HCL VersionVault Express を始めてみる: ダウンロード、インポート、設定、起動
2021/11/2 - 読み終える時間: 3 分
Getting Started: Download, Import, Configure and Launch VersionVault Express. の翻訳版です。
HCL VersionVault Express を始めてみる: ダウンロード、インポート、設定、起動
2021年10月18日
著者: Georgiy Petrov / Lead Software engineer II

VersionVault Express Canは、3つの簡単なステップで使い始めることができます。
- VersionVault Expressアプライアンスを含むイメージをダウンロードします。
- VersionVault Expressアプライアンスをハイパーバイザーにインポートします。
- VersionVault Expressアプライアンスの構成をします。
VersionVault Expressのovaファイルをダウンロードしたら、それをハイパーバイザーにインポートします。 メモリとCPUの設定を行い、必ず新しいハードディスクを追加してください。アプライアンスには、OSとすべてのソフトウェアがプレインストールされたハードディスクが1つ付属していますが、データ保存用にもう1つのディスクを取り付ける必要があります。ストレージ用のハードディスクが接続されていないと、アプライアンスは起動しません。ポートフォワーディングを使用する場合は、メイン・ユーザー・インターフェースとREST API用の443、セットアップ・ユーザー・インターフェースとREST API用の8443、外部のVersionVaultクライアントを使用する場合は8080、そしてアプライアンスにSSH接続する場合は22の4つのポートを開く必要があります。
これで、アプライアンスを起動する準備が整いました。
アプライアンスの初回起動時には、ストレージ・ディスクの接続を忘れていないかどうかがチェックされ、その後、ネットワーク・インターフェースの設定を求められます。ハイパーバイザでネットワークを構成した場合は、このステップをスキップしてデフォルトのネットワーク構成を使用できます。ヘッドレスモードでは、アプライアンスはユーザがネットワークを構成するのを5分間待ってから、デフォルトのネットワーク構成を実行することに注意してください。
次のステップでは、VersionVault Expressを設定します。ブラウザを開き、https://
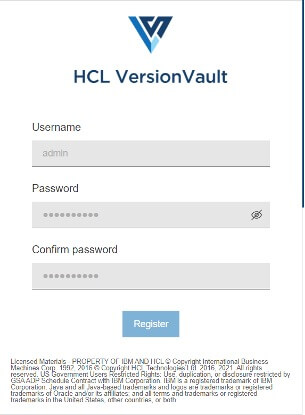
swaggerのドキュメントは
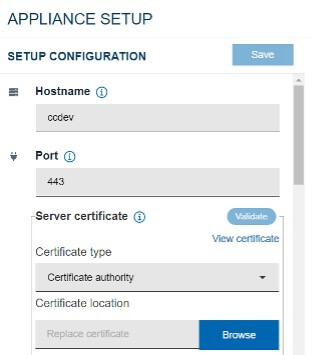
このアプライアンスのインスタンスにホスト名を付ける必要があります。デフォルトのポート(443)を受け入れることも、別のポートを選択することもできます。その場合は、設定しているポートフォワーディングやファイアウォールを更新してください。
メイン・ユーザー・インターフェースとREST API、セットアップ・ユーザー・インターフェースとREST API、およびVersionVaultクライアントが接続するサーバーという、アプライアンス上の3つのHTTPSサーバーすべてで使用されるSSL証明書をアップロードすることができます。証明書が適用される前に、サーバーを再起動する必要がありますのでご注意ください。
VersionVault Expressアプライアンスには、トライアル・ライセンスがプレインストールされています。独自のライセンス・サーバーとサーバーIDをお持ちの場合は、今すぐ入力してください。
VersionVault Expressは、独自にユーザーを管理するか、企業のLDAPサーバーを使用するかを設定することができます。独自にユーザーを管理する場合は、SMTPサーバーを使用してプロジェクトへの招待状やパスワードリセットのメールを送信するようにアプライアンスを設定することができます。
ヒント:「Validate」を選択して、設定を保存する前に構成をテストします。
管理ユーザーがアプライアンスに SSH で接続できるようにする場合は、オプションで SSH キーを設定できます。
また、NTP サーバーとタイムゾーンを設定することもできます。
設定を保存します。
次のステップでは、企業のLDAPサーバーに接続するか、単に新しいユーザーを作成するかして、いくつかのユーザーを設定します。このトピックについては、別のブログ記事で紹介しています。
準備ができたら、「User Configuration」セクションの「Save」ボタンをクリックします。右側にあるボタンです。すべての準備が整っていれば、成功のメッセージが表示されます。

Launch VersionVaultをクリックして、VersionVault Expressを起動します。
再度、成功メッセージを確認してください。
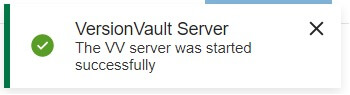
これで、VersionVault Expressを使用することができます。
詳細については、製品のドキュメントを参照してください。
HCL VersionVault Express のコンセプトの紹介
2021/10/19 - 読み終える時間: 3 分
Introduction to VersionVault Express concepts の翻訳版です。
HCL VersionVault Express のコンセプトの紹介
2021年10月18日
著者: Michael Hudson / Director for the HCL Software DevOps Products

この記事では、VersionVault ExpressがVersionVault Unified Change Management(UCM)の機能を使用して、バージョン管理された資産を管理する方法について説明します。
VersionVault ExpressはUCMを使用して、仮想アプライアンスにパッケージされたバージョン管理システムを実装します。各VersionVault Expressインスタンスは、VersionVault Expressプロジェクトのセットをホストし、各プロジェクトは独自のソースリポジトリであるVOB(Versioned Object Base)を持ちます。 VOBは、プロジェクトに関するメタデータと、プロジェクト内で管理されるファイル/ディレクトリ/シンボリックリンクのバージョン管理されたコンテンツを格納します。プロジェクトのメンバーシップは、プロジェクトのオーナーが管理するVOBのアクセスコントロールリストに記録されます。 (VersionVault Expressでサポートされているロールの紹介については、この記事の最後にある参照リンクを参照してください)。
VOB、プロジェクト、そしてコンポーネント
各VersionVault Expressプロジェクトは、ストリームとそのコンテンツを整理するために使用される1つのUCMプロジェクトと、バージョン管理されたファイルとディレクトリの要素を保存するために使用される1つのUCMコンポーネントを含む1つのVOB上に構築されます。 これらは、VersionVault Expressのプロジェクト作成時に自動的に作成されます。 ほとんどの場合、これらのUCMオブジェクトを明示的に管理する必要はありません。
UCM プロジェクトには複数の UCM ストリームが含まれており、プロジェクトのメンバーがバージョン管理されたオブジェクトを管理します。 開発者は、自分の作業を他の開発者の作業とマージする準備ができるまで、自分のストリームで作業を分離することができます。
各プロジェクトは独立しており、自己完結しています。 複数のプロジェクト間の調整が必要な場合は、VersionVault Expressの範囲外で自分自身で行います。
ストリーム
UCM ストリームは、バージョン管理されたデータのブランチを管理します。 プロジェクトのトップレベルのストリームは、統合ストリームです。 このストリームは、主に Builder ロールのアカウントによって管理されます。 開発者は通常、このストリームに変更を直接チェックインすることはありません。開発者は通常、開発者ストリームを変更と検証を行う場所として使用します。
各開発者は、プロジェクトに参加すると開発者ストリームを取得します。 開発者ストリームは、統合ストリームの子です。 開発者は、変更を統合ストリームに配信して、他の開発者がその変更を利用できるようにしたり、自分のストリームをリベースして、他の開発者が配信した最新の変更を自分のストリームに反映させたりすることができます。
ベースライン
コードベースは、開発者が各ストリームにコードをチェックインすることで、時間とともに進化します。 通常、プロジェクトのビルダー・ユーザーは、配信完了などの特定の操作の後に、統合ストリームにベースラインを作成します。 ベースラインは、ストリームの状態のスナップショットを表し、VOB内の制御された各要素の1つのバージョンを参照しています。 時間をかけて、ストリームの歴史を記録する一連のベースラインを作成します。
