HCL AppScan: バイトコード/コンパイルとソースコードスキャニングの比較
2022/3/31 - 読み終える時間: 3 分
Bytecode/Compiled vs Source Code Scanning の翻訳版です。
HCL AppScan: バイトコード/コンパイルとソースコードスキャニングの比較
2022年3月30日
著者: Florin Coada / HCL AppScan Product Management Team
AppScanのここ数回のリリースで、静的解析機能においてJava、.Net、C/C++のソースコードスキャニングのサポートを発表したことにお気づきでしょうか。この2つのアプローチには大きな違いがあり、それぞれ異なるユースケースに最適なものとなっています。
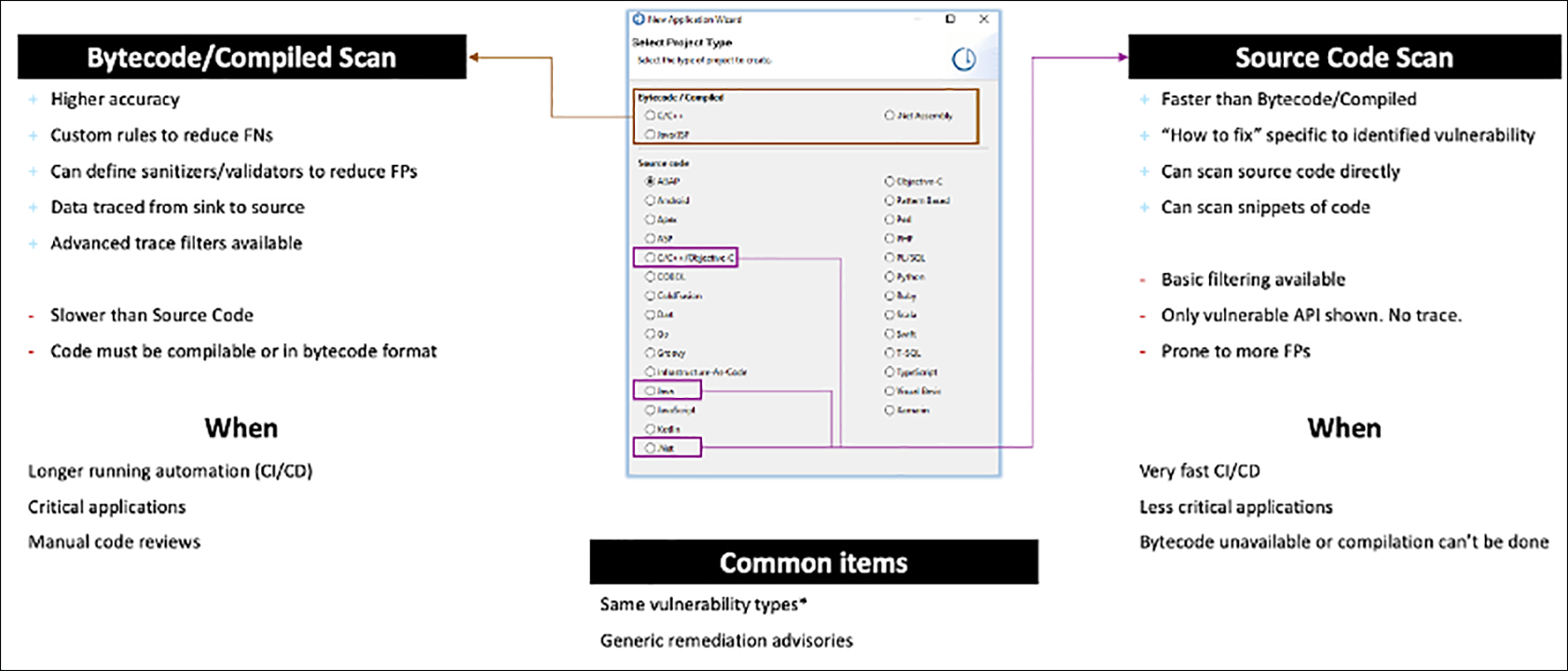
バイトコード/コンパイル済みコードとソースコード。
これまでAppScanは、Java、.Net、C/C++のデータフロー解析を行ってきました。この分析により、アプリケーションを通過するデータフローのマップが生成されます。エンジンは、Javaバイトコード、.NET MSILを読み込み、C/C++でのコンパイルをエミュレートすることによって、このマップを構築します。次に、マップを解析して、コードの制御不能な入口(ソース)と出口(シンク)を見つけます。解析の結果、シンクへの経路が存在するソースが見つかり、データを浄化するルーチンが見つからなければ、その発見が行われる。
精度
バイトコード/コンパイルスキャン
このようなバイトコード/コンパイルスキャンアプローチの主な利点は、著しく高い精度の結果を得られることです。発見された内容は、ソースコード自体の中にある実際のデータフローを表しています。不正確な経路とは、ファイアウォールがリモートアクセスをブロックしているなど、他の緩和要因により、コードベース内の悪用可能な攻撃ベクトルを表していない経路や、多段攻撃の中間段階を表している経路が一般的です。さらにバイトコード解析は、より正確なソースからシンクへのルックアップを実現するため、非常に正確なクラス識別を提供します。
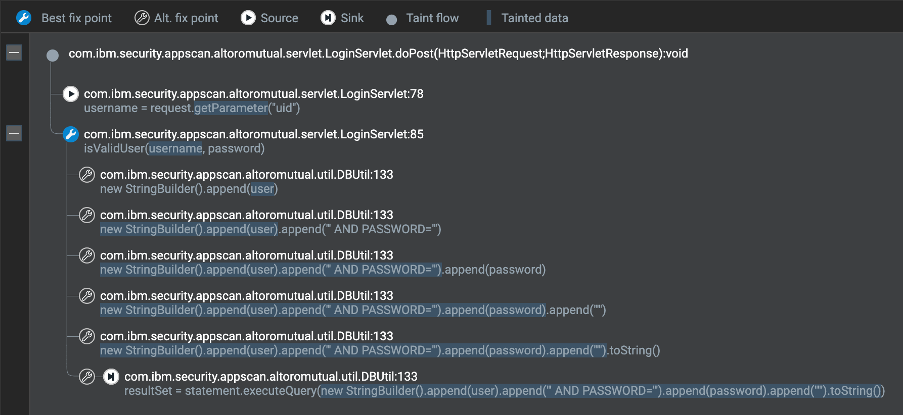
例えば、ユーザーの入力を取得し、そのデータをSQLデータベースのクエリに送信するアプリケーションを考えてみましょう。これは、ハッカーがSQLインジェクション攻撃に使用できるフローであり、攻撃対象であるWebが非常に悪用されやすいことがわかります。バイトコード/コンパイルスキャナは、この例のように、ユーザー入力をSQLクエリで安全に使用できるようにする既知のサニタイザやバリデーターを探せます。サニタイザーがない場合、この例では、開発者が修正する必要のある非常に現実的な問題を示す発見が生成されます。発見内容は、修正グループにまとめられ、最適な修正箇所が示されることもある。これは、コード内のこの場所に修正を実装することで、複数の問題を一度に解決できることを意味する。
ソースコードスキャン
ソースコードスキャン側では、やっていることが少し違います。データフロー解析は行いませんし、データがアプリケーション全体をどのように通過しているかを見ようとすることもありません。データフローを実行するのは、非常に計算コストがかかります。その代わりに、ソースコードやソースコードの断片を直接見て、そのコードが既知の危険なパターンを使っているかどうかを理解しようとします。上の例では、特定のSQLステートメントを含む文字列変数を見て、SQLクエリにデータを変数で連結していないかどうかを確認します。ユーザー入力を連結したSQLクエリの生成は常に避けた方がよいでしょう。これはSQLインジェクションのレシピです。ソースコードスキャナーは、これを脆弱性として強調します。