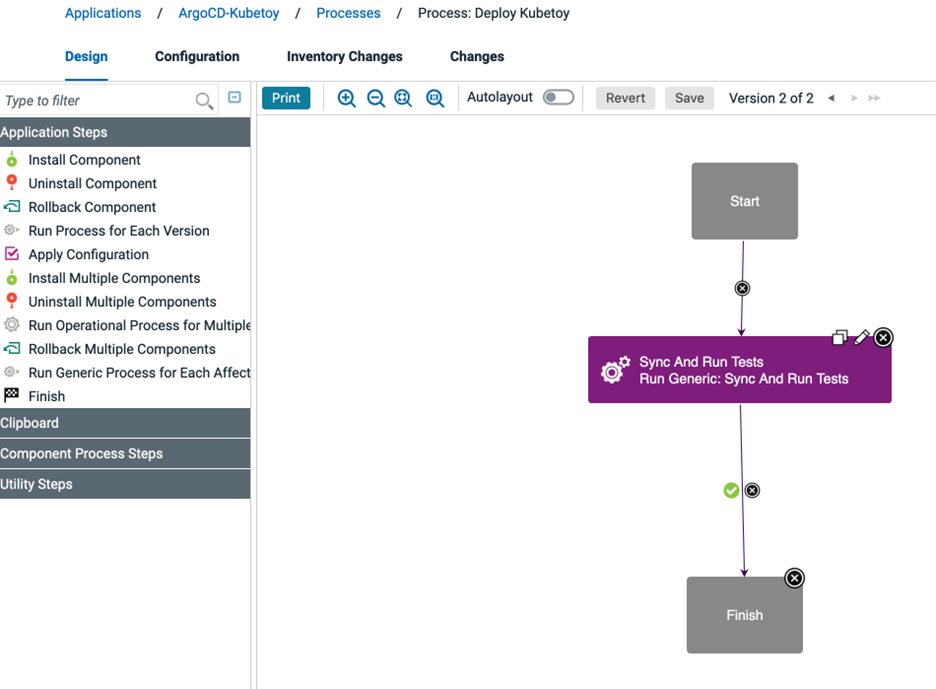
Sync And Run Tests という名前のコンポーネント プロセスが ArgoCD コンポーネント テンプレートに含まれています。Argo CD CLI を呼び出して Argo CD アプリケーションを同期する App Sync ステッ プの後に、Run Tests というシェル ステップがあります。このステップは、Kubernetesアプリケーションが正常にデプロイされたことを検証するために必要なテストを実行するように変更できます。Run TestsステップのステータスがFailureの場合、App Rollbackステップが呼び出され、以前のアプリケーション状態にロールバックされます。Run TestsステップのステータスがSuccessの場合、Sync And Run Testsプロセスは成功したステータスで終了します。
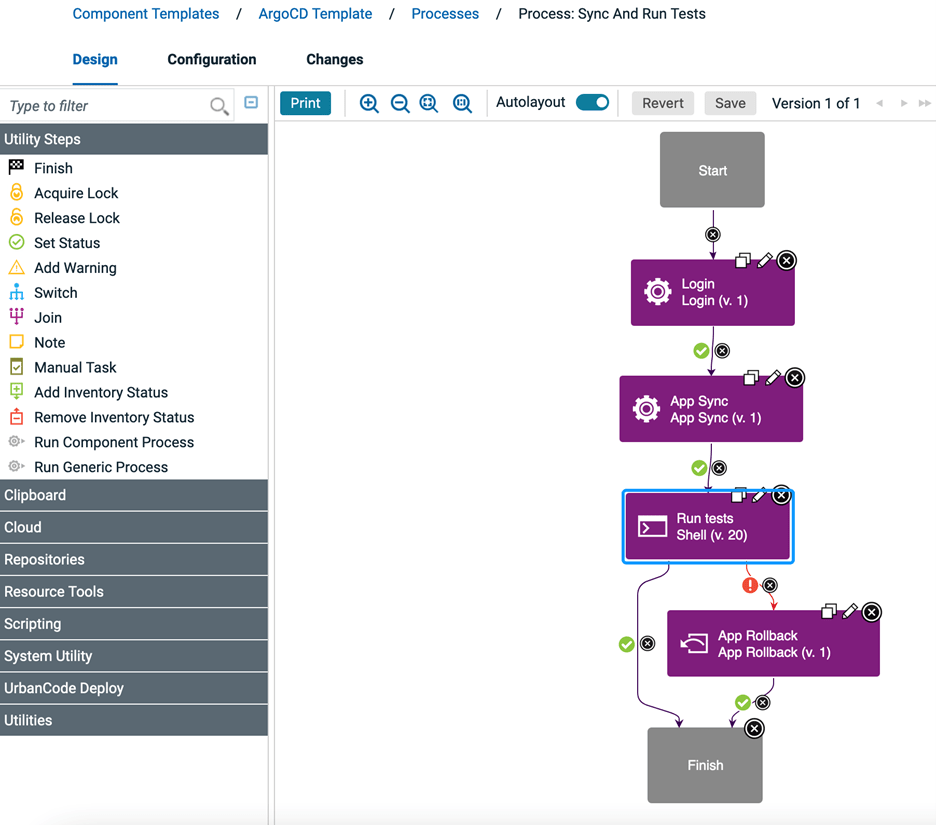
DevOps Deploy デプロイメント・トリガーの作成
アプリケーション・プロセスが作成されたので、アプリケーションに追加したコンポーネントに新しいコンポーネント・バージョンが作成されるたびに呼び出される新しいDeployment Triggerを作成する必要があります。DevOps Deployアプリケーション環境設定を編集する。環境構成のDeployment Triggersセクションを選択し、Create Deployment Triggerボタンをクリックします。上記で作成した新しいDevOps Deployコンポーネントとアプリケーション・プロセス、およびアプリケーション・プロセスを実行するDevOps Deployユーザを指定します。
GitHub リポジトリでの GitHub Actions ワークフローの設定
GitHub リポジトリに、リポジトリのメインブランチに変更がプッシュされたときにトリガーされる新しい GitHub Actions ワークフローを作成します。このワークフローがトリガーされると、新しい DevOps Deploy コンポーネント・バージョンが作成されます。新しいコンポーネント バージョンが作成されると、Argo CD CLI への app-sync 呼び出しを呼び出すアプリケーション プロセスがトリガーされ、GitHub リポジトリで定義された Kubernetes リソースがデプロイされます。
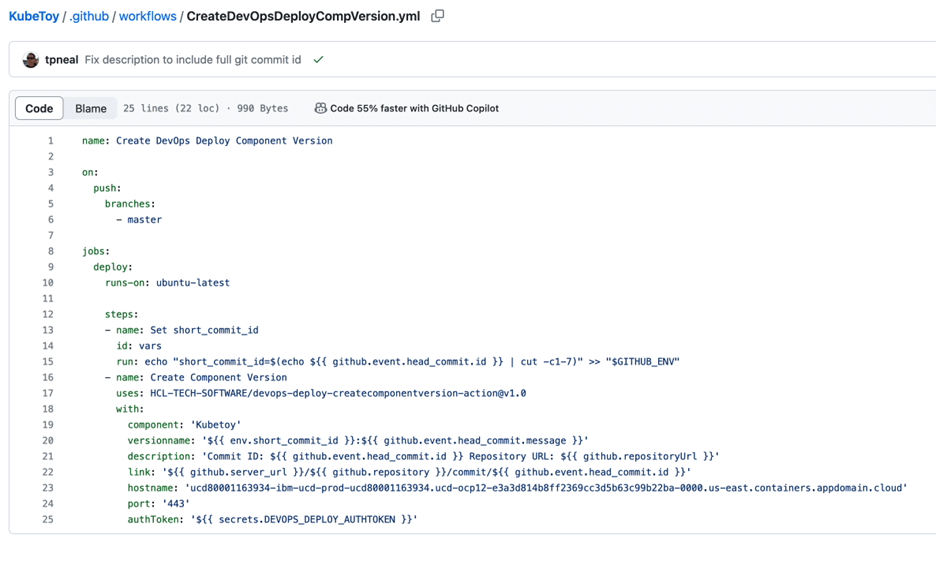
GitHubリポジトリに、.github/workflows/CreateDevOpsDeployCompVersion.ymlという名前の新しいファイルを作成します。内容は、https://github.com/HCL-TECH-SOFTWARE/devops-deploy-createcomponentversion-action の「使用例」セクションから取得する必要があります。