各ストリームには、「推奨ベースライン」と「基礎ベースライン」という2つの異なるベースラインがあります。ビルダーは、ストリームの中で作成されたベースラインを推奨ベースラインとして指定することができます。 推奨ベースラインは、子ストリームのリベース処理のデフォルトの選択肢として提供され、新しい開発者用ストリームや機能ストリームなどの新しい子ストリームの基礎ベースラインとしても提供されます。 統合ストリームの基礎ベースラインは、あまり興味深いものではありません(作成直後のプロジェクトの初期状態を表しているだけです)。 しかし、開発者ストリームには、時間の経過とともに変化する可能性のある基礎ベースラインがあります。 ストリームが作成されると、最初は基礎ベースラインがその親ストリームの推奨ベースラインに設定されます。開発者は、作業開始時の親ストリームの状態に基づいて、自分のストリームで単独で作業を行うことができます。 しかし最終的には、リベース操作を使って、親ストリームの最新の良いコードと統合する必要があります。 ビルダーが新しい推奨ベースラインを作成して指定した後、開発者は簡単に自分の開発者ストリームをリベースして、その変更を取り入れることができます。 (開発者は、テストされていないコードを扱うリスクを許容できるのであれば、後から推奨されないベースラインを選択することもできます)。) リベースが完了すると、リベースされたストリームの基礎ベースラインが、リベース時に使用されたベースラインに設定されます。
階層的なストリーム
VersionVault Expressのストリームは、階層的に配置されています。プロジェクト統合ストリームが、すべての "標準 "開発者ストリームの親であることはすでに説明しました。 しかし、メインの統合ストリームを妨げることなく、さらに分離して開発者が共同作業を行う方法が必要な場合は、"機能ストリーム"(またはそのようなストリームの階層ツリー)を作成することができます。 1つのレベルの機能ストリームでは、次のような階層構造になっています。
- プロジェクト統合ストリーム
- 機能ストリーム
- 開発者#1の機能ストリーム
- 開発者#2の機能ストリーム
- 機能を持たない開発者#3のストリーム
- 機能ストリーム
ビルダーは機能ストリームでベースラインを管理し、機能に携わる開発者は機能ストリームからリベースして機能ストリームに配信する。
ビルダーは機能ストリームでベースラインを管理し、その機能に携わる開発者は機能ストリームからリベースして配信します。 ある時点で、その機能が良い状態になったら、ビルダーやリードデベロッパーは、機能ストリームからプロジェクト統合ストリームに配信します。 その機能を担当していない開発者は、機能ストリームと並行して自分の開発者ストリームで作業することができます。
VersionVault Expressの厳密な親子配信/リベース・モデルよりも複雑なマージ・パターンが必要な場合は、VersionVault Explorerを使用して個々のアクティビティやストリーム間のマージを管理することができますし、さらに柔軟性を高めるためにVersionVaultフル版にアップグレードすることもできます。
デリバリーとリベース
配信とリベースは、ストリームの階層に沿って行われます。リベースは、親ストリームの新しいベースラインから変更をピックアップし、配信は、自分のストリームの変更を親ストリームにマージします。
アクティビティ
ストリーム内では、ファイルやディレクトリのバージョンをチェックアウトしたり、チェックインしたりすることができます。 これらのストリームは通常、継続的な開発に使用されるため、ストリーム内の各変更は、関連する一連の変更を追跡するためにUCMアクティビティにリンクする必要があります。VersionVault Expressは、完全なVersionVaultと同様に、UCMアクティビティを使用して、関連するバージョンの変更セットをリンクします。 開発者は、各論理的な変更を管理するアクティビティを作成し、そのアクティビティを現在のアクティビティとして設定している間に、チェックアウト/チェックイン/ファイルの追加を行います。 コードを親ストリームにマージする準備ができたら、アクティビティの一部だけを配信することも、マージされていない変更を含むすべてのアクティビティを配信することもできます。
まとめ
VersionVault Expressでは、UCMプロジェクト、コンポーネント、ストリーム、ベースライン、アクティビティを使用して、要素への変更を管理することを学びました。 ストリームは階層的に配置されており、開発者は、他の人が変更を取得できるように変更を配信したり、同僚から変更を取得するためにリベースする際にこれに従います。 ベースラインは、プロジェクトの開発サイクルにおけるストリームのバージョンの変遷を示すものです。 アクティビティは、複数の要素のバージョンを収集して、関連する変更セットを一貫して作成します。
さらに詳しく
VersionVault Expressには、VersionVaultのパワーの上に構築された、より多くの機能があります。 ここでは、より詳しく知るための追加リソースをご紹介します。
- 製品のヘルプをご覧ください。

継続的テストにまつわる神話トップ 10
2021/10/5 - 読み終える時間: 2 分
The Top 10 Continuous Testing Myths の翻訳版です。
継続的テストにまつわる神話トップ 10
2021年9月30日
著者: Cassandra Stanek / Product Marketing Manager | HCL Accelerate & Launch

企業のエコシステムは、日に日に複雑化しています。ソフトウェアをより早く提供する方法を模索する中で、継続的テストは重要な要素です。ここでは、私たちがよく目にする継続的テストに関する神話のトップ10をご紹介します。
1. 継続的テスト=テストスクリプトの実行
アプリケーションが合意された要件を満たしているかどうかを検証することは重要ですが、継続的テストには、計画、分析、共同作業、思考、探索、自動化、検証、報告、レビュー、議論などが含まれます。
2. アジャイルチームだけが継続的テストを使用する
継続的テストの手法は、どんなプロジェクトにも活用できます。利用可能な依存システムがない場合、チームは仮想サービスを作成して、不足しているアプリケーションを模倣することで、できるだけ早くテストを開始することができます。
3. 継続的テストは単なるバズワード
継続的テストは、チームの生産性を向上させ、その価値を証明してきました。継続的テストは、より高い品質のアプリケーションを顧客に提供するための自動化されたアプローチを提供します。
4. 継続的テストを使えるのはテスト担当者だけ
アナリスト、アーキテクト、デザイナー、プログラマー、テスター、オペレーションエンジニアなど、すべての人がソリューションの構築に関わっています。
5. 継続的テストは大規模・複雑なシステムには使えない
システム間の統合ポイントを検証するAPIレベルのテストは、品質を劇的に向上させます。また、サービス仮想化では、従来のアプリケーションシナリオを検証しながら、アプリケーションの依存関係の欠落をシミュレートできます。これは、大規模・複雑なシステムで問題を迅速に発見するために、アプリケーション・インターフェースをテストする際にしばしば重要になります。
6. 継続的なテストは、安全なDEVOPの一部ではない
Secure DevOps」という言葉に「テスト」が含まれていないからといって、ソリューションに含まれていないわけではありません。実際には、欠陥品をエンドユーザーに配布するリスクを低減し、ビジネスの損失を確実に防ぐために必要な負担です。
7. 規制されている業界では、継続的なテストは機能しない
厳しいコンプライアンス要件が課せられている規制業界においても、継続的テストは、詳細なログやテストレポートを提供することで負担を軽減し、全体的な配信プロセスの一部としてコンプライアンスを示すことができます。
8. テストを自動化することで、テスト担当者の数を減らすことができる
探索的なテストは、多くのテスト自動化ツールでは対応できないため、テスト対象のアプリケーションを精査するための目と手(場合によっては耳)が必要です。また、テストアナリストは、どのようなテストを作成し、どのようなデータセットで実行し、その結果を分析するかを決定する。
9. 継続的テストはクラウドアプリケーションには向かない
テスト対象のアプリケーションがどこでホストされているか(ローカル、プライベートデータセンター、パブリックデータセンター、またはその組み合わせ)に関わらず、継続的テストのプラクティスを採用することができます。
10. テストチームは品質に責任を持つ
アジャイルの「チーム全体」のプラクティスを取り入れることで、品質が劇的に向上します。誰もが間違いを犯すので、どんな仕事でも新鮮な目で見ることは非常に貴重です。
HCL OneTest は、DevOpsアプローチをサポートするソフトウェアテストツールを提供している。HCL OneTestは、プロジェクトのライフサイクルを通じてUI、パフォーマンス、APIのテストをサポートし、高度に統合された複雑なアプリケーションのテストという課題に対応します。無料トライアル では、コストを削減しながらスピードと品質を向上させる方法をご覧いただけます。
バリューストリームマネジメントの市場と認証
2021/9/30 - 読み終える時間: 2 分