この例における2つのアプローチの主な違いは、データフローエンジンが、連結された変数がソースから来たものか、あるいはユーザーが提供したデータである可能性があるかを判断し、そうでなければ発見を行わないということです。ソースコードスキャンでは、そのような能力はありません。発見された場合、開発者は、連結された変数が潜在的に危険なソースからのものであるかどうかをソースコードを通して確認する必要があります。ソースに対するチェックがないため、ノイズとなる発見が増える可能性がありますが、ソースコードスキャナーにも多くのチェックがあり、既知のサニタイザーが使用されていれば、発見を取り除けます。ノイズの発見があったとしても、多くの場合、危険な慣行や脆弱性が示されるため、パラメータ化されたクエリなど、別のアプローチが必要になる可能性があります。
このアプローチの利点は、ここから得られるすべての発見が、非常にAPIやパターンに特化したものになることです。を説明するために、より的を絞った情報を提示することができることです。
このアプローチの利点は、ここから得られるすべての知見が、非常にAPIやパターンに特化したものになることです。その結果、問題を説明し、より安全な代替アプローチを推奨するための、より的を射た情報を提示できます。これは、セキュリティ欠陥を処理しようとする開発者に、即座に消費可能な価値を提供します。

フィルタリング結果
バイトコード/コンパイルスキャン
このスキャンタイプはより正確ですが、誤検出の数をさらに減らすために、追加のルールを作成できます。すべての静的解析ツールは、標準的なフレームワークについては知っていますが、自社で構築した独自のフレームワークについては知らないはずです。そのため、独自のフレームワークを扱う場合、データのソースが何であるかは分からない。あるいは、潜在的なシンクについて知らないかもしれない。ソースとシンクに関する知識がないため、偽陰性が生まれるのです。これらはスキャナーでは検出できない本当の脆弱性です。データフローについては、これらを検出する自動化された方法がありますが、手動でルールを作成することで、非常に正確で脆弱性の検出率を向上させるられます。同時に、独自のサニタイザーやバリデーターを定義することで、スキャンの精度を向上させられます。
さらに、取得した結果にはDataFlowが含まれ、アプリケーションの様々な部分がデータに触れていることが分かります。結果を調査し、サニタイザーやバリデーターを特定したら、この特定のパスは攻撃に対して脆弱ではない、と言うことができるのです。結果を見ると、ソースからシンクまでたどったデータとそのステップを分析できるため、高度なフィルターを作成できます。このトレースのプロパティに基づいて、特定の問題を隠したり、削除したりすることができるのです。また、異なるソース、シンク、APIによって物事をグループ化することも可能です。ひいては、アプリケーションが特定の攻撃に対して脆弱であるかどうかを迅速に分析する方法を提供します。
ソースコードスキャン
ソースコードスキャンの否定的な点、あるいは好ましくない点の1つは、フィルタリングが比較的基本的なものであることだ。トレースに関することはできませんし、アプリケーションのどの部分がコードをサニタイズしているかを理解するのに役立つような高度なフィルタリングを行うこともできません。そのようなフィルタを作成するために必要なデータを持っていないのです。深刻度、異なる脆弱性タイプ、ファイルなどの項目でフィルタリングできます。また、カスタムルールのオプションもありません。自社開発のフレームワークを使用している場合、そのフレームワークに対するセキュリティの判断は行いません。しかし、あなたのコードで危険な使われ方をしている一般的なフレームワークについては、お伝えできます。