例の以下の入力プロパティを、DevOps Deployインスタンス固有の値で更新します。
- component - DevOps Deployのコンポーネントの名前またはID。
- hostname - DevOps Deployサーバのホスト名またはIP。
- port - DevOps Deployサーバのポート番号。デフォルトは8443。
- authToken - DevOps Deployサーバとの認証に使用する認証トークン。
この例では、DEVOPS_DEPLOY_AUTHTOKENという名前のシークレットを使用しています。このシークレットは、GitHubリポジトリのSettings->Secrets and variables->Actionsで定義されています。
以下のワークフロー例では、変更が master ブランチにプッシュされたときにこの処理を実行するようにしています。GitHub リポジトリで別のブランチを使用している場合は、この値を変更する必要があります。
GitHub リポジトリの更新と変更のデプロイ
これで、GitHub リポジトリの指定したブランチに変更がプッシュされるたびに、DevOps Deploy が Argo CD に対してアプリケーションの同期リクエストを開始するようにすべてが設定されました。Argo CDはどのような変更が行われたかをチェックし、宛先のKubernetes/OpenShiftクラスタに適用します。
GitHubリポジトリ内のKubernetesリソースファイルの1つに変更を加えます。例えば、デプロイメントやステートフルセットのリソースファイルのレプリカカウントを変更し、変更をプッシュします。新しいDevOps Deployコンポーネントのバージョンが作成されていることを確認します。
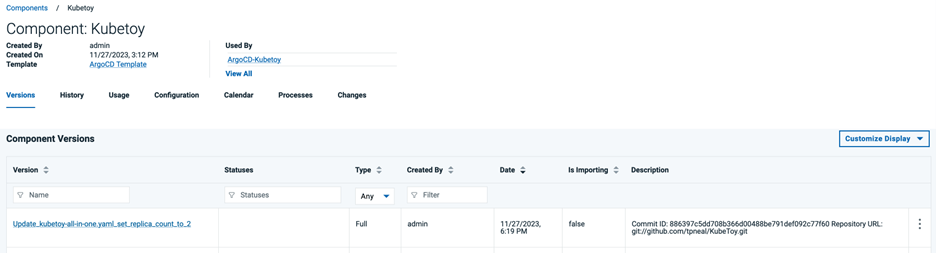
次に、Argo CD アプリケーション同期要求を呼び出す DevOps Deploy アプリケーション・プロセスが実行され、正常に完了したことを確認します。DevOps Deployアプリケーションに移動し、Historyタブを選択します。
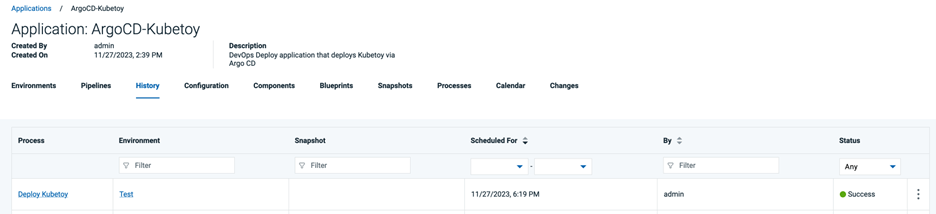
プロセス リクエスト行の末尾にある省略記号(Actions)をクリックし、[View Request]を選択します。実行ログを展開し、プロセスリクエストで実行されたすべてのステップを表示します。
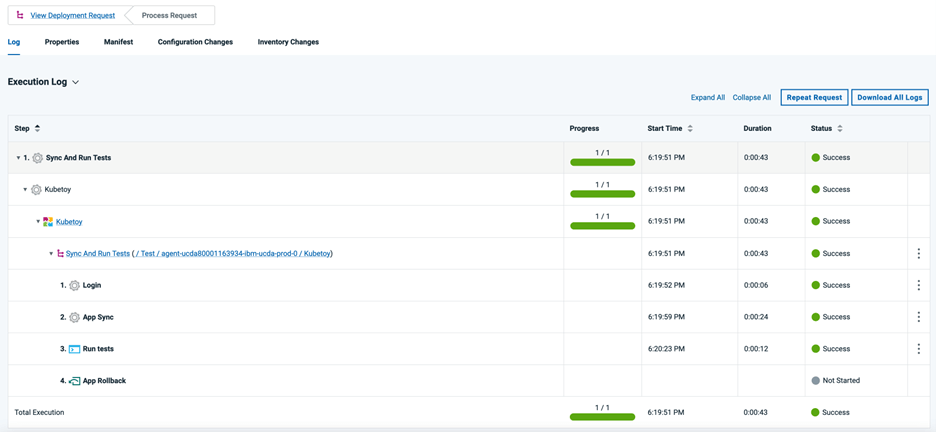
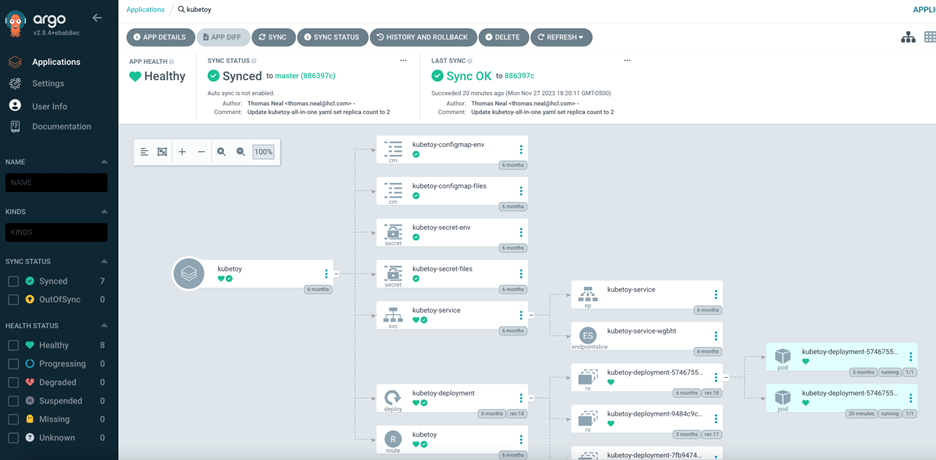
また、Argo CD UIでアプリケーションを確認し、GitHubリポジトリで行った変更に合わせてKubernetesリソースが更新されたことを確認できます。下の画像の右下の部分にKubeToyポッドが2つ表示されていることに注意してください。