The Value Stream Management Market & Certifications の翻訳版です。
バリューストリームマネジメントの市場と認証
2021年9月29日
著者: Cassandra Stanek / Product Marketing Manager
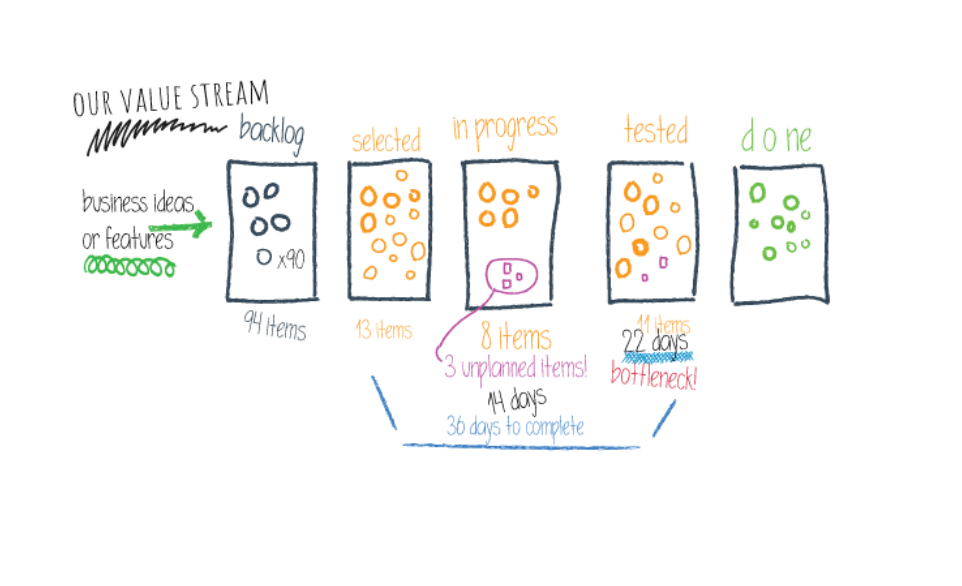
現在の状況
今年、発表された「バリュー・ストリーム・マネジメントの現状レポート2021」では、DevOpsを実現するための重要な可視化要素であるVSMの導入において、企業組織がどのような状況にあるかを示す基準が示されました。このレポートによると、市場はVSM導入の初期段階にありますが、チームは競争力のある成長とポジショニングのために、VSMの導入と活用に積極的に取り組んでいます。
このレポートは、企業のリーダーや製品・サービスの開発に携わる方々にとって、一読の価値があるものです。成功しているチームがどのフロー指標に注目しているか、企業がデジタルバリューストリームに基づいてどのようにチームを編成し、組織化しているか、バリューストリームマッピングで発見されたこと、DevOpsの導入をどのように進めるかなど、有益なデータが満載です。HCLソフトウェアのDevOps製品責任者である Brian Muskoff は、このレポートに貢献しており、HCLソフトウェアはVSMCの5つの設立メンバーの1つです。
バリューストリームマネジメントの認証
このレポートから得られた素晴らしい洞察に基づいて、VSMCはDevOps Instituteを通じてValue Stream Management Foundation認証も開発しました。この包括的なコースは、バリュー・ストリーム・マネジメントの原則、実践、ツールを紹介するものです。このコースは、デジタルバリューストリームにおける価値の流れと実現を最適化し、この新興分野のスキルを開発することを目的としています。デジタル・バリュー・ストリームには、ソフトウェア・アプリケーションやサービスに加えて、クラウド・インフラストラクチャやDevOpsツールチェーンなど、それらを支えるプラットフォームも含まれます。

Gartner社によると、2023年までに70%の組織がバリューストリームマネジメントを使用してDevOpsパイプラインのフローを改善し、顧客価値の迅速な提供につなげるとしています。このようなVSMの積極的な市場導入を念頭に、リーダーや開発者は、VSMの歴史と進化、価値の流れの特定方法、価値の流れのマッピング、DevOpsツールチェーンの接続、価値の流れの測定基準などを理解することで、成功に向けた体制を整えることができます。バリュー・ストリーム・マネジメントの認定を受けることは、実践を拡大するための基盤となり、VSMCのメンバーであれば誰でも無料で受けることができます。
重要な理由
効率的で価値主導のソフトウェアデリバリーは、企業のデジタルトランスフォーメーションを成功させるための主要な要素です。そのため、デジタルトランスフォーメーションで最も困難なのは、その測定です。ここで重要になるのが、バリューストリームマネジメントです。これは、成功したDevOpsプラクティスとデジタルトランスフォーメーションの取り組みを定義し、測定することを目的とした、ソフトウェアデリバリーの新しいプラクティスです。
バリュー・ストリーム・マネジメントが導入される前のソフトウェア・デリバリーは、GPSのない国を横断する長いドライブ旅行のようなものでした。ドライバーは目的地と方向を知っていますが、おそらく最短ルートではないでしょう。遅れることもあれば、何度か道に迷うこともあり、目的地にたどり着くまでに多くの時間と費用を費やすことになります。企業にとって、このような効率性と可視性の欠如は、数百万ドルにもなり、デジタルトランスフォーメーションの旅の車輪が回転しているようなものです。
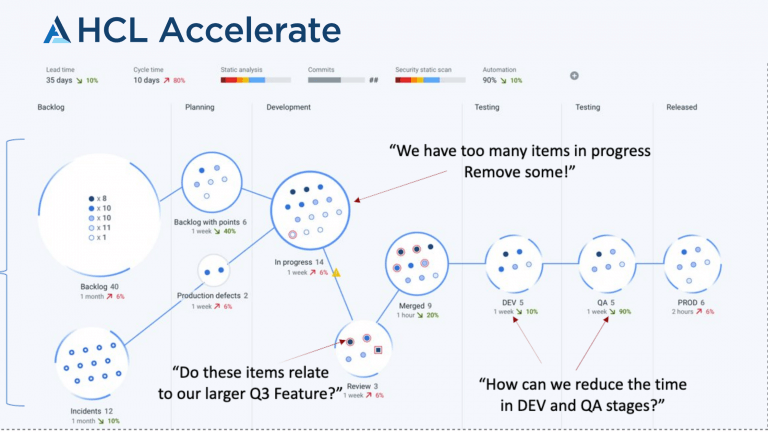
HCL Accelerate は、業界をリードするデータ駆動型のバリューストリーム管理プラットフォームであり、自動化されたガバナンスと指標の可視化により、より迅速なソフトウェアデリバリーを導き、より効率的なデジタルトランスフォーメーションを可能にします。
HCL Compass Rest API の活用
2021/9/23 - 読み終える時間: 18 分
HCL Compass Rest APIs In Action の翻訳版です。
HCL Compass Rest API の活用
2021年9月20日
著者: Pradeesh S P / Technical Specialist, HCL Software

はじめに
この記事では、HCL Compass 2.0.2バージョンで提供されるRESTFULサービスについて説明します。HCL Compassでは、ウェブやデスクトップ・インターフェースの他に、Perl APIやJava Native Interfaceを使用することができます。これらの2つのオプションは、複雑で柔軟性に欠けているため、Compassを中心としたアプリケーションや統合の構築が難しく、時間がかかります。
HCL Compass REST APIは、開発者がHTTPベースのREST APIを使用してHCL Compassと対話することを可能にします。REST APIは、レコードの表示や修正、クエリの作成と編集、テキスト検索など、HCL Compassの多くの機能を実行するために使用できます。REST APIの機能は、コンポーネントとしてHCL Compassのインストールに含まれています。これは、Apache Tomcatインスタンス上に展開され、CQwebサービスから独立して実行されます。一度インストールすれば、あとはサービスを起動するだけで使い始めることができます。このブログでは、REST APIを利用してHCL Compassのデータと対話するPythonスクリプトを開発します。このスクリプトを作成しながら、一般的に使用されているRESTAPIのいくつかを紹介します。
この記事の内容
この記事は、プログラミングや、特定のタスクを実現するためのコードを提供するものではありません。単に、Compassデータと対話するためにREST APIを実用的な文脈で使用する方法を紹介するものです。もちろん、Pythonスクリプトを書くには、関数を使うなど、もっと簡単で効率的な方法があります。データ操作のコードの一部はスニペットに含まれておらず、ほとんどがREST APIと対話するためのリクエストモジュールの使い方を扱っています。
このスクリプトの役割
スクリプトを実行すると、システムで利用可能なリポジトリのリストを表示します。 パラメータとしてユーザー名、パスワード、データベースを入力することで、認証するリポジトリをリストから選ぶことができます。 選択したリポジトリに関連するデータベースを一覧表示します。 ユーザーにデータベースの提供を求め、そのユーザーに割り当てられたレコードを表示するためのクエリを構築する。 クエリを実行して、結果セットを表示します。 クエリを削除します。 REST サーバーからログアウトします。
このスクリプトで使用されるAPI
Repos API - Schema Repositories のリストを取得します。 Authenticate API - CCM REST サーバーへの認証を行います。 Databases API - スキーマリポジトリに関連付けられたデータベースを一覧表示する。 Folders API - クエリを作成する親フォルダーをリストアップする。 QueryDefs API - クエリ定義を作成する。 ResultSets API - クエリ定義を実行して、結果セットを構築します。 ResultSet API - 以前に実行された Query Definition の単一ページを取得します。 QueryDef API - クエリ定義を削除するためのものです。 Authenticate API - CCM Rest Server からログオフする。
では、これらのAPIを詳細に確認しながら、スクリプトを作成していきましょう。
1. スキーマリポジトリのリストの取得
最初のタスクは、ユーザーがスキーマリポジトリを選択できるように、スキーマリポジトリのリストを取得することです。これには、REPOS API、特にエンドポイントである/ccmweb/rest/repos を使用します。この目的のためには、GET HTTPリクエストを使用する必要があります。このデモでは、Python Requests モジュールを使用してREST APIスクリプトを作成します。そのためには、スクリプトにモジュールをインポートする必要があります。そして、request.get()関数を使用して、このAPIリクエストを送信します。request.get関数は、リポジトリのエンドポイントをURLとして受け取り、ヘッダを引数として渡します。この特定のAPIでは、期待されるヘッダーは次のとおりです。
'Content-Type': "application/json"
ヘッダー情報は headers という変数に保存され、URL は repo_endpoint という変数に保存されます。これは、Rest APIのリクエストを行うために、このスクリプト全体でrequestモジュールにパラメータを渡すための、標準的なテンプレートになります。