このようにソースからシンクまでのデータ分析を行うオプションがなければ、このような技術は誤検出を起こしやすくなります。例えば、SQL文の中で何かが連結されているのを見たら、SQLインジェクションの可能性があるとして警告を出します。しかし、この何かのデータがどこから来たのか分からないため、危険ではないことを伝えている可能性があります。
使用例
バイトコード/コンパイルスキャン
ソースコードスキャンと比較すると、動作が遅くなるというマイナス面もあります。この種の解析は、多くの計算能力を必要とします。また、コードを効率的に解析できるように、コードがバイトコード形式かコンパイル可能な状態であることが必要です。
ソースコードスキャンよりも時間がかかるので、大規模なアプリケーションの夜間スキャンや手動コードレビューに適しています。この技術は、サイズが小さい最新のマイクロサービスベースのアプリケーションのDevOpsパイプラインの一部として使用できます。
また、DataFlowは、できるだけ多くの脆弱性を早期に正確に発見するために、重要なアプリケーションに推奨されています。
以下のような用途に向いています。
- 大規模プロジェクトでの一晩のスキャン
- マイクロサービス向け自動化パイプライン
- 手動コードレビュー
ソースコードスキャン
ここまで列挙した内容からすると、バイトコード/コンパイルスキャンに軍配が上がりそうな気がしますが、そうではありません。ソースコード・スキャンは、特定のユースケースにおいて非常に強力な効果を発揮することができる。ソースコードスキャンを使うのに最適な場所は、リリースサイクルが非常に速いアプリケーションです。非常に速いリリースを行っていて、素早くスキャンして情報を得たい場合は、ソースコード・スキャンの方が良い選択肢となります。コードのスニペットや最近触ったファイルまでスキャンしてくれるんだ。バイトコードやコンパイル済みのスキャンよりもはるかに速く、検出した内容をすべて教えてくれる。あまり重要でないアプリケーションに使用するとよいでしょう。設定せずにクイックスキャンを実行し、重要な問題を見て、仕事を続けられます。
また、バイトコードがなければ、アプリケーションをコンパイルすることができませんが、これも良いシナリオの一つです。世の中にはたくさんのフレームワークがあり、コードを構築する方法もさまざまです。私たちは最も一般的なものをサポートしていますが、特定のフレームワークをスキャンできないエッジケースは常に存在します。ソースコードスキャンを使えば、コードを読み込むだけで、データフロー解析に必要なグラフの作成を気にすることなく、取り組むことができるようになります。
このような場合に有効です。
- リリースサイクルが非常に速いアプリケーション
- アプリケーションの迅速なチェック
- コンパイルできないアプリケーションやバイトコードがない場合など
共通点
両者に共通するのは、同じ種類の脆弱性を発見することです。問題の数、場所、全体的な情報などは異なるかもしれませんが、どちらのスキャナーも同じ種類の問題を特定し、多くの場合、まったく同じ問題を特定します。注意すべき点は、両者が同じものを見つけるとはいえ、同じものを見つけるということです。結果は同じではありません。データフローでSQLインジェクションを発見し、ソースコードスキャナーで同じSQLインジェクションを発見した場合、ツールによって異なる所見として扱われることになります。一度、一つのスキャナー・タイプで始めたら、同じものを使い続けることをお勧めします。
同じ一般的な修正アドバイザーを利用することができるようになります。具体的な問題への取り組み方、潜在的な影響、適用すべき改善策を読むことができます。両方のスキャナーの結果から、これらの情報を得られます。ソースコードは、ほとんどの場合、特定の API をどのように扱うかについて直接的な情報を与えてくれる。