eBook - VSM の旅 VSM はどこから始まったのか、VSMはどこへ行くのか、HCLSoftware はどのように支援できるのか
2023/12/27 - 読み終える時間: ~1 分
eBook - The Journey of VSM Where It Began Where It’s Going How We Can Help の翻訳版です。
eBook - VSM の旅 VSM はどこから始まったのか、VSMはどこへ行くのか、HCLSoftware はどのように支援できるのか
2023年12月21日
著者: Ryley Robinson / Project Marketing Manager
進化を続けるソフトウェア開発において、顧客に最大限の価値を提供するという目標は、多くの組織にとって依然として根強い課題である。業界ではDevOpsやDevSecOpsの台頭を目の当たりにしてきたが、成功の鍵は多くの場合、価値の流れ全体を包含する全体的なアプローチにある。そこで、戦略目標とプロジェクト実行のギャップを埋めるバリューストリームマネジメント(VSM)の概念が登場する。
バリュー・ストリーム・マネジメントは単なる流行語ではなく、複雑なプロセスを通じたビジネス価値の流れを最適化する、重要なソフトウェア・デリバリー・ツールである。コンポーネントを可視化するバリューストリームマッピングとは異なり、VSMは、アイデア出しから顧客への納品までの価値の流れを測定し、強化することに重点を置いています。障壁を取り除き、顧客の視点から仕事を捉え、すべてのステップがユーザーに価値を提供するという最終目標に確実に貢献するようにするのだ。
最新の eBook では、バリュー・ストリーム・マネジメントの世界を深く掘り下げています。テクノロジーが私たちを前進させるにつれ、プロジェクトを戦略的目標に整合させることが最も重要になります。VSMがどのように生まれ、現在どのような状況にあるのか、そして、効率的なソフトウェア・デリバリーに向けて組織が歩むための触媒となり得るのかを探ります。

パフォーマンス・テストがビジネスに不可欠な理由
2023/12/27 - 読み終える時間: ~1 分
Why Performance Testing is Critical for Your Business の翻訳版です。
パフォーマンス・テストがビジネスに不可欠な理由
2023年12月22日
著者: Cristina Suchland / Integrated Marketing Manager, Secure DevOps
ユーザーにアプリケーションを提供する際、最高の体験をしてもらいたいと考えます。ページのロード時間が速く、ナビゲーションが効率的で、最終的にユーザーがアプリを使用する際に、何かを購入したり、情報をダウンロードしたり、その他いろいろなことを達成できることを期待しています。