cont_type = “application/json”
headers={‘Content-Type’: cont_type}
repo_endpoint = “https://servername:8190/ccmweb/rest/repos”
response = requests.get(
repo_endpoint,
headers=headers
)
上記のコードは、システムで利用可能なリポジトリのリストを取得します。
2. CCM RESTサーバーへの認証
システムでリポジトリが利用できるようになり、ユーザーがログインするリポジトリを選択できるようになったので、認証を行う必要があります。REST サーバーへの認証には、/ccmweb/rest/authenticate をエンドポイントとする Authenticate API を使用します。使用するHTTPリクエストはPOSTです。まず、ユーザーにユーザー名、パスワード、リポジトリ名、ログインしたいデータベースを入力してもらいます。以前のREPOS APIとは異なり、Authenticate APIでは、上記の情報をJSON形式でボディに送信する必要があります。ヘッダーとURLの他に、今回はボディデータもrequests.postメソッドで提供しなければなりません。また、リクエストが何らかの例外やエラーメッセージを発生させたかどうかを知る必要があり、そのために raise_for_status() メソッドを使用します。すべてがうまくいけば、このリクエストは認証トークンをJSON形式で出力します。これは、Compassのデータを取得または変更するための今後のAPIリクエストに使用する必要があります。このデータを操作してトークンを取得するためには、このJSON出力を処理してPythonの辞書データ構造に変換する必要があります。そのために、.json()メソッドを使用します。Json.dumps関数は、Pythonで処理できるようにjsonデータを文字列に変換します。前回のAPIコールと同じヘッダーを今回も渡していることに注目してください。
期待されるヘッダーは、「Content-Type」。"application/json"
eponame = input(“\nEnter Repository Name : “)
auth_url = “https://servername:8190/ccmweb/rest/authenticate”
username = input(“\nEnter your username : “)
password = input(“\nEnter your password : “)
db1name = input(“\nEnter db name : “)
body_data={“username”:username,
“password”:password,
“repo”:reponame,
“db”:db1name
}
auth_response = requests.post(auth_url,headers=headers,data=json.dumps(body_data))
auth_response.raise_for_status()
auth_data=auth_response.json()
3. スキーマ・リポジトリに関連するデータベースの一覧表示
スキーマ・リポジトリに関連するデータベースの一覧を表示するには、エンドポイントがccmweb/rest/repos/repository name/databasesのDatabases APIを使用します。HTTPリクエストは GET です。今回は、先ほどのAPIコールのヘッダーとは別に、Authentication Token(先ほどのAPIコールの後に出力として受け取ったもの)を以下のフォーマットで送る必要があります。
期待されるヘッダーは ‘Content-Type’: “application/json”,
Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJhZG1pbiIsInJlcG8iOiIxMC4wLjAiLCJleHAiOjE1NzM2NjE5NDUsImlhdCI6MTU3MzU3NTU0NSwiZGIiOiJTQU1QTCJ9.Lgdk9gPm6mFFGEnr6mRt7Vrq-nTnlP86ARKc16bP4syeTIvKQ55JX5r6aFXVC20xC2NwsjqbvAhd2f1r2PiIUA
requests.get関数では、URLとヘッダを渡しています。また、resay_for_status()を行い、.json関数でレスポンスを読み込んでいます。このAPIでは、必須のボディデータはありません。データベースを辞書として取得し、それを処理してユーザーがCompassデータへのアクセスを選択できるように表示する必要があります。
auth = “Bearer”+” “+auth_data[‘token’]
headers1={‘Content-Type’: cont_type,
‘Authorization’: auth
}
db_url = f”https://servername:8190/ccmweb/rest/repos/{RespositoryName}/databases”
dbname_response = requests.get(db_url,
headers=headers1
)
dbname_response.raise_for_status()
dbnames = dbname_response.json()
4. 親フォルダのDBIDを取得してクエリを作成する
ワークスペース内のあるフォルダにクエリを作成する必要があります。そのためには、ルートワークスペースにどのようなフォルダがあるかを調べる必要があります。この例では、クエリは一時的なものなので、「Public Queries」フォルダに保存します。そのため、ワークスペース内の「Public Queries」フォルダの DBID を調べる必要があります。この目的のために Folders API を使用し、エンドポイントを /ccmweb/rest/repos/ リポジトリ名 /databases/ データベース名 /workspace/folders とします。 使用する HTTP リクエストは GET です。
期待されるヘッダーは、'Content-Type': "application/json",
Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJhZG1pbiIsInJlcG8iOiIxMC4wLjAiLCJleHAiOjE1NzM2NjE5NDUsImlhdCI6MTU3MzU3NTU0NSwiZGIiOiJTQU1QTCJ9.Lgdk9gPm6mFFGEnr6mRt7Vrq-nTnlP86ARKc16bP4syeTIvKQ55JX5r6aFXVC20xC2NwsjqbvAhd2f1r2PiIUA
requests.get関数にパラメータを渡し、いつものようにraise_for_status関数を使い、.json関数を使って出力されたレスポンスをキャッチする必要があります。このJSONデータをjson.dumps関数に渡します。この出力から、次のAPIで必要となるdbIdデータに興味があります。
parent_url = f”https://servername:8190/ccmweb/rest/repos/{RepositoryName}/databases/{DatabaseName}/workspace/folders”
parent_dbid_response = requests.get(parent_url ,headers=headers1)
parent_dbid_response.raise_for_status()
parent_dbid_higher = parent_dbid_response.json()
parent_dbid = parent_dbid_higher[1][‘dbId’]
5. クエリ定義の作成
ユーザーからアクセスが必要なデータベースと親DBIDの入力を得たら、スクリプトの目的は、そのデータベース内のどの欠陥が所有されているかをユーザーに表示することです。このため、最初のステップでは、ログインユーザが所有するすべての欠陥を表示するためのクエリ定義を作成する必要があります。この目的のために、QueryDefs API を使用します。エンドポイントは /ccmweb/rest/repos/リポジトリ名/データベース名/workspace/queryDefs で、使用する HTTP リクエストは POST です。このAPIでは、従来のAPIと同様のヘッダが必要ですが、構築されるクエリの構造を形成するボディデータが必須となります。
期待されるヘッダは ‘Content-Type’: “application/json”,
Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJhZG1pbiIsInJlcG8iOiIxMC4wLjAiLCJleHAiOjE1NzM2NjE5NDUsImlhdCI6MTU3MzU3NTU0NSwiZGIiOiJTQU1QTCJ9.Lgdk9gPm6mFFGEnr6mRt7Vrq-nTnlP86ARKc16bP4syeTIvKQ55JX5r6aFXVC20xC2NwsjqbvAhd2f1r2PiIUA