あなたのチームが成功するためには、アプリケーションが高速であることが必要です。また、検索エンジン最適化(SEO)で上位に表示され、コンバージョン率が高いことも必要です。コンバージョン率は非常に重要です。
なぜでしょうか?例を挙げましょう: アプリケーションのページロード時間が2秒の場合、コンバージョン率は2%になるでしょう。しかし、ページのロードに約4秒かかると、コンバージョン率は1%を下回ります。アプリケーションの成功をどのように測定するかを考えてみましょう。アプリケーションが設定した目標をユーザーが達成していることをどうやって確認するのでしょうか?
自動化を使用してアプリケーションのパフォーマンステストを実施する必要があります。しかし、パフォーマンス・テストは、機能が大量のデータを生成するため、困難な場合があります。
幸いなことに、HCL DevOps Testは、パフォーマンス・テストの自動化に関する便利なツールを提供するだけでなく、機械学習アルゴリズムを活用して結果分析を自動化し、潜在的なパターンを検出することで、これらの大量のデータの分析を支援できます。
マイクロウェビナーで、専門家であるHCLSoftware製品マネージャーのMartin Lescuyerから直接話を聞いてください。アプリケーション・テストがチームの詳細な分析にどのように役立つのか、また、顧客がポジティブなユーザー体験を得られるようにパフォーマンスを効果的に測定できるのかについて詳しく説明します。
マイクロウェビナーはこちら。

HCL DevOps Code ClearCase が Jenkins と統合し、シームレスな自動化を実現
2023/12/27 - 読み終える時間: 8 分
HCL DevOps Code ClearCase Integrates with Jenkins for Seamless Automation の翻訳版です。
HCL DevOps Code ClearCase が Jenkins と統合し、シームレスな自動化を実現
2023年12月13日
著者: Arun R / Senior Software Engineer
はじめに
Jenkins は人気のある DevOps ビルド自動化ツールです。オープンソースの統合は何年も前から利用可能ですが、この新しい統合はHCL DevOps Code ClearCase開発チームによって作成され、HCLSoftwareによって公式にサポートされています。
この統合はJenkinsのフリースタイルジョブとパイプラインジョブの両方をサポートします。デフォルトに加え、HCL DevOps Code ClearCaseの統合は、HCL DevOps Code ClearCaseの完了トリガーから呼び出されるWebhooksや、ストリーム上の変更をポーリングするためにHCL DevOps Code ClearCaseプラグインでJenkinsジョブを構成することによって、ビルドを開始する機能を追加します。
| SL No: | Topic |
| 1 | 環境 |
| 2 | HCL DevOps Code ClearCaseのインストール |
| 3 | Linux上でのJenkinsのインストールと設定 |
| 4 | LinuxでのJenkinsのアンロック |
| 5 | Jenkinsのカスタマイズ |
| 6 | JenkinsサーバーのSSL/TLS設定 |
1. 環境
-
HCL DevOps Code ClearCase 3.0.1 リリース。
-
HCL DevOps Code ClearCaseは、LinuxのJenkins LTS 2.332.xをサポートしています。
-
RHEL、SLES、Ubuntu、Solaris。
-
詳細については、システム要件のページを参照してください。
-
Jenkinsをインストールする前に、Java 8専用の64ビットJava実行環境(JRE)がインストールされている必要があります。JREをまだお持ちでない場合は、Adoptiumからhttps://adoptium.net/temurin/releases/?version=8。
-
Javaをインストールした後
- Javaのパスを設定します。

- Javaのパスをシステム環境変数として設定します。
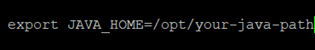
ステップ
2. HCL DevOps Code ClearCase のインストール
LinuxホストにJenkinsをインストールする前に、まずHCL DevOps Code ClearCaseをインストールする必要があります。HCL HCL DevOps Code ClearCaseリモートクライアントまたはHCL HCL DevOps Code ClearCaseをインストールし、システムパスに/opt/hcl/ccm/HCL DevOps Code ClearCase/binが含まれていることを確認する必要があります。以下のスニペット例では、完全な機能を含む「HCL DevOps Code ClearCaseフル機能インストール」を選択し、Jenkinsビルドに自動ビューを使用する場合は、インストール中に「自動ビュー」オプションを選択する必要があります。
注:VV 3.0.1のインストールには、同じホスト上にJava 8が必要です。
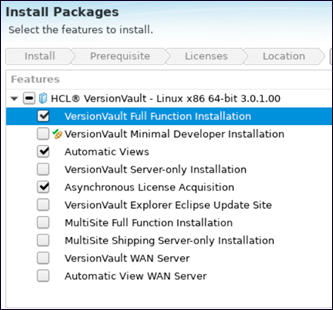
3. Linux での Jenkins のインストールと設定
HCL HCL DevOps Code ClearCase と Jenkins の統合のために Linux に Jenkins をインストールするには、以下の手順を使用します。
-
https://get.jenkins.io/war-stable/ から jenkins.war ファイルをダウンロードし、ホームディレクトリに置きます。