本体のデータは以下のようになり、変数query_dataに格納されます。
query_data={ “name”: “MyDefects”,
“dbIdParent”: parent_dbid,
“primaryEntityDefName”: “Defect”,
“queryFieldDefs”: [
{
“fieldPathName”: “Headline”,
“isShown”: “true”
}
],
“filterNode”: {
“boolOp”: “BOOL_OP_AND”,
“fieldFilters”: [
{
“fieldPath”: “Owner”,
“compOp”: “COMP_OP_EQ”,
“values”: [username],
“stringExpression”: “= username”
}
]
}
}
ボディデータをもう少し詳しく見てみましょう。いつものように、ボディデータはJSON形式です。
name – Name of the query.
dbIdParent – The dbid of the parent directory where the query is to be created.
primaryEntityDefName – Record type name.
queryFieldDefs – fieldPathName is the field name.
isShown : true – To display the specific field in the result set.
filterNode – boolOp – AND – Operator for adding multiple filters to the query.
fieldFilters – These are the fields to provide as filters.
fieldPath : Owner – Field name of the filter
compOp – COMP_OP_EQ – Denotes Equal to
values : [username] – ユーザー名は、ユーザーの実際のユーザー名に置き換えられます。この条件では、フィールドOwnerが提供されたユーザー名と等しくなっています。したがって、クエリはオーナーが提供されたユーザー名であるすべてのDefectをリストアップする必要があります。
API用のパラメータの準備ができたので、これらを requests.post 関数に渡し、いつものように raise_for_status 関数を使用して、.json 関数を使用して出力レスポンスをキャッチします。json.dumps関数でJSONデータを渡します。この出力から、次のAPIで必要となるdbIdのデータに興味があります。
query_db = input(“\nEnter Database name to build query : “)
query_data={ “name”: “MyDefects”,
“dbIdParent”: parent_dbid,
“primaryEntityDefName”: “Defect”,
“queryFieldDefs”: [
{
“fieldPathName”: “Headline”,
“isShown”: “true”
}
],
“filterNode”: {
“boolOp”: “BOOL_OP_AND”,
“fieldFilters”: [
{
“fieldPath”: “Owner”,
“compOp”: “COMP_OP_EQ”,
“values”: [username],
“stringExpression”: “= username”
}
]
}
}
query_url = f”https://servername:8190/ccmweb/rest/repos/{RepositoryName}/databases/{DatabaseName}/workspace/queryDefs”
query_response = requests.post(query_url,headers=headers1,data=json.dumps(query_data))
query_response.raise_for_status()
query_out = query_response.json()
query_dbid = query_out[‘dbId’]
6. クエリ定義の実行と結果セットの構築
前のステップで Query Dbid を受け取ったので、これを使ってクエリの実行と結果セットの構築を行う必要があります。これらの操作はいずれも ResultSets API で行います。使用する HTTP リクエストは POST です。この目的のために、次のエンドポイントを使用します。/ccmweb/rest/repos/repositoryname/databases/databasename/workspace/queryDefsquerydbid/resultsets。使用するヘッダーは、前のステップと同じです。
期待されるヘッダーは ‘Content-Type’: “application/json”,
Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJhZG1pbiIsInJlcG8iOiIxMC4wLjAiLCJleHAiOjE1NzM2NjE5NDUsImlhdCI6MTU3MzU3NTU0NSwiZGIiOiJTQU1QTCJ9.Lgdk9gPm6mFFGEnr6mRt7Vrq-nTnlP86ARKc16bP4syeTIvKQ55JX5r6aFXVC20xC2NwsjqbvAhd2f1r2PiIUA
このAPIでは、ボディデータの受け入れが必須となっています。もし特定のパラメータがない場合は、以下のように空の json を渡すことができます。
query_exec_data={
}
これ以外にも、URL、データ、ヘッダーが requests.get 関数に渡されます。いつものように、ここでも raise_for_status、json.dumps、.json の各関数を使います。出力結果から、次のAPIリクエストに渡すための「result_set_id」が得られることを期待しています。
query_exec_url = f”https://servername:8190/ccmweb/rest/repos/{RepositoryName}/databases/{DatabaseName}/workspace/queryDefs/{Querydbid}/resultsets”
query_exec_data={
}
query_exec_response=requests.post(query_exec_url,headers=headers1,data=json.dumps(query_exec_data))
query_exec_response.raise_for_status()
query_exec_results = query_exec_response.json()
resultset_id = query_exec_results[‘result_set_id’]
7. クエリの結果セットのユーザーへの表示
いよいよ結果セットをユーザーに表示します。これには、ResultSet API を使用し、エンドポイントとして /ccmweb/rest/repos/repositoryname/databases/databasename/workspace/queryDefs/querydbid/resultsets/resultsetid を指定します。前のステップの出力としてresultsetidを取得しました。HTTPリクエストはPOSTです。パラメータとしてURLとヘッダを指定するだけです。
期待されるヘッダは ‘Content-Type’: “application/json”,
Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJhZG1pbiIsInJlcG8iOiIxMC4wLjAiLCJleHAiOjE1NzM2NjE5NDUsImlhdCI6MTU3MzU3NTU0NSwiZGIiOiJTQU1QTCJ9.Lgdk9gPm6mFFGEnr6mRt7Vrq-nTnlP86ARKc16bP4syeTIvKQ55JX5r6aFXVC20xC2NwsjqbvAhd2f1r2PiIUA
Python Prettytableパッケージを使って、結果を表形式で表示します。結果セットの出力は、辞書形式で提供されます。そこから行の値を取得して、必要な値をPythonのリストとして抽出します。クエリ構成データでは、表示フィールドにHeadlineというフィールドのみを要求しましたが、出力にはデフォルトでdisplayNameが含まれており、これはレコードのID以外の何物でもありません。
result_set_url = f”https://servername:8190/ccmweb/rest/repos/{RepositoryName}/databases/{DatabaseName}/workspace/queryDefs/{Querydbid}/resultsets/{Resultsetid}”