- mkdir JENKINS
- chmod 700 JENKINS
- cd JENKINS
- cp ~user/jenkins-2.332.x.war .
- lsでjenkins-2.332.x.warファイルを表示します。
-
以下のコマンドを実行します。

-
Jenkinsのインストール中に、以下の例に示すように、Jenkinsのログと初期パスワードが作成される:

デフォルトでは、initalAdminPasswordはユーザーのホーム・ディレクトリにあります。例
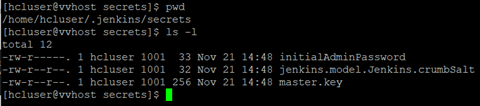
-
ヒント: パスワードは、Jenkinsのロックを解除するために必要なので、メモしておくこと。
4. Linux での Jenkins のロック解除
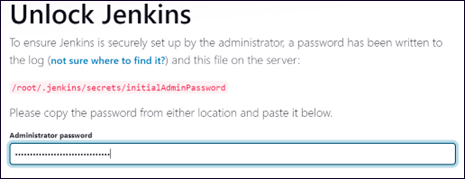
インストール・プロセスの完了後、Linux 上で HCL HCL DevOps Code ClearCase-Jenkins 統合用に Jenkins をカスタマイズして使い始める前に、Jenkins のロックを解除する必要があります。
-
このインストールでは、Jenkins はポート 8080 でホストされます。ウェブ・ブラウザを開き、http://hostname:8080 にアクセスします。
-
ヒント Jenkins のポートを変更する方法については、https://phoenixnap.com/kb/jenkins-change-port を参照してください。
-
Jenkinsのロック解除ダイアログ・ボックスの管理者パスワード・フィールドに、Jenkinsのインストール・セクションのステップ3で取得したパスワードを入力するか、initialAdminPasswordファイルからパスワードを取得して、[続行]をクリックします。
5. Jenkins のカスタマイズ
Jenkins のインストール・プロセスを完了し、Jenkins のロックを解除した後、Linux 上で HCL HCL DevOps Code ClearCase-Jenkins 統合に使用する前に、Jenkins をカスタマイズする必要があります。
以下の手順を使用して、Jenkins を使用する前にカスタマイズしてください:
-
Jenkinsのカスタマイズ・ダイアログ・ボックスで、Jenkinsに最も頻繁に使用されるプラグインを自動的にインストールさせるには、Install suggested pluginsをクリックします。
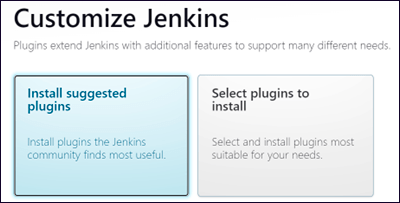
-
プラグインがインストールされたら、[Create First Admin User]ダイアログボックスに必要な情報を入力し、[Save and Continue]をクリックします。