result_set_response = requests.get(result_set_url,headers=headers1)
result_set_response.raise_for_status()
resultset_results = result_set_response.json()
second_final = resultset_results[‘rows’]
headline_value = []
id_value = []
for i in second_final:
headline_value.append(i[‘values’])
id_value.append(i[‘displayName’])
x.add_column(“ID”,id_value)
x.add_column(“Headline”,headline_value)
print(x)
8. クエリ定義の削除
次の作業は、作成したクエリを削除して、スクリプトを実行するたびに新しいクエリが作成されるように、Compass のデータベースに表示されないようにすることです。これには QueryDef API を使用し、エンドポイントを /ccmweb/rest/repos/reposittoryname/databases/databasename/workspace/queryDefs/querydbid とします。このためのHTTPリクエストはDELETEです。パラメータとしてurlとheadersを受け取ります。
期待されるヘッダーは ‘Content-Type’: “application/json”,
Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJhZG1pbiIsInJlcG8iOiIxMC4wLjAiLCJleHAiOjE1NzM2NjE5NDUsImlhdCI6MTU3MzU3NTU0NSwiZGIiOiJTQU1QTCJ9.Lgdk9gPm6mFFGEnr6mRt7Vrq-nTnlP86ARKc16bP4syeTIvKQ55JX5r6aFXVC20xC2NwsjqbvAhd2f1r2PiIUA
これまでのAPIリクエストで使われていた通常の機能とは別に、今回の違いは、何の出力も受け取らないということです。この場合、クエリが正常に削除されたかどうかをどうやって知ることができるでしょうか?それには、HTTPステータスコードを利用します。通常、HTTPレスポンスコードが200の範囲にあれば、リクエストが成功したことを意味します。そこで、HTTPレスポンスからステータスコードを取得するために、response.status_code関数が必要になります。これを条件文に渡すことで、クエリの削除が成功したかどうかを検証することができます。
remove_query_url = f”https://servername:8190/ccmweb/rest/repos/(RepositoryName}/databases/{DatabaseName}/workspace/queryDefs/{Querydbid}”
remove_query_response = requests.delete(remove_query_url,headers=headers1)
remove_query_response.raise_for_status()
remove_query_final_response = str(remove_query_response.status_code)
if remove_query_final_response.startswith(’20’):
print(“\nRemoving Query Successful”)
else:
print(“\nRemoving query failed! Please manually remove”)
9. CCM REST サーバーからのログオフ
クエリの出力をユーザーに表示することができたので、意図したタスクはすべて完了しました。あとは、セッションを蓄積してサーバに負荷をかけないようにするために、サーバからログオフするだけです。この目的のために、Authenticate APIを使用し、エンドポイントを/ccmweb/rest/authenticate/logoff とします。HTTPリクエストはPOSTです。先ほどのAPIリクエストと同様に、パラメータとしてURLとヘッダーのみを受け取ります。前のステップで行ったように、ログアウトが成功したかどうかを知るための出力はありませんので、ステータスコードも調べます。
期待されるヘッダーは 'Content-Type': "application/json",
Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJhZG1pbiIsInJlcG8iOiIxMC4wLjAiLCJleHAiOjE1NzM2NjE5NDUsImlhdCI6MTU3MzU3NTU0NSwiZGIiOiJTQU1QTCJ9.Lgdk9gPm6mFFGEnr6mRt7Vrq-nTnlP86ARKc16bP4syeTIvKQ55JX5r6aFXVC20xC2NwsjqbvAhd2f1r2PiIUA
logout_url=”https://servername:8190/ccmweb/rest/authenticate/logoff”
logout_response = requests.post(logout_url,headers=headers1)
logout_response.raise_for_status()
logout_final_response = str(logout_response.status_code)
if logout_final_response.startswith(’20’):
print(“\nLogout Successful”)
else:
print(“\nLogout Failed!”)
スクリプトの完全な出力
スクリプトの完全な出力は以下の通りです。システム内のリポジトリの一覧が表示されます。RESTサーバへの認証のために、ユーザ名、パスワード、データベースを入力する必要があります。
次に、ユーザが所有するレコードをリストアップするためのクエリを作成するために親ディレクトリを見つけます。レコードを作成して表示した後、クエリを削除してRESTサーバーからログアウトし、途中でエラーが発生した場合は報告します。
The repositories available on this server are
———————————–
CadenceTest RestAPIDemo
Authenticating to Compass Rest API server!
Enter Repository Name : RestAPIDemo
Enter your username : admin
Enter your password :
Enter db name : RESTD
Listing the Databases for the repository RestAPIDemo
The database name(s) are as follows
RESTD
restn
Building a Query to display records assigned to you
Enter Database name to build query : RESTD
Executing the Query
Displaying the Result Set
+—————+———————————–+
| ID | Headline |
+—————+———————————–+
| RESTD00000041 | [‘Testing RestAPI Demo Record 1’] |
| RESTD00000042 | [‘Testing RestAPI Demo Record 2’] |
+—————+———————————–+
Removing the Query
Removing Query Successful
Logging off
Logout Successful
結論
これで、COMPASS HTTP REST APIの使用を実演するための簡単なスクリプトを作成するという、我々がやろうとしたことは達成されました。これが、HCL Compassのデータを使ったより複雑なアプリケーションやインテグレーションの開発に役立つことを期待しています。
参考文献
HCL Compass の eSignature パッケージ機能
2021/9/23 - 読み終える時間: 4 分
eSignature package feature in HCL Compass https://blog.hcltechsw.com/compass/esignature-package-feature-in-hcl-compass/
HCL Compass の eSignature パッケージ機能
2021年9月20日
著者: Garima Hans / HCL TECHNICAL SPECIALIST

eSignatureとは?
電子署名(e-signature)とは、署名者を識別するための信頼できる方法を提供し、その人を電子文書の内容に拘束する電子的手段のことです。
なぜeSignatureが重要なのか?
電子署名は、コンパスの問題を解決するために、ユーザー認証とアクティビティの追跡を提供することで、データ・セキュリティの向上に役立ちます。 例えば、電子署名は、Compass環境を米国FDAに準拠させるために必要となる場合があります。
- すべてのレコードタイプにアクセスするためのユーザー認証を、各移行や変更の前に実施できます。
- 承認記録の承認/拒否時に電子署名を要求することをサポートします。
- トランジションの履歴とその作成者を専用パネルに表示します。
このような仕組みになっています。 あるレコードタイプにeSignatureパッケージを適用する。 そのレコードタイプのレコードには、eSignatureフィールドの新しいタブが含まれます。ユーザー名」「パスワード」「署名ログ」「Is Current」です。署名が必要な場合、ユーザー名とパスワードは必須フィールドとなり、そうでない場合は読み取り専用となります。
eSignatureパッケージはどのように適用できるのか
パッケージを適用できるのは、スキーマ管理者権限を持つユーザーまたはスーパーユーザー/コンパス管理者のみです。Compass管理ツールがインストールされているマシンから適用する必要があります。
- HCL Compass Designerを起動します。
- eSignatureパッケージを適用したいスキーマリポジトリに接続します。
- スキーマバージョンを右クリックし、パッケージの適用をクリックします。
- 適用する eSignature パッケージとそのバージョンを選択します。
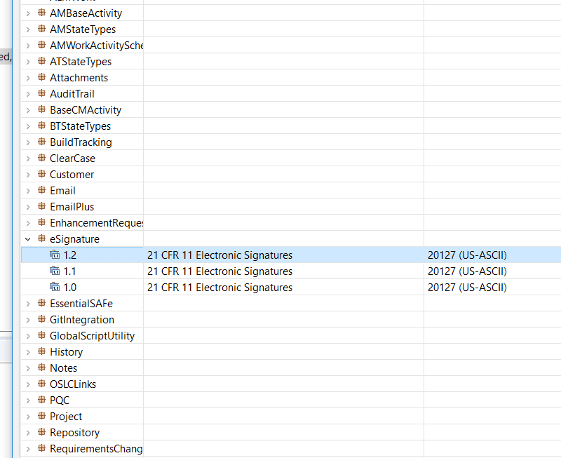
- 有効にしたいレコードタイプを選択します。
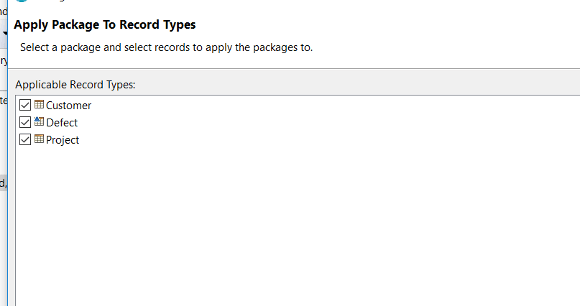
-
完了をクリックして、選択したパッケージをインストールする。
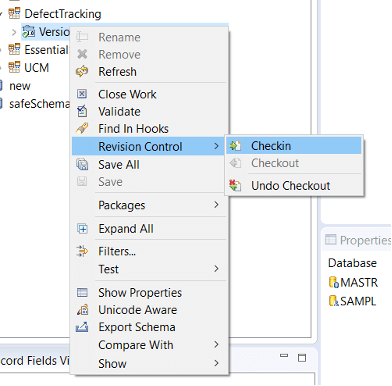
-
インストールが完了したら、最新のスキーマバージョンの変更を確認して、ユーザーDBをアップグレードする必要があります。この作業は元に戻すことができませんので、DBA と共にバックアップを取ることを忘れないでください。
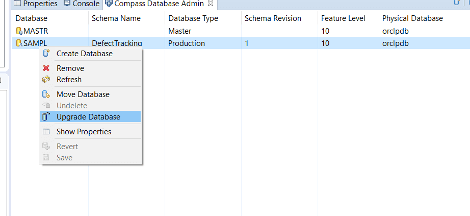
WebUIでレコードタイプにeSignatureを設定する
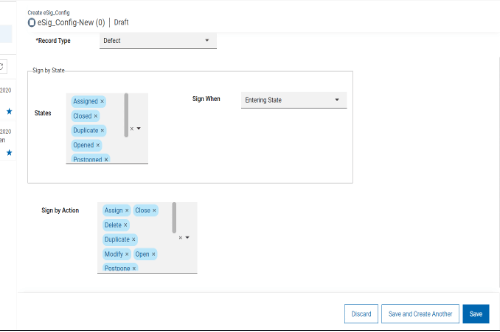
次のステップは、CompassのWebUIで行います。 あなた(または指定されたユーザー)は、選択したレコードタイプとデジタル署名を取得するアクションのためにeSig_Configを作成する権限を持っている必要があります。必要なオプションを選択し、保存をクリックします。
eSig_Configレコードには、署名するレコードタイプを選択するためのフィールドと、そのタイプのレコードがいつ署名されるかを示すために使用する2つのオプションが用意されています。ステート」と「アクション」です。レコード タイプがステートフルの場合は、State と Action の両方のオプションが使用できます。レコードタイプがステートレスの場合は、アクションのみが利用可能です。レコード タイプを変更すると、ステートとアクションの選択はクリアされます。
eSig_Config レコードに対してアクションベースの基準とステートベースの基準の両方を選択した場合、指定したタイプのレコードがいずれかの基準を満たす場合には、署名が必要となります。
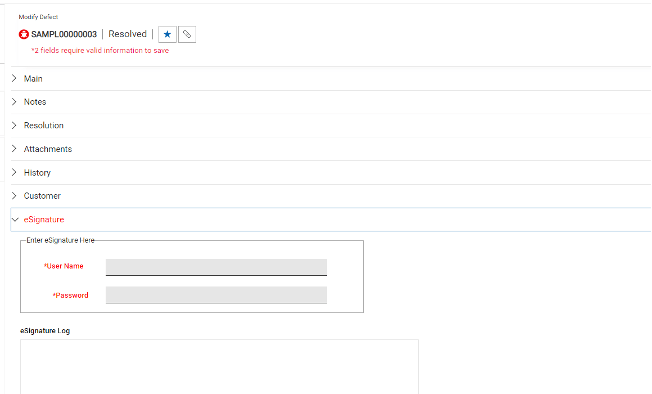
署名が必要な場合、ここで入力されたユーザー名とパスワードは、HCL Compass環境へのログインに使用されたユーザー名とパスワードと比較されます。アイデンティティが一致した場合、変更が受け入れられ、署名が記録されます。IDが一致しない場合は、エラーメッセージが表示され、データベースへの変更は行われません。
セットアップが完了すると、誰かが既存のレコードや新しいレコードを変更した場合、変更を保存するためにeSignatureのユーザー名とパスワードのフィールドが必須となります。
eSignature Logに表示される情報は以下の通りです。
- 記録に署名した人のユーザー名。
- ユーザーの印刷名
- ユーザーのグループ・メンバーシップ
- 実行中のアクション。
- レコードの最終状態。
- アクションのタイムスタンプ。
署名は、署名が適用されてからレコードが変更されていない場合にのみ有効です。読み取り専用のフィールドIs Currentには、レコードへの最後の変更に署名が含まれている場合は値「True」が、そうでない場合は値「False」が格納されます。
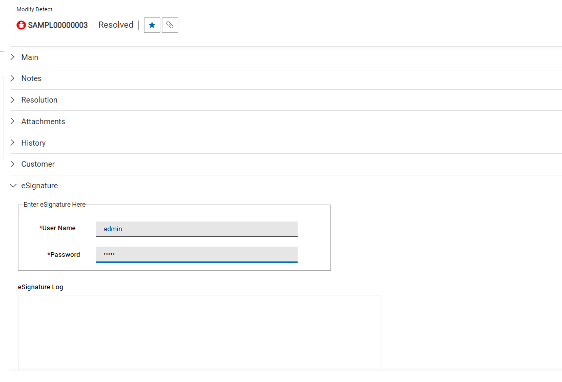
eSignature」タブには、レコードの署名履歴を表示するフィールド「eSignature Log」があります。このフィールドには、署名が行われた変更のみが含まれます。
eSigログはカスタマイズも可能です。詳しいカスタマイズ方法については、https://help.hcltechsw.com/compass/2.0.2/com.hcl.compass.doc/webhelp/oxy_ex-1/com.ibm.rational.clearquest.schema.ec.doc/topics/sch_pkgs/c_customize_esig.html を参照してください。
あなたの組織では、スキーマにeSigパッケージのような同様の要件がありますか?下記のディスカッションにご参加ください。
DevOps India Summit 2021 をふりかえって
2021/9/2 - 読み終える時間: 2 分
DevOps India Summit 2021 Recap の翻訳版です。
DevOps India Summit 2021 Recap
2021年9月1日
著者: Bhavani Sidharth / DevOps Sales, HCL
DevOps India Summit(DOIS)は、南アジア最大のDevOpsイベントとして注目されています。インドの開発者数は全世界の2700万人のうち600万人と非常に多く、このイベントはソフトウェア開発業界において非常に重要な意味を持っています。今年の8月27日と28日に開催されたDOISでは、2日間に渡って、スピーカーセッション、パラレルトーク、ディスカッションが行われ、世界中の人々が考えを共有しました。