-
インスタンス構成]ダイアログボックスで、Jenkinsに使用させたいポート番号を確認し、[保存して終了]をクリックします。これで初期カスタマイズは完了です。
-
Start using Jenkinsをクリックして、Jenkinsダッシュボードに移動します。
-
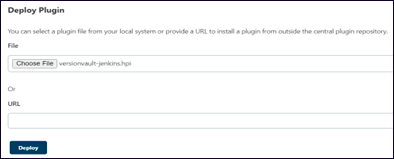
HCL DevOps Code ClearCase-jenkins.hpiとcmapi-jenkins.hpiを以下からコピーします。
-
HCL DevOps Code ClearCase-home-dir/java/lib/HCL DevOps Code ClearCase-jenkins.hpiとHCL DevOps Code ClearCase-home-dir/java/lib/cmapi-jenkins.hpi をコピーします。
-
コピーしたファイルHCL DevOps Code ClearCase-jenkins.hpiとcmapi-jenkins.hpiを、次のステップで説明するように、Jenkins管理ウェブページを使用してJenkinsサーバーにインストールします。
-
Manage Jenkins > Manage Plugins > Advanced タブを選択し、以下のプラグインを追加します。
- cmapi-jenkins.hpi
- HCL DevOps Code ClearCase-jenkins.hpi
-
a) Jenkinsホームページの左側に、"Manage Jenkins "オプションがありますので、それを選択してください。
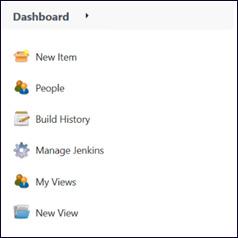
-
b) システム設定の下にスクロールダウンすると、"プラグインの管理 "があります。

-
c) "Plugin Manager "の下にある "Advanced "オプションを選択します。
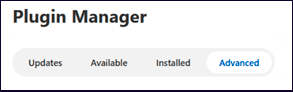
-
d) スクロールダウンして、"プラグインのデプロイ "オプションに行く。次に、"Choose File "オプションを選択して、2つのプラグイン・ファイル(HCL DevOps Code ClearCase-jenkins.hpiとcmapi-jenkins.hpi)を選択し、"Deploy "をクリックします。
-
e) 2つのプラグインファイルがデプロイされると、以下の結果が表示されます。

6. JenkinsサーバーのSSL/TLS設定
JenkinsサーバーにSSL/TLSを使用したい場合は、Jenkinsのドキュメント(https://www.jenkins.io/doc/book/installing/initial-settings/ )を参照して、前述のコマンドラインフラグの代わりに他のコマンドラインフラグを使用してください。