今回のサミットではパンデミックに焦点が当てられておらず、「前例のない時代」「在宅勤務」「セキュリティと事業継続」「運用上の課題」「パンデミックがIT業界の働き方に与える影響」などの議論はほとんどありませんでした。まるで、業界が新しい常識に慣れてしまい、それが「いつものこと」になっているかのようでした。では、世界最大の開発者コミュニティにとって、「いつものこと」とはどのようなものなのでしょうか。以下に、複数のソートリーダーから集めたいくつかのテーマを紹介します。
DevOpsは持続可能性の一翼を担うことになる
環境に配慮した開発や、今後数年間に組織が行う選択が、ソフトウェアの構築方法を左右することになるでしょう。持続可能性に関しては、すべての人が関わっているのに、なぜ開発者は不可決なのか?
環境に優しいソフトウェア開発とは何でしょうか?それは、PythonかC言語か、GCPかAWSか、自動化か手動化かといった選択の問題です。開発者は環境に配慮した選択を求められ、組織全体の二酸化炭素排出量の目標に合わせることを求められるでしょう。
誰もがお客様に責任を持つ
アマゾンで働き、毎月リーダーシップミーティングに同席している友人によると、これらのミーティングで常に問われるのは、「それはどのようにお客様の役に立つのか」ということだそうです。すべてのアイデア、すべての製品、すべての新しい考えは、この1つの質問に答える必要があります。長い間、開発者やデザイナーは自由を必要とする創造的な人々であり、創造はほとんどが孤立して行われていました。
Value Stream Management(VSM)は、私たちが見ているように、「Day 2 DevOps」、つまり多くの組織が今取り組んでいるDevOpsの進化の次の段階です。開発者はもちろん、営業やマーケティング、さらには財務や人事を含む開発・運用チームは、すべて顧客に答えを出すことになります。指標があること、可視性があること、システムに効率性があること、レポートがあること、そしてスピードがあることは当たり前のことです。しかし、これらすべてがどのようにしてビジネス価値をもたらすのでしょうか?チームはアジャイルでテストを自動化し、本番へのデプロイを高速化していますが、それがNPSの向上にどうつながるのでしょうか。しかし、それがNPSの向上にどう結びつくのでしょうか、マーケットシェアの拡大にどう結びつくのでしょうか。顧客サービスの迅速化にどう結びつくのか?
それは、ループを完成させ、データポイント間の点をつなげることです(これはまさに HCL Accelerate が行っていることです)。メトリクスは十分ではありません。顧客により良いサービスを提供するために新しいソフトウェアの開発に投資している CFO/CEO にとって、ループは閉じなければなりません。
オートヒーリングがガバナンスをサポート
障害を検出して報告するだけでは十分ではありません。不具合は自動的に治癒される必要があります。これは、テスト、デプロイメント、ソースコード管理、バージョン管理、プランニングなどに見られます。すべての製品は、自動修正する生来の知能を持ち、AI/MLが混入され、同じプラットフォーム上にある必要があります。さらに、開発と運用のプロセスは、修正が依存関係にどのような影響を与えるかを確認できるように、エンドツーエンドの可視性を持つ必要があります。当社のDevOpsソリューションは、問題の検出、修正、防止のための機能を提供し、ソフトウェア・デリバリー・パイプライン全体のガバナンスを向上させます。 オープンソースの役割
小規模なチームであれば、無料のツールを使ってすぐにスタートを切ることができますが、企業レベルではセキュリティとスケールがより重要になります。しかし、どちらか一方だけを選択する必要はありません。オープンソースであるかどうかに関わらず、開発者が自分の好きなツールを使い続け、その上にセキュリティ、テスト、バリューストリームマネジメントなどのエンタープライズツールのエコシステムを構築することができます。私たちのソリューションは、「引き裂いて置き換える」という考え方ではなく、多様なツールチェーンにエンタープライズレベルのセキュリティ、スケーリング、分析機能を追加するものです。
DevOps India Summitは、複数のソートリーダーやイノベーターから、DevOpsの過去、現在、未来について話を聞くことができる興味深い2日間でした。カンファレンスに参加された方は、ご自身の感想をコメントでお聞かせください。
テクノロジーの統合: 次世代のHCL OneTest
2021/8/23 - 読み終える時間: ~1 分
Technology Integration: The Next Generation of HCL OneTest の翻訳版です。
テクノロジーの統合: 次世代のHCL OneTest
2021年8月23日
著者: Nabeel Jaitapker / Product Marketing Lead, HCL Software

HCL OneTest の最新リリースで最もクールな機能の一つは、様々なタイプの技術と統合できることです。
例えば、参照整合性を拡張してカスタムリレーションシップを追加したり、バージョン10.2でDDLを生成したりすることができます。
さらに、InstallAnywhere は、Installation Manager でサポートされている HCL OneTest 製品ファミリーの 14 言語すべてをサポートしています。これにより、翻訳されたインストールパッケージのおかげで、フレンドリーなインストール体験が保証されます。
HCL OneTest Server (GA)におけるHTTPトランスポートのサービス仮想化
Webサービス(SOAP、REST、HTTP)やIBM MQベースのアプリケーションをサポートし、サーバー上で仮想化することで、仮想サービスのスケーリングを簡素化し、デバッグを容易にし、新しいシステムモデル・ビューで使用状況を可視化します。
コントラクトテストのサポート: コンシューマ・ドリブン
APIが成熟するにつれ、提供者と消費者の間にはかなりの摩擦が生じます。- APIの仕様を少し変更しただけで、消費者の行動がおかしくなり、下流で複数の問題が発生する可能性があります。コントラクトテストにより、APIプロバイダとコンシューマは、API仕様の変更を迅速かつ容易に検証し、導入時の問題を回避することができます。
次世代のHCL OneTestについて説明したオンデマンドのウェビナーをご覧ください。